











Diagramy relacji encji (ERD) pełnią rolę projektu budowy bazy danych. Określają, jak dane są strukturalnie ułożone, przechowywane i pobierane w systemie. Gdy te diagramy zawierają błędy, skutki sięgają daleko poza fazę rozwoju. Błędy w środowisku produkcyjnym mogą prowadzić do uszkodzenia danych, zawieszeń wydajności oraz znacznych strat finansowych. Zrozumienie typowych pułapek jest kluczowe dla utrzymania integralności systemu.
Wiele zespołów pośpiesza się przez fazę modelowania, dając priorytet szybkości przed dokładnością. Taka pośpiech często prowadzi do problemów z schematem, które są trudne do rozwiązania, gdy dane zaczynają przepływać. Solidny projekt wymaga dokładnej analizy relacji, typów danych i ograniczeń. Poniżej omawiamy najczęściej występujące błędy projektowe i ich konsekwencje techniczne.
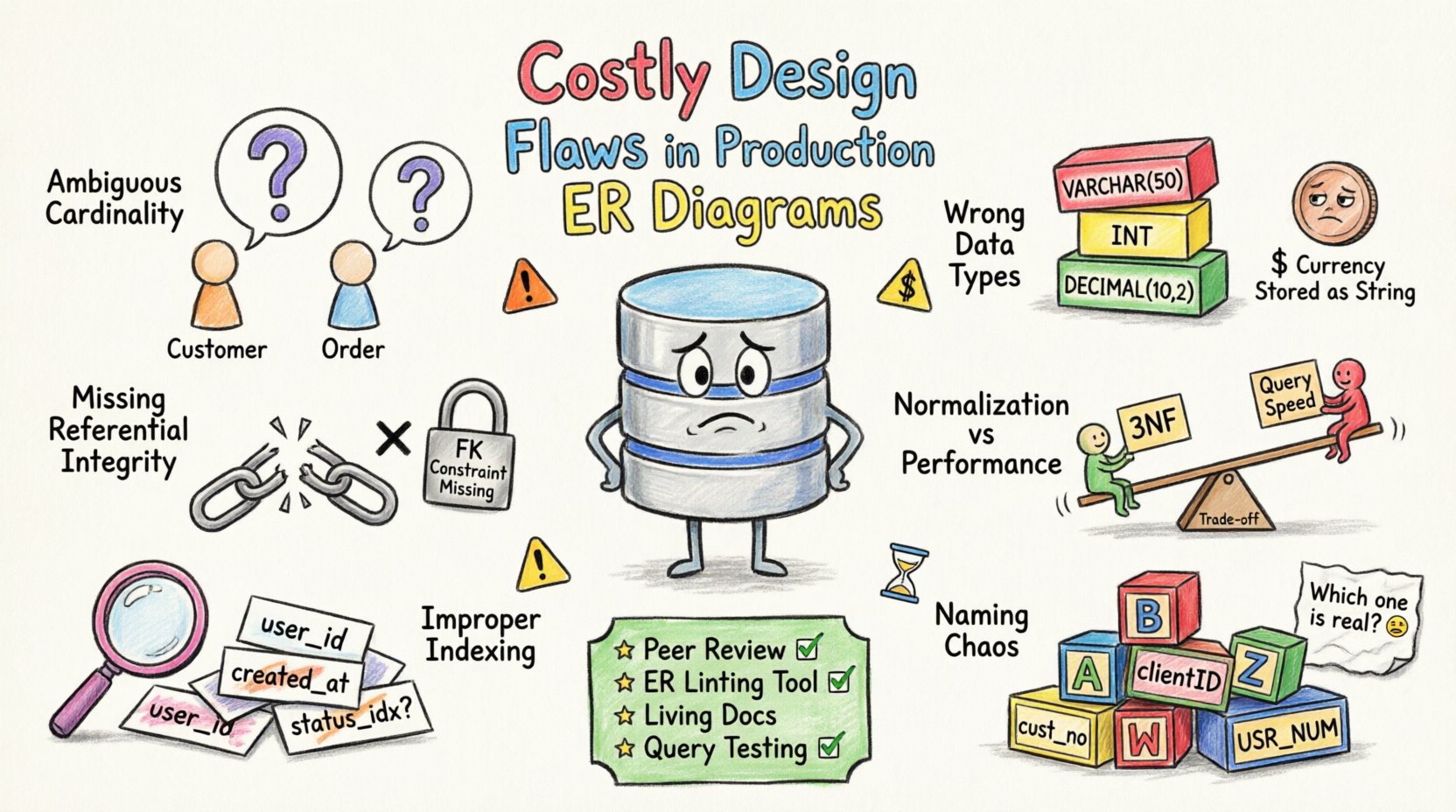
1. Niejasna liczba i relacje 🔗
Liczba określa liczbową relację między encjami. Niepoprawna liczba prowadzi do błędów logicznych podczas pobierania i przechowywania danych. Powszechnym błędem jest założenie relacji jeden do jednego, gdy istnieje relacja jeden do wielu.
- Pominięcie relacji wiele do wielu:Nieutworzenie tabeli pośredniej dla relacji wiele do wielu wymusza duplikację danych lub skomplikowane zapytania łączące.
- Nieokreślone klucze obce:Bez jawnych kluczy obcych baza danych nie może zapewnić integralności referencyjnej, co pozwala na istnienie zaniedbanych rekordów.
- Opcjonalne vs. Obowiązkowe:Nieprawidłowe klasyfikowanie relacji wymaganej jako opcjonalna wprowadza wartości null w miejscach, gdzie oczekuje się danych.
Na przykład rozważ klienta i zamówienie. Jeśli diagram sugeruje, że klient może istnieć bez zamówienia, ale logika aplikacji tego wymaga, baza danych zapisze niekompletne profile. Ta rozbieżność powoduje awarie aplikacji lub niezgodne raporty.
2. Niespójny wybór typów danych 📊
Typy danych określają sposób przechowywania i przetwarzania informacji. Niepoprawny wybór typu zużywa niepotrzebną pamięć lub ogranicza zakres wartości. Problemy z precyzją często pojawiają się, gdy do pieniędzy używane są liczby zmiennoprzecinkowe.
- Przepełnienie liczb całkowitych:Używanie małych liczb całkowitych do identyfikatorów może prowadzić do błędów przepełnienia wraz ze wzrostem zbioru danych.
- Długość tekstu:Używanie pól znakowych o stałej długości marnuje miejsce dla danych o zmiennej długości.
- Dokładność daty:Przechowywanie dat bez stref czasowych powoduje problemy synchronizacji w systemach rozproszonych.
Wybór ogólnego pola tekstowego do numerów telefonów to inny częsty błąd. Pozwala to na wprowadzanie nieprawidłowych znaków do systemu, co utrudnia późniejszą logikę weryfikacji. Pola numeryczne powinny być używane do obliczeń, a pola tekstowe tylko do danych alfanumerycznych.
3. Brak ograniczeń integralności referencyjnej 🔒
Integralność referencyjna zapewnia, że relacje między tabelami pozostają spójne. Bez tych ograniczeń baza danych polega na kodzie aplikacji w celu utrzymania dokładności danych, co jest podatne na błędy ludzkie.
- Brak reguł kaskadowych: Usuwanie rekordu nadrzędnego bez reguł kaskadowych pozostawia rekordy potomne bez przyczepienia w bazie danych.
- Brakujące ograniczenia:Opieranie się na weryfikacji na poziomie aplikacji zamiast ograniczeń bazy danych jest niewystarczające.
- Miękkie usuwanie:Nieodpowiednie zarządzanie usuniętymi rekordami powoduje zamieszanie i spowalnia wydajność zapytań.
Gdy ograniczenia są pominięte, integralność danych zależy całkowicie od programistów aplikacji. Jeśli błąd pozwala na bezpośredni zapis do bazy danych, niezgodności stają się stałe. Jest to główny powód uszkodzenia danych w długotrwałych systemach produkcyjnych.
4. Normalizacja wobec wydajności – kompromisy ⚖️
Normalizacja zmniejsza nadmiarowość, ale może zwiększać złożoność zapytań. Nadmierna normalizacja prowadzi do nadmiaru połączeń, a niedostateczna normalizacja powoduje anomalie aktualizacji. Znalezienie odpowiedniego poziomu jest kluczowe dla wydajności.
- Trzecia postać normalna (3NF): Często idealna dla systemów transakcyjnych, ale może wymagać denormalizacji w przypadku obciążeń odczytowych.
- Denormalizacja: Wprowadzanie nadmiarowości dla poprawy wydajności musi być zapisane, aby zapobiec konfliktom aktualizacji.
- Złożoność zapytań: Głęboko normalizowane schematy wymagają skomplikowanych połączeń, które obciążają silnik bazy danych.
Zespoły często normalizują do ekstremum, aby zapewnić czystość danych, ignorując koszt łączenia wielu tabel. W środowiskach o wysokim obciążeniu prowadzi to do wolnych czasów odpowiedzi. Strategiczna denormalizacja może poprawić wydajność odczytu, pod warunkiem poprawnego zarządzania operacjami zapisu.
5. Nieodpowiednia strategia indeksowania 🏷️
Indeksy przyspieszają pobieranie danych, ale spowalniają operacje zapisu. Źle zaprojektowany ERD często nie uwzględnia sposobu, w jaki dane będą zapytywane. Powoduje to pełne skanowanie tabel i wysokie opóźnienia.
- Brakujące indeksy kluczy obcych: Łączenia na kolumnach bez indeksu są obliczeniowo kosztowne.
- Zbyt dużo indeksów: Zbyt wiele indeksów zwiększa opóźnienia zapisu i wymagania pamięciowe.
- Kolejność kolumn w indeksie złożonym: Nieprawidłowa kolejność kolumn w indeksach złożonych sprawia, że są one bezużyteczne.
Indeks na często zapytywanej kolumnie to standardowa praktyka. Jednak ignorowanie wzorców zapytań w fazie projektowania prowadzi do nieefektywnych ścieżek dostępu. Regularne przeglądy planów wykonania zapytań są konieczne do dostosowania strategii indeksowania.
6. Chaos w konwencjach nazewnictwa 🏷️
Spójne konwencje nazewnictwa są kluczowe dla utrzymywalności. Niespójne nazwy tabel i kolumn utrudniają zrozumienie i modyfikację schematu.
- Mieszane wielkości liter: Używanie camelCase w niektórych miejscach i snake_case w innych powoduje zamieszanie.
- Niejasne skróty: Krótkie nazwy takie jak „cust” lub „ord” są niejasne dla nowych członków zespołu.
- Zarezerwowane słowa kluczowe: Używanie słów zarezerwowanych jako nazwy tabel powoduje błędy składni w zapytaniach.
Jasne nazewnictwo zmniejsza obciążenie poznawcze dla programistów i administratorów baz danych. Ułatwia również generowanie automatycznej dokumentacji i zmniejsza prawdopodobieństwo błędów literowych w instrukcjach SQL.
Analiza skutków typowych wad
| Błąd projektowy | Wpływ techniczny | Koszty biznesowe |
|---|---|---|
| Brakujące klucze obce | Zagubione rekordy, niezgodność danych | Przegrane dane, naruszenia zgodności |
| Niepoprawne typy danych | Zmarnowane miejsce, błędy obliczeń | Rozbieżności finansowe, błędy raportowania |
| Zbyt duża normalizacja | Wolna wydajność zapytań, wysokie opóźnienia | Wolny doświadczenie użytkownika, utracone przychody |
| Brakujące indeksy | Pełne skany tabel, zawieszenie bazy danych | Przerwy w działaniu systemu, słaba skalowalność |
| Zła nazwa | Wysokie koszty utrzymania, wysokie stawki błędów | Zwiększony czas rozwoju, błędy |
Strategie zapobiegania 🛡️
Zapobieganie tym wadom wymaga dyscyplinarnego podejścia do projektowania bazy danych. Poniższe kroki pomagają zmniejszyć ryzyko przed wdrożeniem.
- Recenzje kolegów: Wprowadź obowiązkowe przeglądy schematu przed scaleniem jakiejkolwiek zmiany.
- Automatyczne sprawdzanie stylu: Używaj narzędzi do sprawdzania zasad nazewnictwa i standardów strukturalnych.
- Dokumentacja: Utrzymuj aktualne schematy ERD odzwierciedlające rzeczywisty schemat.
- Testowanie: Przeprowadź testy weryfikacji schematu w środowisku testowym przed wdrożeniem produkcyjnym.
Wprowadzenie procesu kontroli wersji dla schematów baz danych zapewnia śledzenie zmian i ich cofnięcie. Pozwala to zespołom określić, kiedy została wprowadzona wada, i cofnąć zmianę, jeśli to konieczne. Współpraca między programistami a architektami jest kluczowa, aby wykryć problemy na wczesnym etapie.
Długoterminowe rozważania dotyczące utrzymania 🔄
Schematy baz danych ewoluują z czasem. Projekt, który działa obecnie, może nie spełniać przyszłych wymagań. Regularne audyty pomagają wykryć długoterminowe zobowiązania technologiczne i przestarzałe wzorce.
- Zmiana schematu: Monitoruj różnice między ERD a bazą danych w trybie produkcyjnym.
- Uprzejmość: Zaprojektuj usunięcie nieużywanych tabel i kolumn.
- Skalowalność: Projektuj z myślą o partycjonowaniu i rozdzielaniu danych dla dużych zbiorów danych.
Ignorowanie utrzymania w ruchu prowadzi do niestabilnego systemu, który opiera się na zmianach. Proaktywne zarządzanie zapewnia, że baza danych pozostaje wiarygodną podstawą dla aplikacji. Inwestowanie czasu w początkowy projekt przynosi zyski przez cały cykl życia oprogramowania.
Ostateczne rozważania na temat integralności schematu 📝
Błędy w bazie danych produkcyjnej często wynikają z pominiętych szczegółów w fazie projektowania. Poprzez rozwiązywanie kardynalności, typów danych, ograniczeń i indeksowania zespoły mogą budować bardziej odpornych systemów. Koszt naprawy błędu w środowisku produkcyjnym jest znacznie wyższy niż zapobieganie mu podczas modelowania.
Skup się na przejrzystości, spójności i weryfikacji. Dobrze zorganizowany ERD to fundament wiarygodności danych. Uważaj na jakość zamiast na szybkość, aby zapewnić stabilność na długie lata. Ten podejście minimalizuje ryzyko i maksymalizuje wartość danych przechowywanych w systemie.