










Wraz z przyspieszaniem akumulacji danych architektura schematu bazy danych staje się kluczowym czynnikiem stabilności systemu. Gdy aplikacja przechodzi od operacji odczytu do obciążeń zapisu, standardowy diagram relacji encji (ERD) często wymaga istotnych zmian. Projektowanie z wysoką przepustowością wymaga więcej niż tylko dodawanie indeksów; wymaga fundamentalnej zmiany podejścia do struktury, łączenia i przechowywania danych. Ten przewodnik omawia konieczne zmiany architektoniczne, które są potrzebne, aby utrzymać wydajność pod presją, nie naruszając integralności danych.
Rozumienie obciążeń zapisu 📈
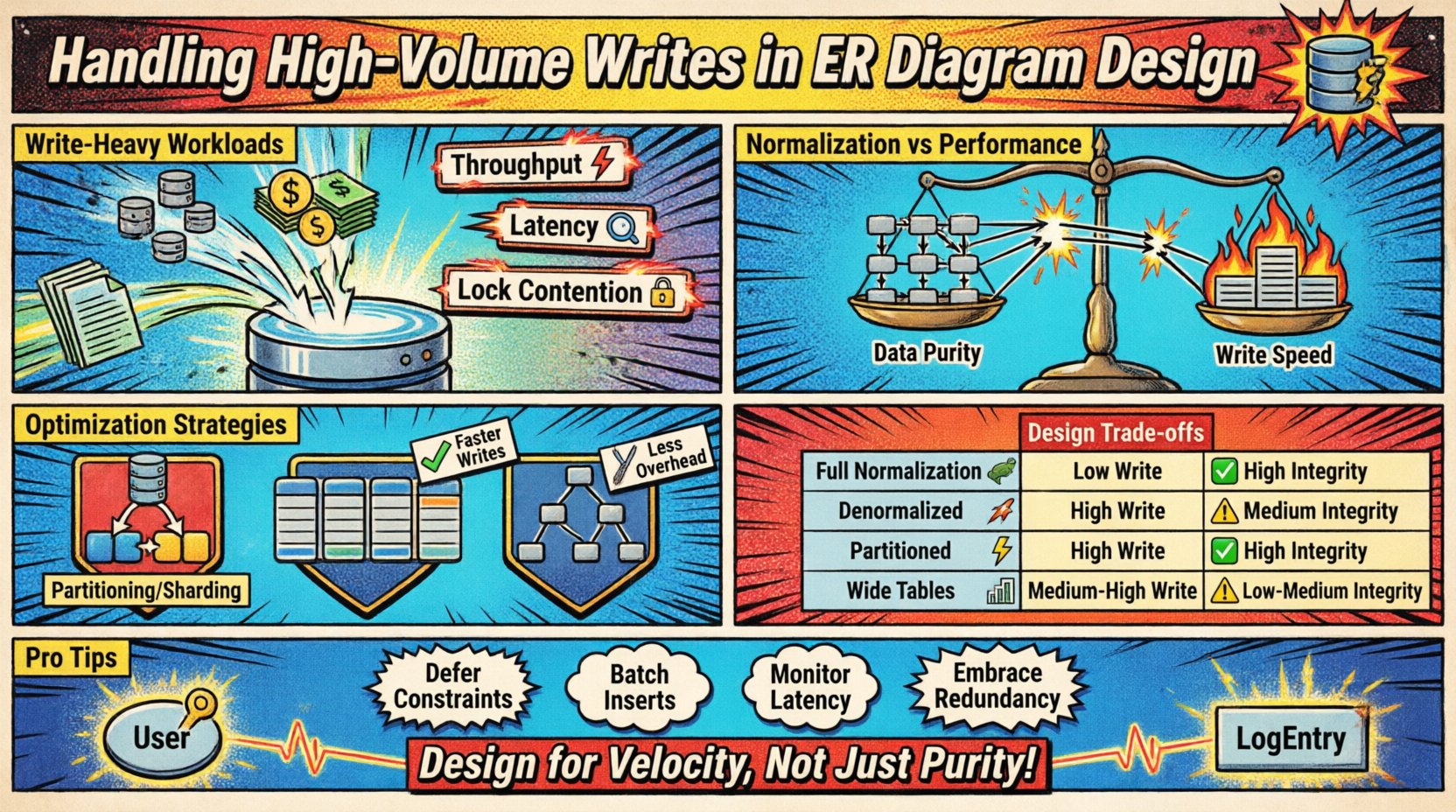
Scenariusze z dużą ilością zapisów występują, gdy tempo przychodzących danych przekracza pojemność standardowych technik normalizacji. Zdarza się to często w systemach logowania, strumieniach danych z czujników IoT, ledgerach transakcji finansowych lub platformach analizy w czasie rzeczywistym. Głównym wyzwaniem jest zrównoważenie szybkości wstawiania danych z wymogami spójności modelu.
- Przepustowość: Liczba operacji zapisu przetwarzanych na sekundę.
- Opóźnienie: Czas potrzebny na pomyślną trwałą persistencję rekordu.
- Konflikty blokad: Konkurencja o zasoby, gdy wiele procesów próbuje zmodyfikować te same dane.
Gdy te metryki pogarszają się, często schemat jest węzłem zawieszenia. Sztywny projekt zoptymalizowany pod złożone zapytania może się rozpaść pod ciężarem ciągłych aktualizacji. Dlatego początkowy ERD musi uwzględniać prędkość wprowadzania danych.
Normalizacja wobec wydajności – kompromisy ⚖️
Tradycyjny projekt bazy danych zachęca do normalizacji (1NF, 2NF, 3NF), aby zmniejszyć nadmiarowość. Choć oszczędza to miejsce w pamięci i zapewnia spójność, wprowadza ona narzut podczas operacji zapisu. Każda relacja klucza obcego wymaga wyszukania i sprawdzenia połączenia w celu zachowania integralności referencyjnej.
W środowisku o dużej objętości te sprawdzenia stają się kosztowne. Rozważ skutki relacji wiele do wielu podczas zdarzenia zapisu:
- Tabela główna musi zostać zaktualizowana.
- Tabela pośrednia musi wstawić nowy wiersz.
- Druga tabela musi zweryfikować relację.
- Dzienniki transakcji muszą zapisywać wszystkie zmiany.
Każdy krok dodaje operacje wejścia/wyjścia dysku i cykle procesora. Aby obsłużyć duże obciążenia zapisu, projektanci często łagodzą zasady normalizacji. Proces ten polega na akceptowaniu nadmiarowości danych w celu zmniejszenia liczby operacji zapisu wymaganych do przechowania jednostki informacji.
Strategie optymalizacji szybkości zapisu ✍️
Istnieje kilka wzorców strukturalnych, które pomagają zmniejszyć obciążenie zapisu. Te strategie skupiają się na minimalizowaniu rozmiaru każdej transakcji oraz zmniejszaniu złożoności pracy silnika przechowywania danych.
1. Partycjonowanie i sharding
Podział dużej tabeli na mniejsze, łatwiejsze do zarządzania fragmenty pozwala bazie danych rozłożyć obciążenie zapisu na wiele segmentów fizycznych lub logicznych.
- Partycjonowanie poziome: Dzielenie wierszy na podstawie klucza (np. zakresy dat, identyfikatory użytkowników).
- Partycjonowanie pionowe: Przenoszenie rzadko dostępnym kolumnom do oddzielnych tabel.
- Sharding: Rozdzielanie danych na wiele instancji bazy danych.
Ten podejście zmniejsza rozmiar indeksów, które należy utrzymywać, i ogranicza zakres blokad podczas operacji zapisu. Jeśli jeden shard zostanie przeprowadzony, inne pozostają nieDotknięte.
2. Strategie denormalizacji
Przechowywanie danych nadmiarowych pozwala systemowi uniknąć łączeń podczas zapisu. Na przykład zamiast obliczać sumę całkowitą z powiązanych wierszy za każdym razem, gdy przychodzi nowa transakcja, system może bezpośrednio zaktualizować kolumnę podsumowania obliczoną z góry.
- Kolumny obliczane: Przechowuj wartości pochodne bezpośrednio w wierszu.
- Widoki materializowane: Oblicz z góry wyniki dla częstych agregacji.
- Buforowane liczniki: Utrzymuj osobną tabelę liczników do statystyk.
Choć zwiększa wymagania dotyczące pamięci, znacznie obniża koszt CPU wstawiania.
3. Strategia indeksowania
Indeksy przyspieszają odczyty, ale spowalniają zapisy. Za każdym razem, gdy wstawiany jest wiersz, baza danych musi zaktualizować każdy powiązany indeks. W środowiskach o wysokim obciążeniu zapisu, nadmiarowe indeksy stają się poważnym problemem.
- Minimalizuj liczbę indeksów: Indeksuj tylko kolumny używane do filtrowania lub łączenia.
- Częściowe indeksy: Indeksuj tylko podzbiór wierszy, które są często dostępne.
- Unikaj nadmiernego indeksowania: Pomijaj indeksy w kolumnach, które często się zmieniają.
Porównanie podejść projektowych 📑
Poniższa tabela przedstawia wpływ różnych wyborów strukturalnych na wydajność zapisu i integralność danych.
| Strategia | Wydajność zapisu | Integralność danych | Koszt przechowywania | Najlepsze zastosowanie |
|---|---|---|---|---|
| Pełna normalizacja | Niski | Wysoka | Niski | Złożone raportowanie, niski obciążenie zapisu |
| Denormalizowane | Wysoki | Średni | Wysoki | Strumienie czasu rzeczywistego, wysokie obciążenie zapisu |
| Schemat podzielony | Wysoki | Wysoki | Średni | Dane szeregów czasowych, duże zbiory danych |
| Szerokie tabele | Średni-Wysoki | Średni | Średni | Wzorce NoSQL, rzadkie dane |
Obsługa kluczy obcych i ograniczeń 🔗
Integralność referencyjna jest fundamentem projektowania relacyjnego, ale wymuszanie ograniczeń przy każdym zapisie może zatrzymać szybki przepływ danych. Silnik bazy danych musi zweryfikować, czy istnieje wiersz nadrzędny, na który odnosi się wiersz potomny, zanim zaakceptuje wiersz potomny.
W sytuacjach, gdy integralność danych jest kluczowa, ale prędkość zapisu ma pierwszeństwo, rozważ następujące zmiany:
- Odwłokane ograniczenia: Weryfikuj relacje na końcu transakcji, a nie od razu.
- Sprawdzanie na poziomie aplikacji: Weryfikuj relacje w kodzie aplikacji przed wysłaniem danych do bazy danych.
- Miękkie usuwanie: Oznaczaj rekordy jako nieaktywne zamiast usuwać je, aby zachować linki referencyjne bez kosztów usuwania.
Usuwanie ograniczeń całkowicie jest ryzykowne, ale przeniesienie logiki weryfikacji czasem może poprawić przepustowość. Decyzja zależy od tego, jak krytyczna jest natychmiastowa spójność dla Twojego konkretnego przepływu pracy.
Amplifikacja zapisu i silniki przechowywania 💾
Zrozumienie, jak silnik przechowywania obsługuje dane, jest kluczowe. Wiele silników używa dziennika zapisu z przodu (WAL), aby zapewnić trwałość. Oznacza to, że każdy zapis jest zapisywany w dzienniku przed zastosowaniem do rzeczywistych plików danych.
Amplifikacja zapisu występuje, gdy pojedyncza operacja zapisu logicznego prowadzi do wielu operacji zapisu fizycznego. Jest to powszechne w silnikach przechowywania z intensywną kompaktacją. Aby to zarządzać:
- Wstawianie partii: Połącz wiele wierszy w jedną transakcję.
- Zapisy sekwencyjne: Projektuj schematy, aby sprzyjać generowaniu kluczy sekwencyjnych zamiast losowych wstawień.
- Buforowanie: Pozwól na tymczasowy bufor na warstwie aplikacji, aby kolejka zapisów przed ich zapisaniem.
Poprzez dopasowanie projektu ERD do zalet silnika przechowywania danych możesz zmniejszyć fizyczny wysiłek potrzebny do trwalego przechowywania danych.
Monitorowanie i iteracja 🔄
Schemat zaprojektowany dla dużych ilości zapisów nie jest statyczny. W miarę zmian wzorców ruchu projekt może wymagać ewolucji. Nieprzerwane monitorowanie opóźnień zapisu i I/O dysku jest niezbędne.
- Śledź opóźnienia zapisu: Identyfikuj szczyty, które wskazują na węzły ograniczeń.
- Monitoruj czekanie na blokady: Wykrywaj punkty zawieszenia, gdzie procesy są zablokowane.
- Analizuj używanie indeksów: Usuń indeksy, które nigdy nie są używane, aby zmniejszyć obciążenie zapisu.
Regularne audyty ERD zapewniają, że struktura pozostaje zgodna z obecnymi wymaganiami operacyjnymi. Jeśli określona tabela ciągle ma problemy z przepustowością zapisu, może być czas na ponowne rozważenie strategii podziału lub poziomu normalizacji.
Podsumowanie kluczowych rozważań 🛠️
Projektowanie ERD dla dużych ilości zapisów wymaga zmiany nastawienia od czystej czystości danych do przepustowości systemu. Poniższe punkty podsumowują istotne działania:
- Audyt normalizacji: Upewnij się, że każda relacja przynosi wartość, a nie tylko złożoność.
- Zaplanuj podział: Projektuj klucze, aby umożliwić łatwy poziomy podział.
- Ogranicz indeksy: Zachowaj ścieżkę zapisu jak najbardziej zwięzłą.
- Zaakceptuj nadmiarowość: Używaj denormalizacji, aby zmniejszyć zależności połączeń podczas wstawiania.
- Weryfikuj stopniowo: Przenieś sprawdzanie ograniczeń poza krytyczną ścieżkę zapisu tam, gdzie to bezpieczne.
Stosując te zasady, tworzysz model danych zdolny do utrzymania wzrostu bez poświęcania wydajności. Celem nie jest usunięcie złożoności, ale zarządzanie nią w sposób wspierający prędkość działania Twojej aplikacji.