











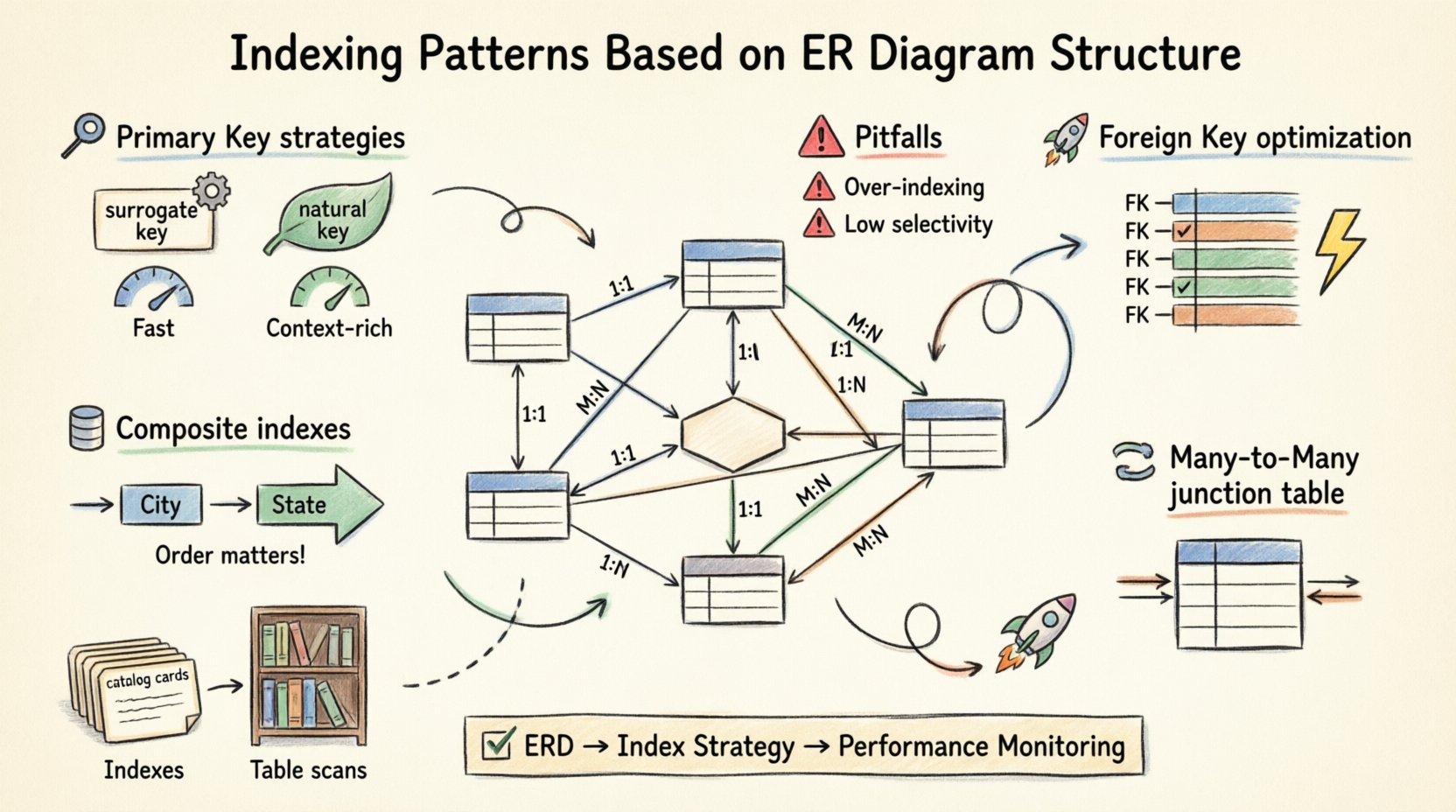
Projektowanie solidnej bazy danych zaczyna się dawno przed uruchomieniem pierwszego zapytania. Zaczyna się od projektu: diagramu relacji encji (ERD). 📐 Choć wielu programistów skupia się na tworzeniu tabel i typach kolumn, prawdziwy silnik wydajności tkwi w tym, jak indeksy dopasowują się do modelu danych. Indeksowanie to nie tylko ustawienie konfiguracyjne; jest fizycznym odzwierciedleniem relacji logicznych.
Kiedy strukturyzujesz swój ERD, definiujesz liczność i połączenia danych. Te decyzje strukturalne wyznaczają najefektywniejsze strategie indeksowania. Relacja jeden do jednego wymaga innego podejścia niż połączenie wiele do wielu. Ignorowanie tych subtelności często prowadzi do wolnych łączeń, nadmiernego I/O i fragmentacji pamięci. Ten przewodnik wyjaśnia, jak przekształcić swój ERD w wzorce indeksowania o wysokiej wydajności, nie zależnie od konkretnych narzędzi dostawcy.
🔑 Zrozumienie podstaw: ERD i indeksowanie
Diagram ERD to więcej niż pomoc wizualna; jest umową między logiką aplikacji a silnikiem przechowywania danych. Każda linia narysowana między encjami reprezentuje ograniczenie, które baza danych musi zastosować. Indeksy służą do przyspieszenia zastosowania tych ograniczeń oraz pobierania danych między nimi.
Wyobraź sobie warstwę przechowywania jako bibliotekę. Bez indeksu znalezienie książki wymaga przeszukania każdej półki (pełne przeszukiwanie tabeli). Indeks to karta katalogowa. Jednak niepoprawne umieszczenie kart katalogowych — na przykład według gatunku zamiast autora, gdy autorzy są głównym kluczem wyszukiwania — sprawia, że system staje się nieefektywny. Twój ERD mówi Ci, kim są autorzy i gatunki, oraz które relacje są najważniejsze.
Kluczowe kwestie do rozważenia to:
- Liczność: Kolumny o wysokiej liczności (unikalne wartości) najbardziej korzystają z indeksów.
- Częstotliwość łączeń: Tabele, które często łączy się ze sobą, wymagają specjalnego indeksowania kolumn kluczy obcych.
- Objętość zapisu: Każdy indeks dodaje narzut na operacje wstawiania i aktualizacji.
- Wzorce zapytań: Jak filtrować? Jak sortować? ERD wskazuje odpowiedź.
🏗️ Strategie indeksowania klucza podstawowego
Klucz podstawowy (PK) to fundament każdej tabeli. Gwarantuje unikalność i zapewnia mechanizm grupowania danych w przechowywaniu w wielu systemach. Dopasowanie indeksowania do definicji klucza podstawowego to pierwszy krok.
1. Klucze zastępcze vs. naturalne
Wybór między kluczem zastępczym (ID z automatycznym zwiększaniem) a kluczem naturalnym (np. adres e-mail lub numer ubezpieczenia społecznego) ma istotny wpływ na wydajność indeksu.
- Klucze zastępcze: Są idealne do grupowania. Są krótkie, monotonicznie rosnące i sekwencyjne. Minimalizują podziały stron i fragmentację podczas zapisu. 📈
- Klucze naturalne: Choć mają znaczenie semantyczne, mogą być długie, o zmiennej długości lub podatne na zmiany. Ich indeksowanie może prowadzić do większych rozmiarów indeksów i wolniejszych wyszukiwań w porównaniu do kluczy opartych na liczbach całkowitych.
2. Skutki indeksu kluczowego
W większości architektur klucz podstawowy definiuje indeks kluczowy. Oznacza to, że rzeczywiste wiersze danych są fizycznie przechowywane w kolejności klucza. Jeśli Twój ERD sugeruje, że zapytania często filtrowane są według określonej cechy naturalnej, możesz rozważyć ponowną definicję klucza podstawowego lub zaakceptować, że indeks kluczowy będzie zoptymalizowany pod jedną klasę zapytań, podczas gdy indeksy pomocnicze obsługują pozostałe.
🔗 Optymalizacja klucza obcego
Klucze obce (FK) definiują relacje między tabelami. Są najczęstszą przyczyną wąskich gardłów wydajności, jeśli pozostaną nieindeksowane. Gdy łączy się dwie tabele, silnik bazy danych musi dopasować wiersze na podstawie kolumny FK. Bez indeksu operacja ta degeneruje się do przeszukiwania zagnieżdżonego pętli, co jest obliczeniowo kosztowne dla dużych zestawów danych.
1. Indeksowanie kolumny klucza obcego
Zawsze twórz indeks na kolumnie klucza obcego w tabeli potomnej. Pozwala to silnikowi szybko znaleźć powiązane wiersze bez przeszukiwania całej tabeli.
| Przypadek | Wymóg indeksowania | Wpływ na wydajność |
|---|---|---|
| Jeden do wielu (Dziecko) | Indeks klucza obcego w tabeli dziecka | Zezwala na szybkie wyszukiwanie danych rodzica |
| Wiele do jednego (Rodzic) | Indeks klucza podstawowego w tabeli rodzica (zazwyczaj domyślny) | Standardowe zachowanie klucza podstawowego |
| Kaskadowe usuwanie | Indeks klucza obcego + klucza podstawowego rodzica | Zapobiega blokowaniu całej tabeli podczas usuwania |
2. Złożone klucze obce
Czasem relacja opiera się na wielu kolumnach (np. złożonym kluczu z tabeli rodzica). W takim przypadku należy utworzyć złożony indeks w tabeli dziecka, który odpowiada kolejności i kolumnom klucza rodzica. Niezgodność kolejności kolumn w indeksie może sprawić, że będzie on bezużyteczny dla operacji połączeń.
🔀 Obsługa relacji wiele do wielu
Relacje wiele do wielu (M:N) są rozwiązywane za pomocą tabeli pośredniej. Tabela ta zawiera klucze obce wskazujące na obie tabele rodzicielskie. Strategia indeksowania tutaj ma kluczowe znaczenie dla wydajności.
Rozważ sytuację, w którejStudenci zapisują się na Kursy. Tabela pośrednia łączy je ze sobą. Aby znaleźć wszystkie kursy dla studenta, należy skutecznie zapytać tabelę pośrednią.
- Indeksowanie dwukierunkowe: Powinienś indeksować obie kolumny klucza obcego niezależnie. Pozwala to na zapytanie relacji z dowolnego końca (Student → Kursy lub Kurs → Studenci) bez pełnego skanowania.
- Indeksowanie złożone: Jeśli Twoje zapytania zawsze pobierają kursy określonego studenta, złożony indeks na (ID_Studenta, ID_Kursu) jest bardziej wydajny niż dwa osobne indeksy. Pokrywa kryteria wyszukiwania w jednym przeszukaniu.
📊 Indeksy złożone i pokrywające
Nie wszystkie zapytania filtrowane są według jednej kolumny. Złożone zapytania często obejmują wiele warunków. To właśnie tutaj indeksy złożone odnoszą się najlepiej. Indeks złożony to pojedynczy indeks utworzony na wielu kolumnach.
1. Kolejność kolumn ma znaczenie
Kolejność kolumn w indeksie złożonym nie jest dowolna. Silnik bazy danych może wykorzystać indeks tylko do momentu, gdy warunki równości się kończą. Na przykład, jeśli indeksujesz (Miasto, Województwo), zapytanie filtrowane według Miasta będzie używać indeksu. Zapytanie filtrowane wyłącznie według Województwa prawdopodobnie go zignoruje.
2. Indeksy pokrywające
Indeks pokrywający zawiera wszystkie kolumny wymagane do spełnienia zapytania, w tym listę SELECT. Pozwala to bazie danych pobrać dane bezpośrednio z drzewa indeksu, bez dostępu do głównej tabeli (heap). To ogromna wygrana pod względem wydajności w operacjach o wysokim obciążeniu odczytu.
⚠️ Najczęstsze pułapki i najlepsze praktyki
Nawet przy idealnym ERD błędy w implementacji mogą pogarszać wydajność. Poniżej znajdują się typowe pułapki, które należy unikać podczas przekształcania struktury w przechowywanie danych.
- Zbyt dużo indeksów: Każdy indeks zużywa przestrzeń dyskową i spowalnia operacje zapisu. Indeksuj tylko kolumny, które są często wykonywane w zapytaniach lub używane do ograniczeń.
- Niska selektywność:Indeksowanie kolumny o niskiej liczbie unikalnych wartości (np. flagi logicznej „is_active”) często jest nieefektywne. Optymalizator może stwierdzić, że pełne skanowanie tabeli jest szybsze niż przeskakowanie do indeksu.
- Ignorowanie wartości NULL:Indeksy obsługują wartości NULL w różny sposób w zależności od silnika. Upewnij się, że logika zapytań uwzględnia sposób indeksowania wartości NULL w Twoim konkretnym środowisku.
- Fragmentacja:W czasie indeksy stają się fragmentowane. Regularna konserwacja jest wymagana, aby zachować optymalną wydajność.
🛠️ Monitorowanie wydajności i konserwacja
Gdy strategia indeksowania jest już zaimplementowana, monitorowanie jest niezbędne. Nie możesz optymalizować tego, czego nie mierzyłeś. Regularnie przeglądaj plany wykonania zapytań, aby sprawdzić, czy Twoje indeksy są wykorzystywane skutecznie.
1. Analizuj plany wykonania
Szukaj operacji takich jak „skanowanie indeksu” w porównaniu do „przeszukiwania indeksu”. Przeszukiwanie jest skuteczne; skanowanie nie jest. Jeśli widzisz pełne skanowanie tabel na dużych tabelach, ponownie przeanalizuj strategię indeksowania na podstawie rzeczywistych wzorców zapytań.
2. Śledź wykorzystanie indeksów
Czasem indeksy są tworzone, ale nigdy nie są używane. Są to niepotrzebne obciążenie. Regularnie audytuj statystyki wykorzystania indeksów, aby zidentyfikować nieużywane indeksy, które można usunąć, aby poprawić wydajność zapisu.
3. Rozważania dotyczące wzrostu danych
Wraz z rosnącą ilością danych rosną koszty konserwacji. Indeks, który działa dobrze przy 10 000 wierszach, może stać się węzłem zatkania przy 10 milionach wierszy. Przeglądaj ponownie wzorce indeksowania pochodzące z ERD wraz ze skalowaniem zbioru danych. Strategie podziału danych mogą również stać się konieczne w połączeniu z indeksowaniem.
🔄 Podsumowanie zgodności
Dostosowanie strategii indeksowania do struktury ERD to ciągły proces. Wymaga on zrozumienia relacji danych zdefiniowanych w Twoim projekcie i przekształcenia ich w optymalizacje przechowywania fizycznego.
- Klucze główne: Używaj do grupowania i zapewniania unikalności.
- Klucze obce: Indeksuj dla lepszej wydajności łączeń.
- Tabele pośrednie:Indeksowanie dwukierunkowe dla relacji M:N.
- Wzorce zapytań:Dostosuj indeksy złożone do konkretnych kolejności filtrów.
Uwzględniając integralność strukturalną Twojego ERD, budujesz bazę danych, która skaluje się płynnie. Unikasz typowych pułapek związane z nieplanowanym indeksowaniem i zapewnicasz, że Twoje dane pozostają dostępne i wydajne w miarę rozwoju aplikacji. Ta dyscyplinarna metoda gwarantuje, że baza danych wspiera Twoją logikę biznesową bez stawania się węzłem zatkania. 🚀