











एक टिकाऊ डेटा आर्किटेक्चर डिज़ाइन करने के लिए बॉक्स और लाइनें बनाने से अधिक चाहिए। इसमें डेटा के प्रवाह, वृद्धि और समय के साथ बदलाव के बारे में गहन समझ की आवश्यकता होती है। जब कोई प्रणाली स्केल होती है, तो संगठन संबंध मॉडल (ERD) तार्किक सुसंगतता के लिए नींव के रूप में काम करता है, जबकि विभाजन रणनीतियाँ भौतिक प्रदर्शन को संबोधित करती हैं। इन दोनों पहलुओं को एक साथ लाना प्रश्न गति, डेटा अखंडता और संचालन दक्षता बनाए रखने के लिए महत्वपूर्ण है। यह मार्गदर्शिका यह जांचती है कि अपने मौजूदा डेटा मॉडल के साथ विभाजन तकनीकों को कैसे समन्वयित किया जाए बिना अनावश्यक जटिलता या जोखिम के जोड़े।
🧩 आधार: ERD को एक नींव के रूप में
डेटा को कैसे विभाजित करना है, इसके बारे में सोचने से पहले, इसे जोड़ने वाले संबंधों को समझना आवश्यक है। एक ERD में प्राथमिकता, गुण, और उनके बीच कार्डिनैलिटी को परिभाषित किया जाता है। इन संबंधों के द्वारा डेटा कैसे प्राप्त किया जाता है और जोड़ा जाता है, यह निर्धारित होता है। जब आप विभाजन लागू करते हैं, तो आप वास्तव में इन तार्किक संबंधों को भौतिक स्टोरेज सीमाओं के बीच फैला रहे होते हैं।
विभाजन के अपने स्कीमा पर निम्नलिखित प्रभावों पर विचार करें:
- प्राथमिक कुंजियाँ: विभाजनों के बीच समान वितरण सुनिश्चित करने के लिए सावधानी से चुना जाना चाहिए।
- विदेशी कुंजियाँ: अलग-अलग विभाजनों में स्थित तालिकाओं को जोड़ने में महत्वपूर्ण ओवरहेड हो सकता है।
- इंडेक्स: यदि विभाजन कुंजी के बारे में विचार न किया गया हो, तो वैश्विक इंडेक्स बॉटलनेक बन सकते हैं।
- डेटा स्थिति: संबंधित डेटा को आदर्श रूप से एक ही नोड पर रहना चाहिए ताकि नेटवर्क लेटेंसी को कम किया जा सके।
इन कारकों के बारे में ध्यान न देने से एक ऐसी स्थिति बन सकती है जहां तार्किक मॉडल डिज़ाइन में पूरी तरह से काम करता है, लेकिन भौतिक कार्यान्वयन लोड के तहत कठिनाई में पड़ जाता है। लक्ष्य यह है कि संबंधित डेटा को एक साथ रखा जाए, जबकि स्वतंत्र वृद्धि की अनुमति दी जाए।
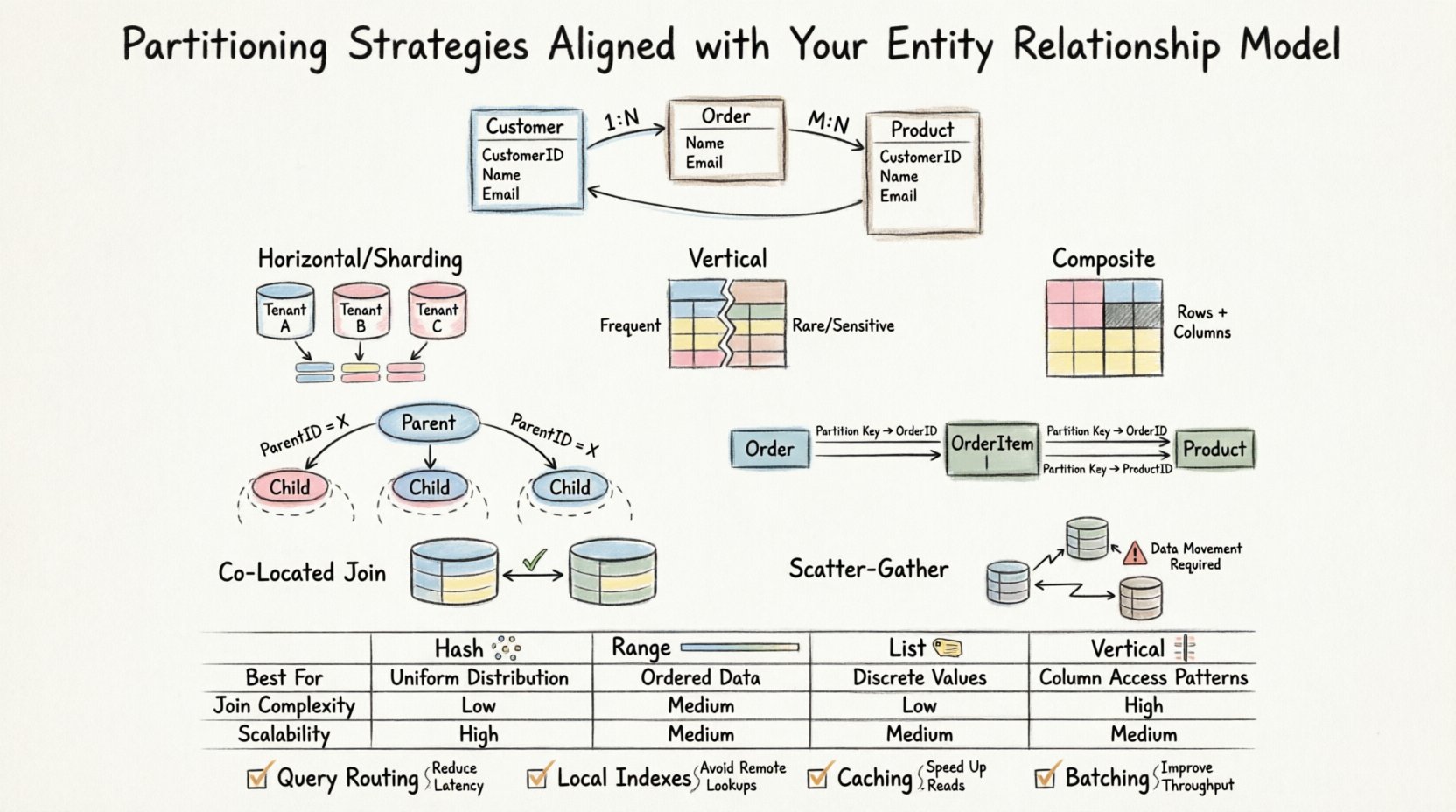
🔄 विभाजन प्रकार और स्कीमा फिट
विभिन्न विभाजन विधियाँ विभिन्न डेटा पहुंच पैटर्न के लिए उपयुक्त होती हैं। सही विधि का चयन अधिकांश रूप से इस बात पर निर्भर करता है कि आपका ERD संबंधों को कैसे परिभाषित करता है और कौन-से प्रश्न पैटर्न की अपेक्षा की जाती है। नीचे सामान्य रणनीतियों का विश्लेषण और वे संबंधात्मक संरचनाओं के साथ कैसे बातचीत करती हैं, इसका वर्णन है।
क्षैतिज विभाजन (शार्डिंग)
क्षैतिज विभाजन एक तालिका की पंक्तियों को अलग-अलग समूहों में विभाजित करता है। जब तालिकाएं एक ही इंस्टेंस में प्रबंधित करने के लिए बहुत बड़ी हो जाती हैं, तो इसका उपयोग अक्सर किया जाता है। ERD के संदर्भ में, यह रणनीति तब सबसे अच्छा काम करती है जब विभाजन कुंजी प्राकृतिक पहुंच पैटर्न से संबंधित होती है।
- उपयोग के मामले: अलग-अलग उपयोगकर्ता या टेंट ग्रुप के साथ बड़ी लेनदेन तालिकाएं।
- ERD प्रभाव: मुख्य तालिका की ओर इशारा करने वाली विदेशी कुंजियों को ध्यान से प्रबंधित किया जाना चाहिए। यदि मुख्य तालिका भी विभाजित है, तो कुंजियों को संरेखित करना आवश्यक है।
- लाभ: अधिक नोड्स जोड़कर विशाल पैमाने पर स्केलआउट की अनुमति देता है।
- चुनौती: एक से अधिक विभाजनों को छूने वाले जटिल प्रश्नों के लिए एकत्रीकरण तर्क की आवश्यकता होती है।
उर्ध्वाधर विभाजन
उर्ध्वाधर विभाजन एक तालिका के कॉलम को अलग-अलग समूहों में विभाजित करता है। जब विशिष्ट कॉलम एक साथ दुर्लभ रूप से प्राप्त किए जाते हैं या जब संवेदनशील डेटा को अलग करने की आवश्यकता होती है, तो यह उपयोगी होता है।
- उपयोग के मामले: विशाल पंक्तियों वाली तालिकाएं जहां केवल कॉलम के एक उपसमूह को ही अक्सर प्रश्न किया जाता है।
- ERD प्रभाव: पूरी पंक्ति के पुनर्निर्माण के लिए सभी ऊर्ध्वाधर पार्टीशन पर प्राथमिक कुंजी का अस्तित्व होना आवश्यक है।
- लाभ:केवल आवश्यक कॉलम को मेमोरी में लोड करके I/O को कम करता है।
- चुनौती:पूर्ण प्रतिनिधित्व के पुनर्निर्माण के लिए जॉइन की आवश्यकता होती है, जिससे क्वेरी की जटिलता बढ़ जाती है।
मिश्रित पार्टीशनिंग
इस दृष्टिकोण में क्षैतिज और ऊर्ध्वाधर रणनीतियों को मिलाया गया है। उच्च प्रदर्शन वाले प्रणालियों के लिए यह आवश्यक होता है जहां पंक्ति आयतन और कॉलम चौड़ाई दोनों ही महत्वपूर्ण सीमाओं के रूप में उभरते हैं।
- उपयोग के मामले: डेटा वेयरहाउसिंग या उच्च आवृत्ति वाले ट्रेडिंग लॉग।
- ERD प्रभाव: कार्यान्वयन से पहले एक कठोर स्कीमा परिभाषा की आवश्यकता होती है।
🔑 संबंधों के साथ कुंजियों को समायोजित करना
इस प्रक्रिया में सबसे महत्वपूर्ण चरण पार्टीशन कुंजी का चयन करना है। यह कुंजी तय करती है कि कौन सी पंक्ति किस भौतिक स्टोरेज इकाई में जाती है। संबंधात्मक संदर्भ में, पार्टीशन कुंजी को आदर्श रूप से विदेशी कुंजी संबंधों के साथ मेल खाना चाहिए।
माता-पिता-बच्चा संबंध
एक से बहुत के संबंधों के साथ निपटते समय, बच्चे की तालिका अक्सर माता-पिता की तुलना में बहुत तेजी से बढ़ती है। यदि आप बच्चे की तालिका को माता-पिता के ID द्वारा पार्टीशन करते हैं, तो सभी संबंधित बच्चे के रिकॉर्ड एक ही नोड पर रहते हैं।
- लाभ: माता-पिता और सभी बच्चों को प्राप्त करने वाले प्रश्नों में क्रॉस-नोड संचार की आवश्यकता नहीं होती है।
- लाभ: एक ही पार्टीशन के भीतर ही डिलीट के कैस्केड दक्षता से होते हैं।
- चेतावनी: यदि एक माता-पिता के अन्यों की तुलना में काफी अधिक बच्चे हैं, तो डेटा विचलन हो सकता है।
बहुत से से बहुत से संबंध
बहुत से से बहुत से संबंधों में आमतौर पर एक जंक्शन तालिका शामिल होती है। यदि सही तरीके से पार्टीशन नहीं किया गया है, तो यह तालिका प्रदर्शन की बाधा बन सकती है।
- रणनीति: शामिल विदेशी कुंजियों में से एक द्वारा पार्टीशन करें।
- रणनीति: सुनिश्चित करें कि प्रश्न हमेशा पार्टीशन कुंजी द्वारा फ़िल्टर करें ताकि पूरी तालिका के स्कैन से बचा जा सके।
- रणनीति: आवश्यकता होने पर बिल्कुल भी बहुत से पार्टीशन के बीच जंक्शन तालिकाओं के जॉइन से बचें।
⚖️ जॉइन ऑपरेशन्स का प्रबंधन
जॉइन रिलेशनल डेटाबेस की जीवनरक्षक हैं, लेकिन जब डेटा विभाजित होता है तो वे महंगे हो जाते हैं। पार्टीशन के बीच जॉइन के व्यवहार को समझना प्रदर्शन बनाए रखने के लिए आवश्यक है।
सह-स्थित पार्टीशन
यदि तालिका A और तालिका B एक ही की (उदाहरण के लिए, Tenant_ID) द्वारा पार्टीशन की जाती हैं, तो उनके बीच जॉइन स्थानीय रूप से होता है। डेटाबेस इंजन को नोड्स के बीच डेटा ले जाने की आवश्यकता नहीं होती है।
- आवश्यकता: दोनों तालिकाओं को समान पार्टीशनिंग एल्गोरिदम और की का उपयोग करना चाहिए।
- आवश्यकता: ईआरडी को इस संरेखण को तार्किक रूप से समर्थन करना चाहिए।
स्कैटर-गैदर जॉइन
जब तालिकाओं को अलग-अलग तरीके से पार्टीशन किया जाता है, तो सिस्टम को कई नोड्स से डेटा लाना होता है, परिणामों को एकत्र करना होता है, और फिर अंतिम सेट वापस करना होता है। इसे स्कैटर-गैदर ऑपरेशन के रूप में जाना जाता है।
- प्रदर्शन लागत: उच्च नेटवर्क ओवरहेड।
- प्रदर्शन लागत: बढ़ी हुई लेटेंसी।
- सिफारिश: ईआरडी डिजाइन चरण में इन जॉइन को न्यूनतम करें।
🛡️ पार्टीशन के बीच अखंडता बनाए रखना
जब डेटा वितरित होता है, तो डेटा अखंडता की सीमाएं लागू करना मुश्किल हो जाता है। ईआरडी इन नियमों को तार्किक रूप से परिभाषित करता है, लेकिन कार्यान्वयन को भौतिक वितरण का प्रबंधन करना होता है।
- संदर्भात्मक अखंडता:यदि वे अलग-अलग नोड्स पर स्थित हैं, तो एक माता रिकॉर्ड को डालने से पहले एक बच्चे के रिकॉर्ड के मौजूद होने की गारंटी देना मुश्किल होता है।
- यूनिक सीमाएं: वैश्विक अद्वितीयता के लिए सभी पार्टीशन के बीच समन्वय की आवश्यकता होती है।
- ट्रिगर्स: वितरित वातावरण में लॉकिंग समस्याओं से बचने के लिए आवेदन-स्तरीय ट्रिगर्स अक्सर डेटाबेस-स्तरीय ट्रिगर्स को बदल देते हैं।
- लेनदेन: वितरित लेनदेन के थ्रूपुट पर प्रभाव पड़ सकता है। जब भी संभव हो, लेनदेन को एक ही पार्टीशन में स्थानीय रखें।
📊 पार्टीशनिंग रणनीति की तुलना
निम्नलिखित तालिका विभिन्न रणनीतियों के सामान्य ईआरडी परिदृश्यों के साथ कैसे बातचीत करती है, इसका सारांश देती है।
| रणनीति | ईआरडी परिदृश्य के लिए सर्वोत्तम | जॉइन कठिनाई | लेखन स्केलेबिलिटी |
|---|---|---|---|
| हैश पार्टीशनिंग | समान वितरण की आवश्यकता है, कोई विशिष्ट सीमा नहीं | उच्च (यादृच्छिक वितरण) | उच्च |
| रेंज पार्टीशनिंग | तारीख-आधारित या क्रमागत आईडी | निम्न (यदि संरेखित हो) | मध्यम |
| सूची पार्टीशनिंग | निश्चित श्रेणियाँ (उदाहरण के लिए, क्षेत्र, स्थिति) | निम्न (यदि संरेखित हो) | उच्च |
| उर्ध्वाधर पार्टीशनिंग | चौड़ी पंक्तियाँ, अप्रामाणिक स्तंभ | मध्यम (पुनर्निर्माण की आवश्यकता है) | उच्च |
🔄 विकास और स्थानांतरण
स्कीमा विकास अनिवार्य है। व्यवसाय की आवश्यकताएं बदलती हैं, और नए गुण जोड़े जाते हैं। जब एक एरडी को संशोधित करते हैं, तो पार्टीशनिंग रणनीति की समीक्षा करना आवश्यक है।
- स्तंभ जोड़ना:उर्ध्वाधर पार्टीशनिंग स्तंभ जोड़ने को आसान बनाती है, क्योंकि उन्हें एक नए पार्टीशन पर रखा जा सकता है।
- की बदलना:मौजूदा डेटा को पुनः पार्टीशन करना एक भारी ऑपरेशन है। इसकी योजना प्रारंभिक डिजाइन के दौरान बनाएं।
- आर्काइविंग:पार्टीशनिंग पुराने डेटा रेंज के आसान आर्काइविंग की अनुमति देती है बिना सक्रिय पार्टीशन के प्रभावित किए।
- निगरानी:सुनिश्चित करने के लिए नियमित रूप से पार्टीशन के आकार की जांच करें कि कोई भी एक पार्टीशन हॉटस्पॉट न बन जाए।
🚀 प्रदर्शन अनुकूलन टिप्स
सुनिश्चित करने के लिए कि प्रणाली लचीली बनी रहे, विशिष्ट अनुकूलन पार्टीशनिंग रणनीति के साथ लागू किए जाने चाहिए।
- प्रश्न मार्गदर्शन: सुनिश्चित करें कि एप्लिकेशन पार्टीशन की गुणवत्ता के आधार पर सही पार्टीशन नोड पर प्रश्न भेजें।
- インडेक्सिंग: स्थानीय सूचकांक वैश्विक सूचकांकों से तेज होते हैं। सूचकांकों को पार्टीशन की गुणवत्ता के अनुरूप डिज़ाइन करें।
- कैशिंग: अक्सर एक्सेस किए जाने वाले लुकअप टेबल को पार्टीशन नहीं करना चाहिए यदि वे सभी नोड्स पर मेमोरी में फिट होने के लिए पर्याप्त छोटे हैं।
- बैचिंग: पार्टीशन के बीच लेनदेन ओवरहेड को कम करने के लिए बैच में इन्सर्ट और अपडेट करें।
🔍 अंतिम विचार
स्केल होने वाली प्रणाली बनाने के लिए तार्किक स्पष्टता और भौतिक सीमाओं के बीच संतुलन बनाए रखना आवश्यक है। एंटिटी रिलेशनशिप मॉडल डेटा सुसंगतता के नियम प्रदान करता है, जबकि पार्टीशनिंग वृद्धि के तरीके को प्रदान करता है। जब दोनों एक साथ मिलते हैं, तो प्रणाली डेटा के आकार के एक्सपोनेंशियल बढ़ने के बावजूद प्रदर्शन करती रहती है।
अपने मॉडल में परिभाषित संबंधों पर ध्यान केंद्रित करें। यदि डेटा किसी विशिष्ट लक्षण द्वारा प्राकृतिक रूप से समूहित है, तो उस लक्षण को अपने पार्टीशन की गुणवत्ता के रूप में उपयोग करें। यदि जॉइन अक्सर होते हैं, तो सुनिश्चित करें कि संबंधित टेबल एक ही पार्टीशनिंग तरीके का उपयोग करें। स्पष्ट प्रदर्शन उद्देश्य के बिना पार्टीशन के साथ स्कीमा को अत्यधिक जटिल न बनाएं।
इन सिद्धांतों का पालन करने से आप एक ऐसा आधार बनाते हैं जो लंबे समय तक स्थिरता को समर्थन देता है। लक्ष्य केवल डेटा स्टोर करना नहीं है, बल्कि उसे इस तरह संरचित करना है कि प्रणाली भविष्य की आवश्यकताओं के अनुकूल हो सके बिना पूरी तरह से बदलाव के बिना। डिज़ाइन चरण के दौरान ध्यान से योजना बनाने से ऑपरेशन के दौरान महत्वपूर्ण इंजीनियरिंग प्रयास बचते हैं।