









स्केलेबल सॉफ्टवेयर आर्किटेक्चर के क्षेत्र में, बहु-प्रयोगकर्ता की अवधारणा मूलभूत है। एक ही एप्लिकेशन इंस्टेंस बहुत से ग्राहकों, जिन्हें टेंट्स के रूप में जाना जाता है, को सेवा देता है, जबकि डेटा के तार्किक विभाजन को बनाए रखता है। नीचे की डेटा संरचना को डिज़ाइन करने के लिए सटीकता की आवश्यकता होती है। एंटिटी रिलेशनशिप डायग्राम (ERD) इस आर्किटेक्चर के लिए ब्लूप्रिंट के रूप में कार्य करते हैं। वे टेबल, कीज़ और नियमों के बीच संबंधों को दिखाते हैं जो टेंट्स के बीच डेटा अखंडता को बनाए रखते हैं। 📐
बहु-प्रयोगकर्ता वातावरण के लिए ERD बनाते समय, मुख्य चुनौती आइसोलेशन, प्रदर्शन और लागत के बीच संतुलन बनाए रखना है। हर परिदृश्य के लिए एक ही समाधान नहीं है। इसके बजाय, आर्किटेक्ट्स को सुरक्षा आवश्यकताओं और संचालन बजट के अनुरूप एक पैटर्न चुनना होता है। यह लेख इन स्कीमा के मॉडलिंग के मुख्य रणनीतियों का अध्ययन करता है, विशिष्ट विक्रेता उपकरणों पर निर्भरता के बिना तकनीकी कार्यान्वयन विवरणों में गहराई से जाने का प्रयास करता है। 🛠️
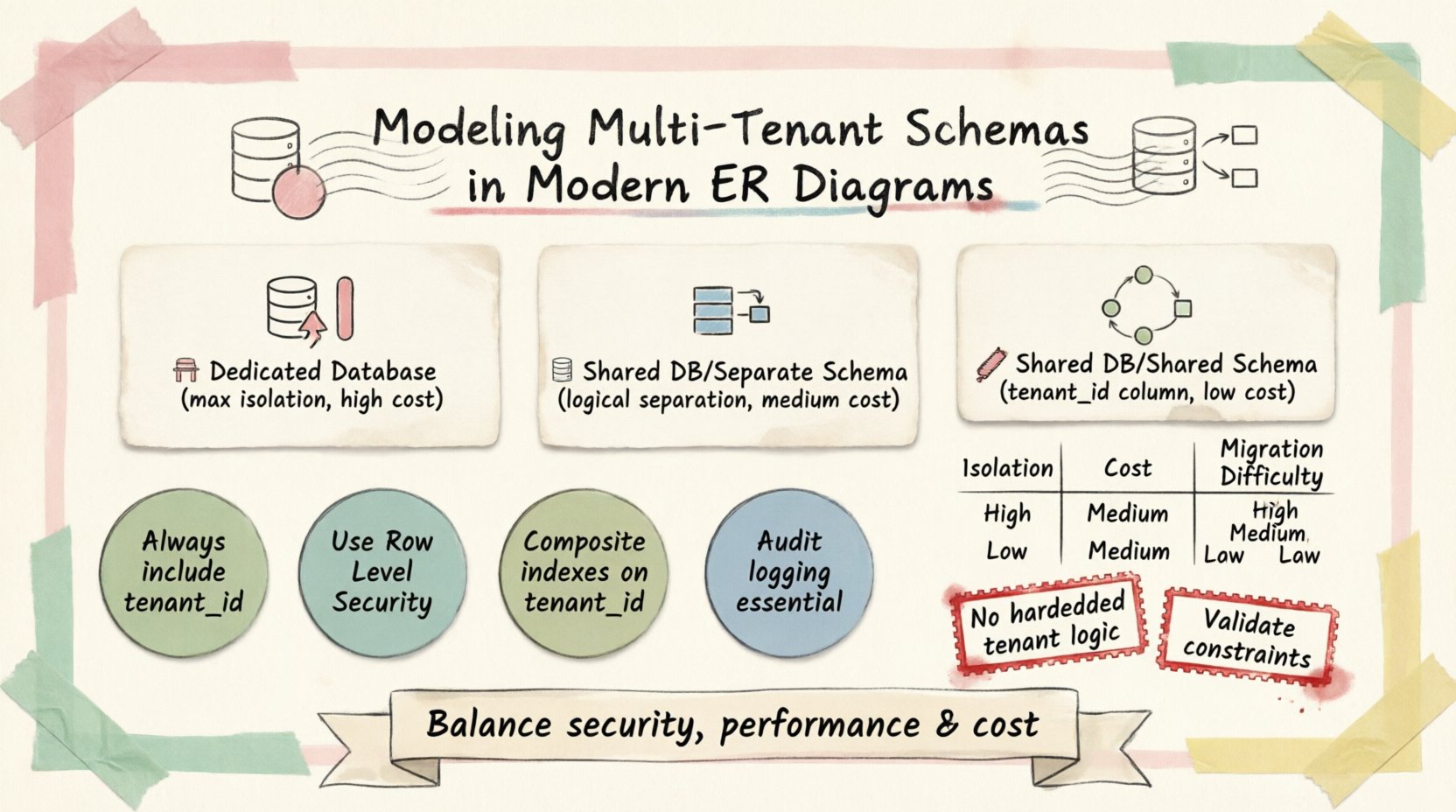
मूल पैटर्नों को समझना 🔍
बहु-प्रयोगकर्ता मॉडलिंग का आधार यह है कि टेंट के डेटा को भौतिक रूप से कैसे संग्रहीत किया जाता है और तार्किक रूप से कैसे अलग किया जाता है। उद्योग में तीन अलग-अलग पैटर्न प्रमुख हैं। प्रत्येक डेटा आइसोलेशन और रखरखाव की जटिलता के संबंध में अद्वितीय व्यापार लाभ-हानि प्रस्तुत करता है।
1. प्रत्येक टेंट के लिए अलग डेटाबेस 🏢
इस दृष्टिकोण में, प्रत्येक ग्राहक को अपना अलग डेटाबेस इंस्टेंस मिलता है। ERD संरचना सभी इंस्टेंस में समान रहती है, लेकिन भौतिक सीमाएं सख्त होती हैं।
- आइसोलेशन स्तर:अधिकतम। एक डेटाबेस में विफलता अन्य को प्रभावित नहीं करती है।
- सुरक्षा:उच्च। भौतिक अलगाव अनजाने डेटा लीकेज को रोकता है।
- लागत:प्रत्येक इंस्टेंस के संसाधन ओवरहेड के कारण अधिक।
- माइग्रेशन:जटिल। स्कीमा बदलाव के लिए प्रत्येक इंस्टेंस पर स्क्रिप्ट चलाने की आवश्यकता होती है।
ERD के दृष्टिकोण से, इस पैटर्न एक मानक सिंगल-टेंट डायग्राम की तरह दिखता है। हालांकि, डेप्लॉयमेंट पाइपलाइन को कई कनेक्शनों का प्रबंधन करना होता है। यह आमतौर पर सख्त संपादन आवश्यकताओं वाले एंटरप्राइज क्लाइंट्स के लिए उपयोग किया जाता है।
2. साझा डेटाबेस, अलग स्कीमा 📂
यहां, सभी टेंट्स एक ही डेटाबेस सिस्टम के भीतर रहते हैं, लेकिन प्रत्येक टेंट के अपने अलग स्कीमा (नेमस्पेस) होते हैं। प्रत्येक स्कीमा के लिए टेबल की नकल की जाती है।
- आइसोलेशन स्तर:उच्च। डेटाबेस इंजन के भीतर तार्किक अलगाव।
- सुरक्षा:मजबूत। एक्सेस कंट्रोल सूचियां (ACLs) स्कीमा दृश्यता को सीमित कर सकती हैं।
- लागत:मध्यम। डेटाबेस इंजन के ओवरहेड को साझा करता है।
- रखरखाव:अलग डेटाबेस की तुलना में आसान, लेकिन स्कीमा अपडेट को सभी स्कीमा में प्रसारित करना होता है।
ERD में, इसे विशिष्ट नेमस्पेस लेबल के तहत टेबल के समूह के रूप में दर्शाया जाता है। संबंध स्थिर रहते हैं, लेकिन आरेख का दायरा बढ़ता है ताकि कई स्कीमा कंटेनर दिखाए जा सकें।
3. साझा डेटाबेस, साझा स्कीमा 🔗
यह सामान्य SaaS एप्लिकेशन के लिए सबसे आम पैटर्न है। सभी डेटा एक ही सेट टेबल में रहता है, जो एक विशिष्ट कॉलम द्वारा अलग किया जाता है।
- आइसोलेशन स्तर: तार्किक। सभी पंक्तियाँ एक ही तालिका में मौजूद हैं।
- सुरक्षा: एप्लिकेशन लॉजिक और पंक्ति स्तरीय सुरक्षा (RLS) पर निर्भर।
- लागत: सबसे कम। संसाधन उपयोग को अधिकतम करता है।
- रखरखाव: सरल। स्कीमा बदलाव सभी टेंटेन्ट्स पर तुरंत लागू होते हैं।
इस पैटर्न के लिए ईआरडी में एक महत्वपूर्ण कॉलम का परिचय होता है: टेंटेन्ट_आईडी। यह विदेशी कुंजी प्रत्येक रिकॉर्ड को एक विशिष्ट ग्राहक से जोड़ती है। इस मॉडल में डेटा विभाजन की नींव है।
ईआरडी में टेंटेन्ट डेटा का दृश्यीकरण 📊
बहु-टेंटेन्ट लेने के लिए प्रभावी ईआरडी बनाने के लिए विशिष्ट नोटेशन की आवश्यकता होती है ताकि विभाजन रणनीति को स्पष्ट रूप से संचारित किया जा सके। हितधारकों को समझने की आवश्यकता है कि डेटा कैसे प्रवाहित होता है और सीमाएँ कहाँ मौजूद हैं।
टेंटेन्ट आईडी कॉलम
एक साझा स्कीमा में, टेंटेन्ट_आईडी हर तालिका में उपयोगकर्ता-विशिष्ट डेटा संग्रहीत करने वाली तालिका पर उपस्थित होना चाहिए। यह वैकल्पिक नहीं है। एक लेनदेन तालिका से इस कॉलम को छोड़ने से गंभीर डेटा लीकेज हो सकता है।
- प्राथमिक कुंजी: अक्सर,
टेंटेन्ट_आईडीऔर स्थानीय आईडी का संयोजन एक संयुक्त प्राथमिक कुंजी बनाता है। - इंडेक्सिंग: प्रदर्शन के लिए महत्वपूर्ण। प्रश्न जो
टेंटेन्ट_आईडीद्वारा फ़िल्टर किए जाने पर तेज़ होने चाहिए। - सीमाएँ: विदेशी कुंजियाँ अक्सर एक केंद्रीय
टेंटेन्ट्समास्टर तालिका को संदर्भित करती हैं।
मास्टर टेंटेन्ट तालिका
एक निर्दिष्ट तालिका आमतौर पर प्रत्येक टेंटेन्ट के बारे में मेटाडेटा संग्रहीत करने के लिए मौजूद होती है। इस तालिका में कॉन्फ़िगरेशन विवरण, सदस्यता स्थिति और बिलिंग जानकारी संग्रहीत होती है।
- मुख्य लक्षण:टेंटेन्ट आईडी, नाम, प्लान स्तर, बनाए गए दिनांक।
- संबंध:सभी अन्य डेटा तालिकाओं के साथ एक-से-बहुत।
स्कीमा रणनीतियों की तुलना 📋
एक जानकार निर्णय लेने के लिए, नीचे दी गई तालिका का उपयोग करके प्रत्येक रणनीति के संचालन प्रभाव की तुलना करें।
| विशेषता | निर्दिष्ट डीबी | साझा स्कीमा | साझा तालिका |
|---|---|---|---|
| डेटा अलगाव | भौतिक | तार्किक | तार्किक |
| क्वेरी जटिलता | सरल | जटिल | जटिल |
| संसाधन लागत | उच्च | मध्यम | निम्न |
| स्कीमा माइग्रेशन | कठिन | मध्यम | आसान |
| बैकअप रणनीति | विस्तृत | विस्तृत | पूर्ण डंप |
सुरक्षा और डेटा विभाजन 🔒
स्कीमा का मॉडलिंग केवल लड़ाई का आधा हिस्सा है। डेटा एक्सेस लेयर को आरेख में परिभाषित सीमाओं को लागू करना चाहिए। साझा तालिकाओं के उपयोग में तार्किक अलगाव लक्ष्य है।
पंक्ति स्तरीय सुरक्षा (RLS)
आधुनिक डेटाबेस इंजन RLS का समर्थन करते हैं, जो पंक्ति स्तर पर पहुंच नीतियों को लागू करते हैं। इससे डेटाबेस स्वयं वर्तमान उपयोगकर्ता संदर्भ के आधार पर परिणामों को फ़िल्टर करने की अनुमति मिलती है।
- नीति परिभाषा: एक नियम कहता है कि एक पंक्ति केवल तभी दिखाई देगी यदि
टेंटेंट आईडीसत्र से मेल खाती है। - कार्यान्वयन: ईआरडी में सत्र संदर्भ संग्रहण की क्षमता को दर्शाना चाहिए।
- लाभ: एप्लिकेशन स्तर की त्रुटियों के कारण डेटा लीक होने के जोखिम को कम करता है।
सत्यापन और लॉगिंग
टेंटेंट-विशिष्ट डेटा में होने वाले प्रत्येक परिवर्तन को लॉग किया जाना चाहिए। ईआरडी में एक ऑडिट टेबल आवश्यक है ताकि यह ट्रैक किया जा सके कि किसने क्या बदला और कब। यह संगति और डीबगिंग के लिए महत्वपूर्ण है।
- आवश्यक क्षेत्र: टेंटेंट आईडी, उपयोगकर्ता आईडी, क्रिया, समयचिह्न, पुराना मान, नया मान।
- रखरखाव: नीतियों में यह निर्धारित करना चाहिए कि लॉग कितने समय तक रखे जाएं।
प्रदर्शन पर विचार ⚡
साझा तालिकाएं प्रश्न निष्पादन योजनाओं में जटिलता लाती हैं। जैसे-जैसे डेटा का आयतन बढ़ता है, डेटाबेस इंजन को पूरी तालिका को स्कैन किए बिना टेंटेंट डेटा को प्रभावी ढंग से अलग करने की आवश्यकता होती है।
इंडेक्सिंग रणनीतियां
मानक इंडेक्सिंग पर्याप्त नहीं है। आपको ऐसे संयुक्त इंडेक्स की आवश्यकता होगी जो टेंटेंट पहचानकर्ता को प्राथमिकता देते हैं।
- प्राथमिक इंडेक्स: के साथ शुरू होना चाहिए
टेंटेंट आईडीउसके बाद प्राकृतिक कुंजी आती है। - प्रश्न अनुकूलन: सुनिश्चित करें कि सभी प्रश्नों में
जहांवाक्यांश में टेंटेंट फ़िल्टर शामिल हो। - विभाजन: कुछ प्रणालियाँ तालिकाओं के भौतिक विभाजन की अनुमति देती हैं
tenant_idसीमा या हैश।
प्रश्न कठिनाई
जब एक से अधिक स्कीमा या टेंट के बीच तालिकाओं को जोड़ते हैं, तो जॉइन शर्त में टेंट आईडी शामिल होनी चाहिए। ऐसा न करने से अलग-अलग ग्राहकों के डेटा का कार्टेशियन उत्पाद प्राप्त हो सकता है।
- जॉइन तर्क: हमेशा
tenant_idऔर संबंध कुंजी। - एप्लिकेशन परत: मिडलवेयर को टेंट फ़िल्टर स्वचालित रूप से डालना चाहिए।
रखरखाव और माइग्रेशन 🔄
स्कीमा स्थिर नहीं होते हैं। आवश्यकताओं में परिवर्तन के साथ वे विकसित होते हैं। बहु-टेंट इन परिवर्तनों में एक अतिरिक्त स्तर की कठिनाई जोड़ता है।
स्कीमा विकास
एक साझा तालिका में कॉलम जोड़ना आसान है। कॉलम हटाने से सभी टेंट प्रभावित होते हैं। एक समर्पित डेटाबेस मॉडल में, आपको हर इंस्टेंस के लिए बदलाव के लिए स्क्रिप्ट लिखनी होगी।
- संस्करण निर्धारण: पीछे की अनुकूलता को प्रबंधित करने के लिए स्कीमा संस्करणों को ट्रैक करें।
- रोलबैक्स: यदि किसी टेंट के उपसमूह पर माइग्रेशन विफल हो जाए, तो बदलावों को वापस लाने के लिए एक योजना बनाएं।
बैकअप और पुनर्स्थापना
पुनर्स्थापना रणनीतियाँ पैटर्न के अनुसार भिन्न होती हैं। एक समर्पित डेटाबेस आपको एकल टेंट को बिना अन्य के प्रभावित किए बैकअप करने की अनुमति देता है। एक साझा डेटाबेस के लिए पूरे इंस्टेंस को बैकअप करना आवश्यक है।
- विस्तार: साझा तालिकाएं एकल टेंट के लिए समय-आधारित पुनर्स्थापना कठिन बनाती हैं।
- परीक्षण: एक स्टेजिंग पर्यावरण में बैकअप पुनर्स्थापना प्रक्रियाओं का नियमित रूप से परीक्षण करें।
बचने के लिए सामान्य त्रुटियाँ ⚠️
अच्छे डिज़ाइन वाले ईआरडी के साथ भी, कार्यान्वयन त्रुटियाँ प्रणाली को कमजोर कर सकती हैं। इन सामान्य समस्याओं के बारे में सतर्क रहें।
- कड़े टेंट तर्क: कभी भी एप्लिकेशन कोड में टेंट आईडी को कड़े रूप से न लिखें। कॉन्फ़िगरेशन या सेशन संदर्भ का उपयोग करें।
- वैश्विक चर: कृपया टेंट के संदर्भ को वैश्विक चर में स्टोर न करें जो अनुरोधों के बीच बने रह सकते हैं।
- अनुपस्थित सीमाएँ: यदि डेटाबेस द्वारा लागू नहीं किया जाता है
टेंट_idएकाधिकता, तो एप्लिकेशन को इसकी सख्ती से पुष्टि करनी चाहिए। - विश्लेषण को नजरअंदाज करना: रिपोर्टिंग के लिए टेंट के बीच डेटा के संग्रह के लिए सावधानीपूर्वक निपटारा करने की आवश्यकता होती है ताकि संवेदनशील जानकारी के मिश्रण से बचा जा सके।
नामकरण प्रथाओं के लिए सर्वोत्तम व्यवहार 🏷️
नामकरण में सामंजस्य विकासकर्मियों को डेटा संरचना को तुरंत समझने में मदद करता है। यदि साझा स्कीमा में टेंट-विशिष्ट तालिकाएँ मौजूद हैं, तो प्रीफिक्स या सफिक्स का उपयोग करें।
- तालिका नामकरण:
टेंट_नाम_आदेशयाआदेश_टेंट_आईडी. - स्तंभ नामकरण: हमेशा शामिल करें
टेंट_idप्रत्येक रिकॉर्ड तालिका में स्पष्ट रूप से। - इंडेक्स: इंडेक्स के नाम स्पष्ट रूप से रखें, उदाहरण के लिए,
idx_आदेश_टेंट_id.
आर्किटेक्चर चयनों पर निष्कर्ष 🎯
सही बहु-टेंट स्कीमा पैटर्न चुनने के लिए तकनीकी लागूता और व्यावसायिक आवश्यकताओं के बीच संतुलन आवश्यक है। ईआरडी इस चयन को पूरी टीम को संदेश देने का उपकरण है। सुरक्षा के लिए भौतिक अलगाव या दक्षता के लिए साझा तालिकाओं का चयन करने में, आरेख में सीमाओं को स्पष्ट रूप से दिखाना आवश्यक है।
कठोर मॉडलिंग मानकों का पालन करने, विश्वसनीय इंडेक्सिंग के लागू करने और स्पष्ट अलगाव तर्क को बनाए रखने से आप एक सुरक्षित रूप से स्केल होने वाली प्रणाली बना सकते हैं। जब आधार ठोस होता है, तो टेंट की जटिलता प्रबंधित की जा सकती है। आरेख की पहली लाइन से ही डेटा अखंडता और प्रदर्शन पर ध्यान केंद्रित करें। 🚀