











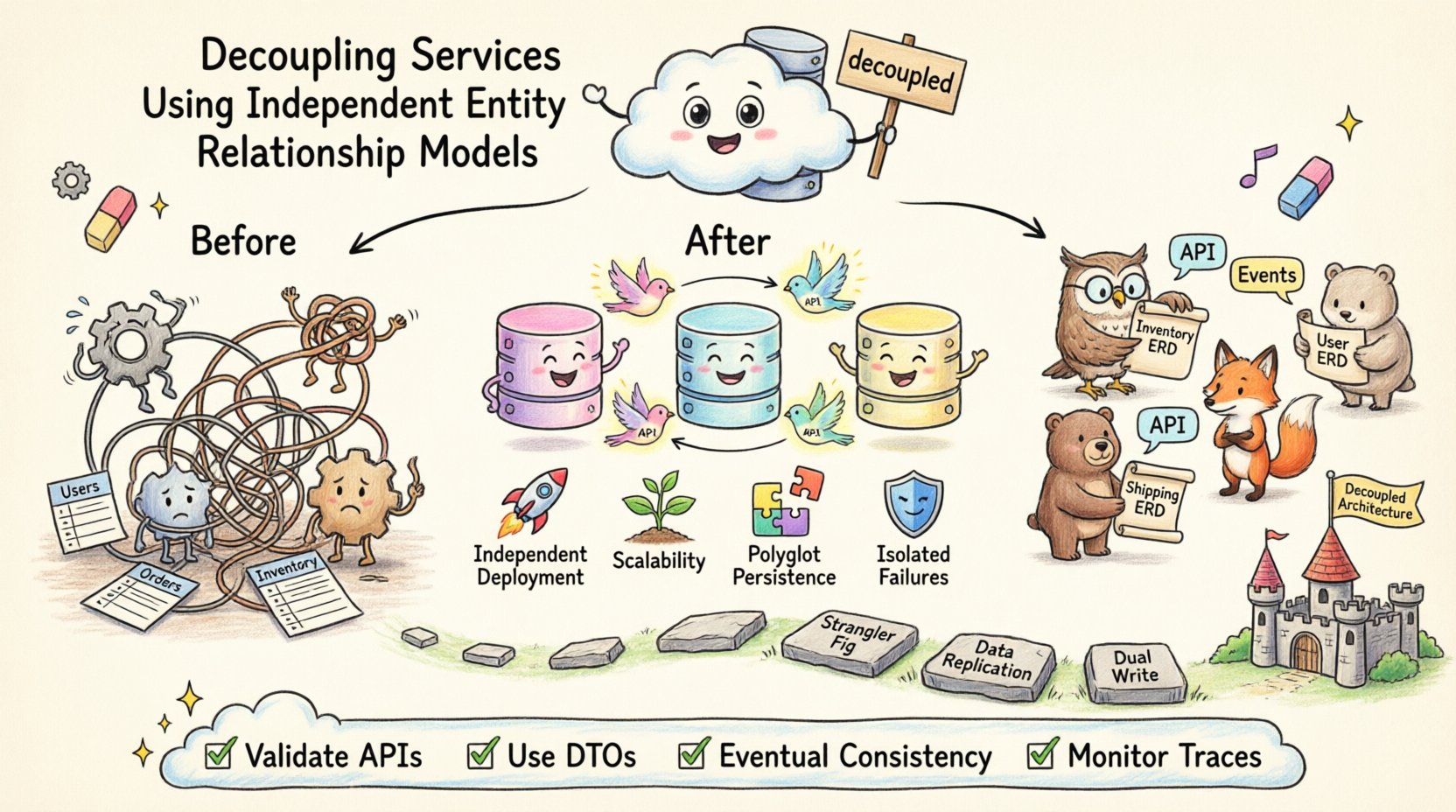
आधुनिक सॉफ्टवेयर आर्किटेक्चर में, चिंता के विभाजन को कोड लॉजिक तक ही सीमित नहीं रखा जाता, बल्कि डेटा स्वामित्व तक फैलाया जाता है। जब सेवाएं एक ही डेटाबेस स्कीमा का उपयोग करती हैं, तो वे अनिवार्य रूप से एक दूसरे के आंतरिक कार्यान्वयन पर निर्भर हो जाती हैं। इस तात्कालिक बंधन से लचीलापन की कमी आती है, डेप्लॉयमेंट गति प्रभावित होती है और स्केलिंग के प्रयास जटिल हो जाते हैं। वास्तविक मॉड्यूलरिटी प्राप्त करने के लिए, टीमों को प्रत्येक सेवा सीमा के लिए स्वतंत्र एंटिटी रिलेशनशिप मॉडल्स को अपनाना चाहिए। इस दृष्टिकोण से यह सुनिश्चित होता है कि डेटा संरचनाएं उस सेवा के नियंत्रण में रहती हैं जिसके पास उनका स्वामित्व है, जिससे लचीलापन और स्वतंत्रता बढ़ती है।
🤔 साझा डेटा की चुनौती
पुराने सिस्टम अक्सर एक मोनोलिथिक डेटाबेस पर निर्भर होते हैं जहां कई एप्लीकेशन मॉड्यूल एक ही टेबल को प्रश्न करते हैं। जब तक विकास की शुरुआत होती है, तब यह सरल बनाता है, लेकिन जैसे-जैसे सिस्टम बढ़ता है, इसमें महत्वपूर्ण जोखिम आते हैं। एक मॉड्यूल की डेटा आवश्यकताओं में बदलाव दूसरे मॉड्यूल की कार्यक्षमता को तोड़ सकता है जो उसी टेबल संरचना पर निर्भर है। इस घटना को कहा जाता है साझा डेटाबेस एंटीपैटर्न.
एक ऐसे परिदृश्य पर विचार करें जहां यूजर सेवा को प्रोफाइल टेबल में एक नया फील्ड जोड़ने की आवश्यकता हो। यदि ऑर्डर सेवा उस टेबल को सीधे यूजर नामों के लिए प्रश्न करती है, तो अपडेट के लिए समन्वित डेप्लॉयमेंट या डेटाबेस माइग्रेशन की आवश्यकता हो सकती है जो दोनों टीमों को एक साथ प्रभावित करती है। इस समन्वय ओवरहेड नवाचार को धीमा करता है और उत्पादन घटनाओं के जोखिम को बढ़ाता है।
-
डेप्लॉयमेंट निर्भरताएं:यदि सेवाएं स्कीमा परिभाषाओं को साझा करती हैं, तो वे स्वतंत्र रूप से डेप्लॉय नहीं की जा सकती हैं।
-
स्केलेबिलिटी सीमाएं:एक ही डेटाबेस अक्सर एक बैरियर बन जाता है जब कुछ सेवाओं को दूसरों की तुलना में अधिक संसाधनों की आवश्यकता होती है।
-
सुरक्षा जोखिम:सीधे टेबल एक्सेस सेवा परत को बाहर रखता है, जिससे संवेदनशील डेटा तर्क के खुले होने की संभावना होती है।
🗺️ स्वतंत्र एंटिटी रिलेशनशिप मॉडल्स को परिभाषित करना
एक स्वतंत्र एंटिटी रिलेशनशिप मॉडल (ERD) एक सेवा के लिए एक विशिष्ट डेटा स्कीमा निर्धारित करता है। इसका अर्थ है कि सेवा अपने डेटाबेस, अपनी टेबल और अपने संबंधों को नियंत्रित करती है। अन्य सेवाओं को इन टेबलों तक सीधे पहुंच नहीं होती है। बल्कि वे परिभाषित इंटरफेस, जैसे API या मैसेज क्यू के माध्यम से बातचीत करती हैं।
इस आर्किटेक्चरल शैली को अक्सर कहा जाता है सेवा प्रति डेटाबेस। यह डेटा स्वामित्व को व्यावसायिक क्षमताओं के साथ मिलाता है। उदाहरण के लिए, इन्वेंटरी सेवा स्टॉक स्तरों का प्रबंधन करती है, जबकि शिपिंग सेवा डिलीवरी पतों का प्रबंधन करती है। न तो सेवा दूसरे की आंतरिक टेबलों के लिए फॉरेन की रेफरेंस रख सकती है।
प्रक्रिया में शामिल है:
-
सीमाओं को पहचानना:यह तय करें कि कौन सा डेटा किस व्यावसायिक क्षमता के लिए है।
-
स्थानीय स्कीमा डिजाइन करना:केवल उस सेवा की विशिष्ट आवश्यकताओं का समर्थन करने वाले ERD बनाएं।
-
इंटरफेस को परिभाषित करना:यह स्थापित करें कि डेटा को आंतरिक संरचनाओं के बाहर बनाए रखते हुए सेवाओं के बीच कैसे आदान-प्रदान किया जाता है।
📈 स्कीमा इसोलेशन के मुख्य लाभ
स्वतंत्र ERD को अपनाने से टीमों द्वारा जटिलता के प्रबंधन के तरीके में बदलाव आता है। यह केंद्रीकृत नियंत्रण से वितरित स्वायत्तता की ओर ध्यान केंद्रित करता है। प्रत्येक टीम अपनी डेटा स्टोरेज रणनीति को अनुकूलित कर सकती है बिना वैश्विक प्रभावों के बारे में चिंता किए।
|
पहलू |
साझा डेटाबेस मॉडल |
स्वतंत्र ERD मॉडल |
|---|---|---|
|
डेप्लॉयमेंट |
समन्वित, जोखिम भरा |
स्वतंत्र, अक्सर |
|
स्केलेबिलिटी |
केवल क्षैतिज (क्लस्टर) |
प्रत्येक सेवा के लिए ऊर्ध्वाधर |
|
तकनीक |
एकल डीबी प्रकार |
बहुभाषी स्थिरता |
|
असफलता क्षेत्र |
एकल असफलता बिंदु |
अलगाव वाली असफलताएं |
🔗 ढीले जुड़ाव के लिए डिज़ाइन करना
जब सेवाएं एक दूसरे के डेटाबेस से सीधे बातचीत नहीं कर सकती हैं, तो उन्हें एपीआई के माध्यम से संचार करना होता है। इसके लिए सेवाओं के बीच संवाद के सौदे का ध्यान से डिज़ाइन करना आवश्यक है। एपीआई ही एकमात्र साझा सौदा बन जाता है। यदि एपीआई सौदा स्थिर रहता है, तो नीचे के डेटा मॉडल में बदलाव करने पर उपभोक्ताओं को प्रभावित नहीं किया जाता है।
एपीआई संस्करण निर्धारण: चूंकि डेटा मॉडल विकसित होते हैं, एपीआई को संस्करण निर्धारण का समर्थन करना आवश्यक है। इससे पुराने क्लाइंट चलते रहते हैं जबकि नए क्लाइंट अपडेटेड संरचनाओं को अपनाते हैं।
डेटा स्थानांतरण वस्तुएं (DTOs): एंटिटी ऑब्जेक्ट्स को सीधे एक्सपोज़ न करें। उपभोक्ता के लिए आवश्यक डेटा के सिर्फ एक ही डेटा के साथ विशिष्ट DTOs बनाएं। इससे आंतरिक बदलावों के बाहर निकलने से रोका जा सकता है।
-
सत्यापन: एपीआई के सीमा पर इनपुट की सत्यापन करें, केवल डेटाबेस स्तर पर नहीं।
-
आइडेम्पोटेंसी: सुनिश्चित करें कि संचालन को सुरक्षित रूप से दोहराया जा सकता है बिना डुप्लीकेट रिकॉर्ड बनाए।
-
दस्तावेज़ीकरण: सभी डेटा आदान-प्रदान प्रारूपों के लिए स्पष्ट दस्तावेज़ीकरण बनाए रखें।
⚖️ लेनदेन और संगति का प्रबंधन
अलगाव में सबसे महत्वपूर्ण चुनौतियों में से एक डेटा अखंडता बनाए रखना है। एक साझा डेटाबेस में, एक लेनदेन कई टेबलों को आसानी से छू सकता है। एक वितरित प्रणाली में, एकल तार्किक लेनदेन कई सेवाओं को छू सकता है। इसे कहा जाता हैवितरित लेनदेन समस्या.
इस समस्या को हल करने के लिए, टीमें अक्सर अपनाती हैंअंततः संगति पैटर्न। तुरंत सभी जगह डेटा समान होने की गारंटी देने के बजाय, प्रणाली समय के साथ यह सुनिश्चित करती है कि डेटा संगत हो जाए। इसे असिंक्रोनस संदेशवाहक के माध्यम से प्राप्त किया जाता है।
सैगा पैटर्न: एक सैगा स्थानीय लेनदेन का क्रम है। प्रत्येक लेनदेन डेटाबेस को अपडेट करता है और अगले लेनदेन को ट्रिगर करने के लिए एक घटना प्रकाशित करता है। यदि कोई चरण विफल होता है, तो पूर्व के परिवर्तनों को वापस लेने के लिए संतुलित लेनदेन किए जाते हैं।
-
आउटबॉक्स पैटर्न: मुख्य डेटा परिवर्तन के साथ-साथ स्थानीय तालिका में घटनाओं को लिखें। एक बैकग्राउंड प्रक्रिया इन घटनाओं को प्रकाशित करती है, जिससे कोई डेटा नष्ट नहीं होता।
-
आइडेम्पोटेंट उपभोक्ता: संदेश हैंडलर्स को डुप्लीकेट संदेशों को बेहतर तरीके से संभालना चाहिए।
-
संतुलित कार्रवाई: प्रत्येक आगे बढ़ने वाली कार्रवाई के लिए स्पष्ट रॉलबैक तर्क परिभाषित करें।
🚚 माइग्रेशन रणनीतियाँ
एक साझा डेटाबेस से स्वतंत्र ERD में जाना एक महत्वपूर्ण कार्य है। इसके लिए जोखिम को कम करने के लिए चरणबद्ध दृष्टिकोण की आवश्यकता होती है। माइग्रेशन को जल्दबाजी में करने से डेटा के नुकसान या सेवा बाधा का खतरा होता है।
स्ट्रैंगलर फिग पैटर्न: क्रमिक रूप से कार्यक्षमता को नए सेवाओं में स्थानांतरित करें। उपयोगकर्ता सूचनाओं जैसी एक विशिष्ट सुविधा से शुरुआत करें। उस सुविधा के लिए अपने अलग ERD के साथ एक नई सेवा बनाएं। पुरानी प्रणाली चलती रहने देते हुए ट्रैफिक को नई सेवा की ओर मार्गदर्शन करें।
डेटा प्रतिलिपि बनाना: संक्रमण के दौरान, आपको पुराने और नए डेटाबेस के बीच डेटा को समकालीन रखने की आवश्यकता हो सकती है। इससे नई सेवा को अपने आप को भरने के दौरान अस्थायी रूप से पुरानी प्रणाली से डेटा पढ़ने की अनुमति मिलती है।
डुअल लेखन: माइग्रेशन खिंचाव के दौरान पुराने और नए डेटाबेस दोनों में एक साथ लेखन करें। पुराने लेखन को बंद करने से पहले यह सुनिश्चित करें कि नई सेवा सही तरीके से काम कर रही है।
🔍 मॉनिटरिंग और रखरखाव
स्वतंत्र डेटा भंडार के साथ, मॉनिटरिंग अधिक जटिल हो जाती है। अब आप एक ही डेटाबेस के स्वास्थ्य डैशबोर्ड को नहीं देख रहे हैं। आपको बहुत स्रोतों से लॉग और मीट्रिक्स को एकत्र करना होगा।
वितरित ट्रेसिंग: एक अनुरोध के विभिन्न सेवाओं के माध्यम से गुजरने का अनुसरण करने के लिए ट्रेसिंग कार्यान्वित करें। इससे यह पहचानने में मदद मिलती है कि कौन सी सेवा लेटेंसी या त्रुटियों का कारण बन रही है।
स्कीमा रजिस्ट्री: API अनुबंधों की एक रजिस्ट्री बनाए रखें। इससे यह सुनिश्चित होता है कि डेटा मॉडल में कोई भी परिवर्तन डेप्लॉयमेंट से पहले समीक्षा और अनुमोदन के लिए रखा जाए।
-
अलर्टिंग: प्रतिलिपि देरी और संदेश भंडार भार के लिए अलर्ट सेट करें।
-
क्षमता योजना: अप्रत्याशित लागत को रोकने के लिए प्रत्येक सेवा के लिए स्टोरेज वृद्धि को मॉनिटर करें।
-
बैकअप रणनीतियाँ: सुनिश्चित करें कि प्रत्येक सेवा के लिए अपनी बैकअप और पुनर्स्थापन योजना हो।
🛠️ बचने के लिए सामान्य त्रुटियाँ
एक ठोस योजना के साथ भी, टीमें लागू करने के दौरान अक्सर गलतियाँ करती हैं। इन सामान्य गलतियों को समझने से समय और प्रयास की बड़ी बचत हो सकती है।
-
छिपी हुई बाध्यता:यद्यपि वे अलग-अलग स्कीमास में हों, तब भी डेटाबेस दृश्यों या साझा तालिकाओं का उपयोग करने से बचें। सीधे डेटाबेस एक्सेस को निषेध कर देना चाहिए।
-
अत्यधिक विभाजन:हर छोटे कार्य के लिए नया डेटाबेस न बनाएं। संबंधित एंटिटीज को तार्किक सेवाओं में समूहित करें।
-
लेटेंसी को नजरअंदाज करना:नेटवर्क कॉल्स स्थानीय क्वेरीज से धीमी होती हैं। राउंड ट्रिप्स को कम करने के लिए API को डिज़ाइन करें।
-
जटिल क्वेरीज:क्रॉस-सर्विस जॉइन से बचें। यदि आपको कई सेवाओं से डेटा की आवश्यकता है, तो उन्हें अलग-अलग प्रश्न करें और परिणामों को एप्लीकेशन लेयर में मिलाएं।
🧱 अंतिम विचार
स्वतंत्र एंटिटी रिलेशनशिप मॉडल्स के उपयोग से सेवाओं को अलग करना एक रणनीतिक निर्णय है जो लंबे समय में लाभ देता है। इसमें डिज़ाइन में अनुशासन और वितरित जटिलता को प्रबंधित करने की इच्छा की आवश्यकता होती है। हालांकि, परिणाम एक ऐसी प्रणाली है जो बढ़ावा देने में आसान है, असफलता के प्रति अधिक लचीली है और विकास में तेज है। अपने डेटा के मालिक होने से सेवाओं को निरंतर समन्वय के बिना नवाचार करने के लिए आवश्यक स्वतंत्रता मिलती है।
अपनी प्रणाली में सबसे महत्वपूर्ण सीमाओं की पहचान करके शुरुआत करें। सबसे पहले उन सेवाओं के लिए डेटा को अलग करें। आगे बढ़ते जाने के साथ अपने API कॉन्ट्रैक्ट और संदेश पैटर्न को बेहतर बनाएं। इस चरणबद्ध दृष्टिकोण से स्थिरता सुनिश्चित होती है जब आप पूरी तरह से अलग की गई वास्तुकला की ओर बढ़ते हैं।