











डेटाबेस प्रदर्शन अक्सर उन कारकों पर निर्भर करता है जो सामान्य दर्शक के लिए अदृश्य होते हैं। एक ऐसा महत्वपूर्ण कारक लॉक प्रतिस्पर्धा है। जब कई उपयोगकर्ता या प्रक्रियाएं एक ही डेटा को एक साथ प्राप्त करने की कोशिश करते हैं, तो सिस्टम को डेटा अखंडता बनाए रखने के लिए नियमों को लागू करना होता है। इन नियमों के परिणामस्वरूप लॉक बनते हैं। अत्यधिक लॉकिंग बॉटलनेक्स का कारण बनती है, जिससे प्रतिक्रिया समय धीमा हो जाता है और अंतिम उपयोगकर्ताओं को निराशा होती है। मूल कारण अक्सर हार्डवेयर में नहीं होता, बल्कि डेटा संरचना को परिभाषित करने वाले एंटिटी-रिलेशनशिप डायग्राम (ERD) में होता है।
एक अच्छी तरह से डिज़ाइन किया गया स्कीमा उच्च समानांतरता के लिए आधार के रूप में कार्य करता है। डेटा के कैसे प्राप्त किया जाएगा और कैसे संशोधित किया जाएगा, इसकी भविष्यवाणी करके, वास्तुकार तालिकाओं को अंतर्दृष्टि को कम करने के लिए संरचित कर सकते हैं। इस दृष्टिकोण के लिए लेनदेन अलगाव, इंडेक्सिंग रणनीतियों और लॉकिंग के भौतिक तंत्र की गहन समझ की आवश्यकता होती है। निम्नलिखित मार्गदर्शिका बाहरी उपकरणों पर निर्भर न होकर आपके डेटा मॉडल को बेहतर प्रदर्शन के लिए अनुकूलित करने के तरीके को विस्तार से बताती है।
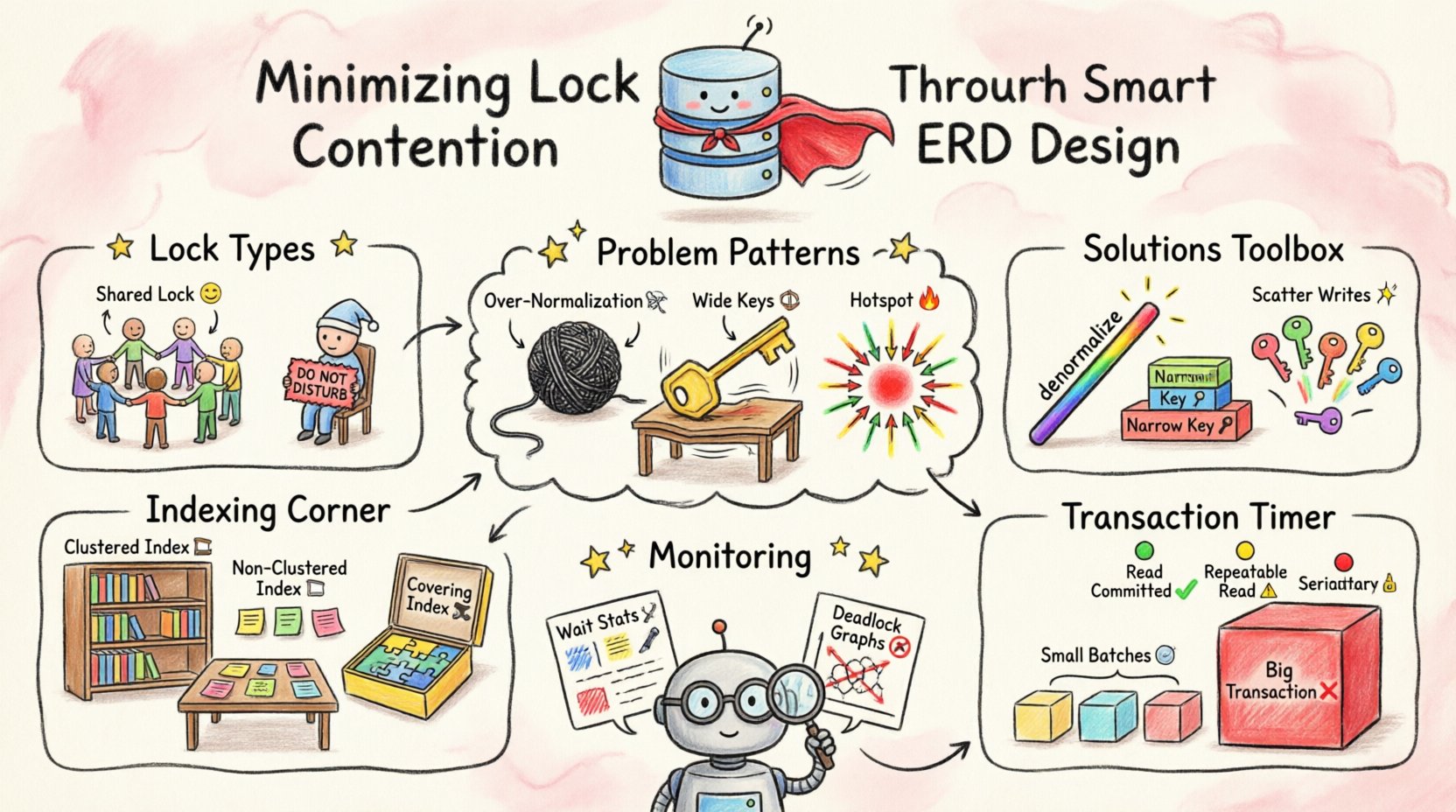
लॉकिंग तंत्र को समझना 🛡️
डिज़ाइन को अनुकूलित करने से पहले, यह आवश्यक है कि आप समझें कि लॉक वास्तव में क्या करते हैं। डेटाबेस असंगतियों को रोकने के लिए लॉक का उपयोग करते हैं। यदि दो लेनदेन एक ही पंक्ति को ठीक एक ही क्षण पर अपडेट करने की कोशिश करते हैं, तो एक संघर्ष उत्पन्न होता है। सिस्टम को तय करना होता है कि कौन पहले जाए।
- साझा लॉक (S): डेटा पढ़ने के लिए उपयोग किया जाता है। एक ही संसाधन पर कई लेनदेन एक साथ साझा लॉक रख सकते हैं।
- एक्सक्लूसिव लॉक (X): डेटा लिखने या संशोधित करने के लिए उपयोग किया जाता है। किसी संसाधन पर केवल एक ही लेनदेन किसी भी समय एक्सक्लूसिव लॉक रख सकता है।
- इंटेंट लॉक: यह इंगित करता है कि एक लेनदेन विरासत के निचले स्तर पर लॉक रखने के इरादे से है, जैसे कि एक तालिका या पृष्ठ।
जब एक्सक्लूसिव लॉक की मांग साझा पहुंच की क्षमता से अधिक होती है, तो लॉक प्रतिस्पर्धा उत्पन्न होती है। यदि आपका ERD डेटाबेस को डेटा खोजने के लिए तालिका के बड़े हिस्से को स्कैन करने के लिए मजबूर करता है, तो लॉक के दायरे में वृद्धि होती है। इससे समानांतर प्रक्रियाओं के बीच टकराव की संभावना बढ़ जाती है।
प्रतिस्पर्धा को उत्पन्न करने वाले स्कीमा पैटर्न 📉
कुछ डिज़ाइन चयनों के आंतरिक रूप से लॉकिंग के लिए सतह क्षेत्र में वृद्धि होती है। इन पैटर्नों को पहचानने से आप विकास चक्र के शुरुआती चरण में रीफैक्टर करने में सक्षम होते हैं।
1. अत्यधिक सामान्यीकरण
जबकि सामान्यीकरण अतिरेक को कम करता है, अत्यधिक सामान्यीकरण प्रदर्शन को नुकसान पहुंचा सकता है। एक ही रिकॉर्ड प्राप्त करने के लिए बहुत सारी तालिकाओं को जोड़ने के लिए बहुत सारी पंक्तियों को बहुत सारी तालिकाओं में लॉक करने की आवश्यकता होती है। यदि एक लेनदेन पांच सामान्यीकृत तालिकाओं से डेटा पढ़ने की आवश्यकता है, तो इसे उन सभी तालिकाओं पर लॉक प्राप्त करने होंगे।
- खतरा: यदि कोई अन्य लेनदेन उनमें से एक तालिका को संशोधित करता है, तो पहला लेनदेन इंतजार कर सकता है।
- समाधान: अक्सर जोड़े जाने वाले कॉलम को असामान्यीकृत करने का विचार करें। जॉइन की संख्या को कम करने से प्रत्येक प्रश्न के लिए आवश्यक लॉक की संख्या कम हो जाती है।
2. चौड़े प्राथमिक कीज़
प्राथमिक कीज़ का उपयोग पंक्तियों को अद्वितीय रूप से पहचानने के लिए किया जाता है। यदि प्राथमिक की एक बहु-स्तंभ वाली संयुक्त की है, तो इंडेक्स के निर्माण के तरीके को प्रभावित करती है। चौड़ी कीज़ इंडेक्स के आकार को बढ़ाती हैं।
- खतरा: बड़े इंडेक्स का अर्थ है कि खोज के दौरान अधिक पृष्ठों को पढ़ने और लॉक करने की आवश्यकता होती है। प्राथमिक की में अपडेट करने से संबंधित तालिकाओं में कैस्केडिंग बदलाव शुरू हो सकते हैं।
- समाधान: जहां संभव हो, सरल और संकीर्ण सरोगेट कीज़ (जैसे पूर्णांक) का उपयोग करें। संयुक्त कीज़ को न्यूनतम रखें और केवल तभी जब तार्किक रूप से आवश्यक हो।
3. क्रमिक कीज़ में हॉटस्पॉट
प्राथमिक कीज़ के लिए स्वचालित रूप से बढ़ते पूर्णांक का उपयोग आम है। हालांकि, यदि एप्लिकेशन डेटा को क्रमिक रूप से डालती है, तो सभी नए लेखन इंडेक्स के अंत में लक्षित करते हैं। इससे एक ‘हॉटस्पॉट’ बनता है जहां कई लेनदेन एक ही लीफ पेज के लिए प्रतिस्पर्धा करते हैं।
- खतरा: डेटाबेस इंजन को हर नए इन्सर्शन के लिए इंडेक्स के अंतिम पृष्ठ को लॉक करना होता है।
- समाधान:उच्च-लेखन परिदृश्यों के लिए यादृच्छिक कुंजियों या हैश-आधारित वितरण का उपयोग करें ताकि लोड को विभिन्न पृष्ठों पर फैलाया जा सके।
स्कीमा अनुकूलन के लिए रणनीतियाँ 🛠️
ERD को अनुकूलित करने में कॉलम, संबंध और प्रतिबंधों के बारे में विशिष्ट चयन करना शामिल है। नीचे दी गई तालिका सामान्य डिज़ाइन निर्णयों और उनके लॉकिंग व्यवहार पर प्रभाव को चित्रित करती है।
| डिज़ाइन निर्णय | लॉकिंग पर प्रभाव | सिफारिश किया गया दृष्टिकोण |
|---|---|---|
| विदेशी कुंजी प्रतिबंध | मुख्य तालिकाओं पर प्रतिक्रियाशील लॉक का कारण बन सकता है। | उच्च-लेखन प्रणालियों के लिए टाले गए प्रतिबंधों या एप्लिकेशन-स्तरीय सत्यापन का उपयोग करें। |
| बड़े BLOB/पाठ कॉलम | पंक्ति के आकार को बढ़ाता है, जिससे प्रति पंक्ति अधिक पृष्ठों की आवश्यकता होती है। | मुख्य तालिका को संकीर्ण रखने के लिए बड़े डेटा को अलग से संग्रहीत करें। |
| उच्च कार्डिनैलिटी कॉलम | अक्षम इंडेक्स उपयोग की ओर जा सकता है। | सुनिश्चित करें कि चयनात्मक कॉलम को इंडेक्स किया गया हो ताकि तालिका स्कैन से बचा जा सके। |
| डिफ़ॉल्ट मान | यदि डिफ़ॉल्ट मान लागू किए जाते हैं, तो अनावश्यक रूप से पंक्तियों को अपडेट करते हैं। | लेखन ट्रिगर से बचने के लिए उचित स्थानों पर NULL की अनुमति दें। |
लेखन और पठन मॉडल को अलग करना
लेखन के लिए उपयोग किए जाने वाले स्कीमा को पठन के लिए उपयोग किए जाने वाले स्कीमा से अलग करने से तनाव में महत्वपूर्ण कमी आती है। लेखन मॉडल अखंडता और सामान्यीकरण पर ध्यान केंद्रित करते हैं। पठन मॉडल गति और असामान्यीकरण पर ध्यान केंद्रित करते हैं।
- लेन-देन प्रक्रिया के लिए डेटा को अत्यधिक सामान्यीकृत संरचना में संग्रहीत करें।
- रिपोर्टिंग या प्रदर्शन के लिए डेटा को पठन-अनुकूलित संरचना में प्रतिलिपि बनाएं।
- इससे सुनिश्चित होता है कि भारी पठन प्रश्न लेखन क्रियाओं को अवरुद्ध नहीं करते।
इंडेक्सिंग और कुंजी चयन 📊
इंडेक्स प्रदर्शन के लिए महत्वपूर्ण हैं, लेकिन वे मुक्त नहीं हैं। प्रत्येक इंडेक्स को अपडेट के दौरान बनाए रखना होता है। यदि एक तालिका में बहुत अधिक इंडेक्स हैं, तो प्रत्येक इन्सर्ट या अपडेट के लिए कई इंडेक्स संरचनाओं को लॉक करने की आवश्यकता होती है।
क्लस्टर्ड बनाम नॉन-क्लस्टर्ड
- क्लस्टर्ड इंडेक्स: डेटा के भौतिक क्रम को निर्धारित करता है। आमतौर पर प्रत्येक तालिका में केवल एक होता है। इसे ध्यान से चुनें क्योंकि यह डेटा के संग्रहण के तरीके को प्रभावित करता है।
- नॉन-क्लस्टर्ड इंडेक्स: डेटा की ओर इशारा करने वाली एक अलग संरचना। मुख्य टेबल को छूए बिना प्रश्नों को कवर करने के लिए उपयोगी।
अक्सर अपडेट किए जाने वाले कॉलम पर इंडेक्स बनाने से बचें। जब किसी कॉलम का मान बदलता है, तो इंडेक्स को पुनर्निर्माण करना होता है। इस प्रक्रिया में इंडेक्स संरचना पर लिखने के लॉक बनते हैं।
कवरिंग इंडेक्स
एक कवरिंग इंडेक्स में एक प्रश्न के लिए आवश्यक सभी कॉलम शामिल होते हैं। इससे डेटाबेस को वास्तविक टेबल डेटा की खोज किए बिना अनुरोध को संतुष्ट करने में सक्षम होता है। इससे लॉक के दायरे को कम किया जाता है, क्योंकि इंजन को बेस टेबल की पंक्तियों को लॉक करने की आवश्यकता नहीं होती है।
- अक्सर पढ़े जाने वाले प्रश्नों की पहचान करें।
- वह इंडेक्स बनाएं जो शामिल करते हैं
SELECTकॉलम। - यह सुनिश्चित करने के लिए प्रश्न के निष्पादन योजनाओं को मॉनिटर करें कि इन इंडेक्स का उपयोग किया जा रहा है।
लेनदेन का दायरा और अलगाव ⏱️
ईआरडी लेनदेन के व्यवहार को प्रभावित करता है। लंबे समय तक चलने वाले लेनदेन लॉक को लंबे समय तक रखते हैं। अच्छी तरह से संरचित स्कीमा लेनदेन को छोटा रखने में मदद करता है।
बैच प्रोसेसिंग
एकल लेनदेन में हजारों पंक्तियों को प्रोसेस करने के बजाय, कार्य को छोटे बैच में बांटें। इससे लॉक जल्दी छूटते हैं, जिससे अन्य प्रक्रियाएं आगे बढ़ सकती हैं।
- प्रति कॉमिट में संशोधित पंक्तियों की संख्या को सीमित करें।
- डेटा को टुकड़ों में प्रोसेस करने के लिए कर्सर या लूप का उपयोग करें।
- बहुगुणा कॉमिट के ओवरहेड को कम लॉक अवधि के लाभ के बीच संतुलन बनाएं।
अलगाव स्तर
डेटाबेस प्रणालियां अलग-अलग अलगाव स्तर प्रदान करती हैं। उच्च अलगाव स्तर (जैसे सीरियलाइजेबल) अधिक अनोमालियों को रोकते हैं लेकिन लॉकिंग बढ़ाते हैं। निचले अलगाव स्तर (जैसे रीड कॉमिटेड) अधिक समानांतरता की अनुमति देते हैं।
- वित्तीय सटीकता के लिए सख्त रूप से आवश्यक होने पर ही सीरियलाइजेबल से बचें।
- अधिकांश संचालन कार्यों के लिए रीड कॉमिटेड या रिपीटेबल रीड का उपयोग करें।
- अलगाव स्तर को डेटा सुसंगतता के व्यावसायिक आवश्यकता के साथ मेल बैठाएं।
मॉनिटरिंग और आवर्धन 🔄
डिज़ाइन एक बार की गतिविधि नहीं है। जैसे-जैसे उपयोग के पैटर्न बदलते हैं, वैसे ही लॉक प्रतिस्पर्धा के मुद्दे भी बदलते हैं। प्रदर्शन बनाए रखने के लिए निरंतर मॉनिटरिंग आवश्यक है।
- वेट स्टैटिस्टिक्स: यह ट्रैक करें कि लेनदेन लॉक के लिए कितनी देर तक इंतजार करते हैं।
- डेडलॉक ग्राफ: आरेखों का विश्लेषण करें जो बताते हैं कि कौन से प्रश्न डेडलॉक के कारण बने।
- प्रश्न प्रदर्शन: धीमे प्रश्नों की पहचान करें जो अपेक्षा से अधिक समय तक लॉक रख सकते हैं।
वर्तमान प्रदर्शन मापदंडों के खिलाफ ईआरडी की नियमित समीक्षा करें। यदि कोई विशिष्ट टेबल निरंतर उच्च इंतजार समय दिखाती है, तो डेटा को पार्टीशन करने या स्कीमा को संशोधित करने के बारे में सोचें ताकि लोड कम किया जा सके।
डेटा आर्किटेक्चर पर अंतिम विचार 🧩
लॉक प्रतिस्पर्धा को कम करना डेटा अखंडता और सिस्टम थ्रूपुट के बीच संतुलन है। समानांतरता को ध्यान में रखते हुए स्कीमा डिज़ाइन करने से आप संघर्षों को हल करने के लिए डेटाबेस इंजन की आवश्यकता को कम करते हैं। इससे तेज़ प्रतिक्रिया समय और अधिक स्थिर सिस्टम मिलता है।
अपने वर्तमान संबंधों और कुंजियों के ऑडिट से शुरुआत करें। जॉइन को सरल बनाने और इंडेक्स ब्लॉट को कम करने के अवसरों की तलाश करें। लॉकिंग व्यवहार पर प्रभाव की पुष्टि करने के लिए अपने बदलावों का परीक्षण स्टेजिंग वातावरण में करें। सावधानी से योजना बनाने और विवरणों पर ध्यान देने के साथ, आप एक टिकाऊ डेटा परत बना सकते हैं जो प्रभावी ढंग से स्केल हो सकती है।