











डेटाबेस डिजाइन संतुलन का एक अभ्यास है। इसमें वास्तविक दुनिया के संबंधों को दर्शाते हुए डेटा को संरचित करने की आवश्यकता होती है, जबकि प्रदर्शन और अखंडता को बनाए रखना होता है। इस प्रक्रिया में एक सामान्य त्रुटि एंटिटी रिलेशनशिप आरेखों (ERD) के भीतर चक्रीय निर्भरता का जोड़ना है। ये लूप तब होते हैं जब विदेशी कुंजी संबंधों की श्रृंखला अंततः मूल एंटिटी की ओर लौटती है। अलग-अलग दृष्टिकोण से ऐसी संरचनाएं तार्किक लग सकती हैं, लेकिन डेटा प्रबंधन, प्रश्न अनुकूलन और प्रणाली स्थिरता के लिए उनमें महत्वपूर्ण चुनौतियां उत्पन्न करती हैं।
इन समस्याओं को हल करने के लिए संबंधात्मक सिद्धांत की गहन समझ और सावधानीपूर्वक आर्किटेक्चरल योजना की आवश्यकता होती है। यह मार्गदर्शिका चक्रीय निर्भरता के तकनीकी पहलुओं, डेटाबेस स्वास्थ्य पर उनके प्रभाव और अनुकूल प्रदर्शन के लिए स्कीमा को पुनर्गठित करने के सिद्ध रणनीतियों का अध्ययन करती है।
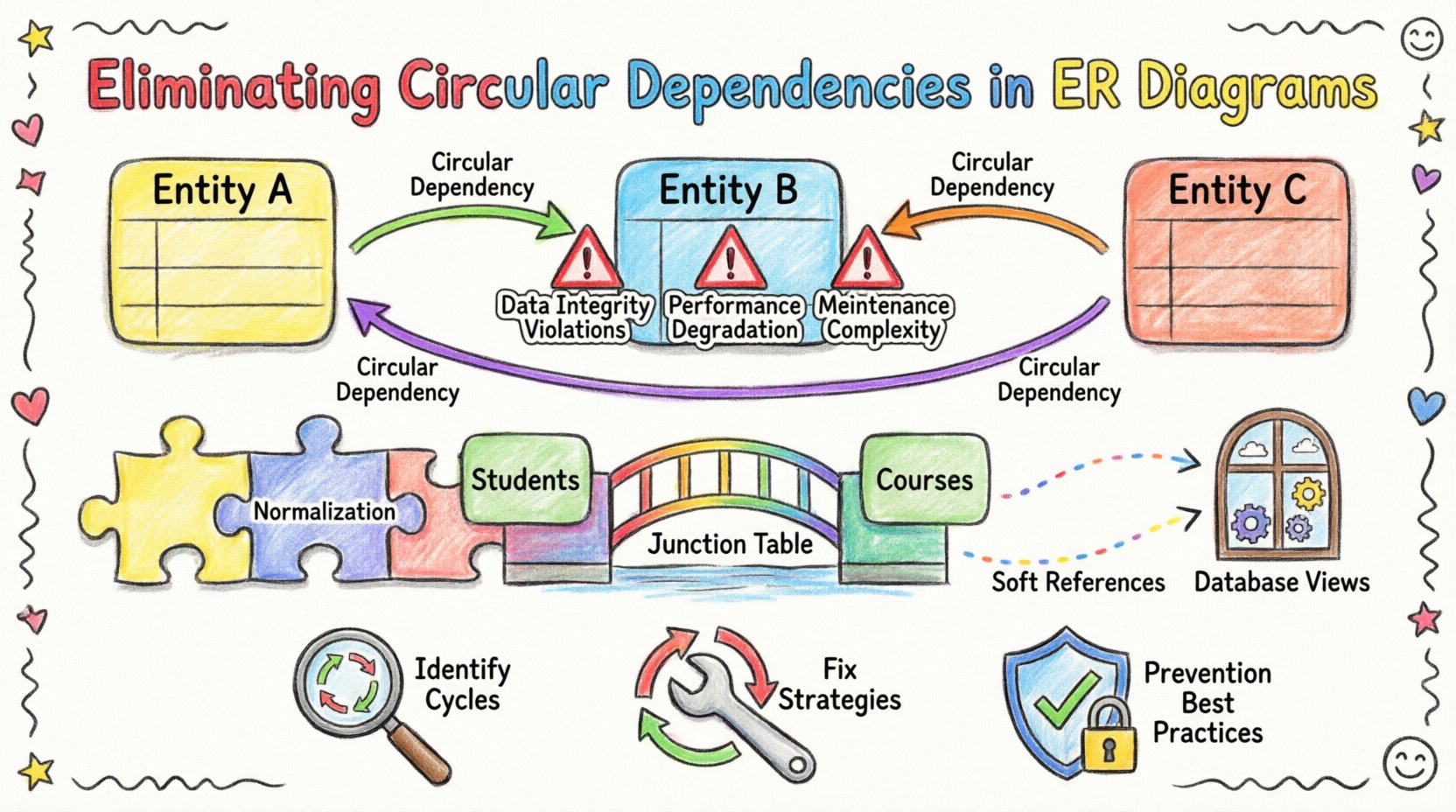
🧩 ERD में चक्रीय निर्भरता को समझना
एक मानक संबंधात्मक मॉडल में, एक विदेशी कुंजी प्रतिबंध एक बच्चे की तालिका से एक माता-पिता तालिका के बीच एक लिंक स्थापित करता है। यह लिंक संदर्भात्मक अखंडता को बनाए रखता है, जिससे यह सुनिश्चित होता है कि बच्चे की तालिका में डेटा माता-पिता तालिका में वैध प्रविष्टियों से मेल खाता है। जब इस श्रृंखला साफ तरीके से समाप्त नहीं होती है, तो चक्रीय निर्भरता उत्पन्न होती है। इसके बजाय, एंटिटी A एंटिटी B को संदर्भित करती है, जो एंटिटी C को संदर्भित करती है, जो अंततः एंटिटी A को संदर्भित करती है।
एक ऐसे परिदृश्य को ध्यान में रखें जिसमें एक पदानुक्रमिक संरचना हो। यदि एक वृक्ष में प्रत्येक नोड को अपने माता-पिता और अपने बच्चों के बारे में जानने की आवश्यकता हो, तो द्विदिश संबंध आसानी से लूप बना सकते हैं। सावधानीपूर्वक निपटान के बिना, डेटाबेस इंजन डेटा के इन्सर्ट या डिलीट के दौरान क्रम को निर्धारित नहीं कर पाता है।
चक्रीय संदर्भों के प्रकार
- सीधे चक्र:एंटिटी A में एंटिटी B के लिए एक विदेशी कुंजी है, और एंटिटी B में एंटिटी A के लिए विदेशी कुंजी है। यह द्विदिश संबंधों में अक्सर देखा जाता है, जहां दोनों ओर एक दूसरे को ट्रैक करती हैं।
- अप्रत्यक्ष चक्र:तीन या अधिक एंटिटी की श्रृंखला वापस लौटती है। उदाहरण के लिए, A → B → C → A। जटिल स्कीमा में इन्हें दृष्टिगत रूप से खोजना कठिन होता है।
- स्व-संदर्भित लूप:एक एंटिटी खुद को संदर्भित करती है। जबकि यह पदानुक्रमिक डेटा (जैसे कि एक कर्मचारी तालिका जहां एक प्रबंधक भी एक कर्मचारी है) में आम है, गलत कार्यान्वयन से अनंत पुनरावृत्ति का निर्माण हो सकता है।
⚠️ अनिर्णित लूप का प्रभाव
चक्रीय निर्भरताओं को अनिर्णित छोड़ना केवल एक सैद्धांतिक चिंता नहीं है। इससे एप्लिकेशन लेयर और डेटाबेस इंजन को वास्तविक जोखिम उत्पन्न होते हैं।
1. डेटा अखंडता उल्लंघन
जब डेटाबेस इंजन किसी चक्र में डेटा डालने की कोशिश करता है, तो इसे क्रियाओं के क्रम को निर्धारित करने की आवश्यकता होती है। यदि A के अस्तित्व के लिए B की आवश्यकता है, और B के अस्तित्व के लिए A की आवश्यकता है, तो न तो A को पहले बनाया जा सकता है और न ही B को। इससे प्रतिबंध उल्लंघन होते हैं। कुछ डेटाबेस प्रणालियां टली हुई प्रतिबंध जांच की अनुमति देती हैं, लेकिन इस विशेषता पर भरोसा करना अक्सर तर्क त्रुटियों को छिपा देता है।
2. प्रदर्शन में गिरावट
चक्रीय मार्गों को पार करने वाले प्रश्न अक्षम हो सकते हैं। एक चक्र में जॉइन ऑपरेशन ऑप्टिमाइज़र को उपयुक्त नहीं चयनित निष्पादन योजनाओं का चयन करने के लिए मजबूर कर सकते हैं। सबसे खराब स्थितियों में, पदानुक्रम को पार करने के लिए डिज़ाइन किए गए रिकर्सिव प्रश्न अनंत लूप में प्रवेश कर सकते हैं, जिससे CPU और मेमोरी संसाधन खपत होते हैं जब तक कनेक्शन समाप्त नहीं हो जाता।
3. रखरखाव की जटिलता
चक्रीय निर्भरताओं वाले स्कीमा को संशोधित करना जोखिम भरा है। यदि विदेशी कुंजियां सक्रिय हैं, तो चक्र में किसी तालिका को हटाने में विफलता हो सकती है। कैस्केडिंग डिलीट ऑपरेशन अप्रत्याशित श्रृंखला प्रतिक्रियाओं को उत्पन्न कर सकते हैं। विकासकर्ता अक्सर अपने एप्लिकेशन स्तर के तर्क लिखते हैं जो डेटाबेस प्रतिबंधों को बाहर करते हैं, जिससे अखंडता का बोझ स्रोत सत्य से हट जाता है।
🔍 चक्रीय निर्भरता की पहचान करना
समस्या को ठीक करने से पहले, आपको इसे खोजना होगा। छोटे आरेखों में दृष्टिगत जांच पर्याप्त होती है। सैकड़ों तालिकाओं वाले उद्योग-मानक प्रणालियों में, हाथ से ट्रेसिंग त्रुटि के लिए अधिक संवेदनशील होती है। अपने स्कीमा की समीक्षा करने के लिए निम्नलिखित तकनीकों का उपयोग करें।
- ग्राफ विश्लेषण:ERD को एक दिशात्मक ग्राफ के रूप में लें। नोड्स तालिकाओं का प्रतिनिधित्व करते हैं, और किनारे विदेशी कुंजियों का प्रतिनिधित्व करते हैं। यदि कोई पथ शुरुआती नोड पर वापस लौटता है, तो एक चक्र मौजूद है।
- निर्भरता वृक्ष:प्रत्येक तालिका के लिए एक निर्भरता वृक्ष बनाएं। यदि कोई तालिका वृक्ष में अपने ही पूर्वज के रूप में दिखाई देती है, तो एक चक्र मौजूद है।
- सिस्टम तालिकाओं को प्रश्न करना:अधिकांश डेटाबेस प्रबंधन प्रणालियां विदेशी कुंजी मेटाडेटा को सिस्टम कैटलॉग में संग्रहीत करती हैं। इन संबंधों को प्रोग्रामेटिक रूप से पार करने के लिए प्रश्न लिखें।
🛠️ समाधान के लिए रणनीतियां
जब पहचान ली जाती है, तो चक्रीय निर्भरताओं को तोड़ना होता है। लक्ष्य एक भौतिक लूप बनाए बिना तार्किक संबंध को बनाए रखना है। इसे प्राप्त करने के लिए नीचे मुख्य तरीके दिए गए हैं।
1. स्कीमा को सामान्यीकृत करें
सामान्यीकरण डेटा को व्यवस्थित करने की प्रक्रिया है जिससे अतिरिक्तता कम होती है और अखंडता में सुधार होता है। अक्सर, चक्रीय निर्भरताएं एकल स्तर के सारांश में नहीं फिट होने वाले संबंधों के मॉडलिंग के प्रयास से उत्पन्न होती हैं।
- तृतीय सामान्य रूप (3NF):सुनिश्चित करें कि गैर-कुंजी विशेषताएं केवल मुख्य कुंजी पर निर्भर हों। यदि किसी तालिका में एक विशेष विन्यास को दर्शाने के लिए खुद पर एक विदेशी कुंजी है, तो विशेष विन्यास के तर्क को अलग संबंध तालिका में अलग करने के बारे में सोचें।
- अतिरिक्तता हटाएं:यदि एंटिटी A और एंटिटी B दोनों एक दूसरे को संदर्भित करती हैं, तो पूछें कि क्या उनमें से एक संदर्भ अतिरिक्त है। क्या संबंध केवल एक दिशा में दर्शाया जा सकता है?
2. जंक्शन तालिका पेश करें
बहु-से-बहु संबंध चक्रीय लूप का एक आम स्रोत हैं। मुख्य एंटिटी में विदेशी कुंजियों को सीधे रखने के बजाय, एक मध्यवर्ती तालिका का उपयोग करें।
उदाहरण के लिए, यदिछात्र औरपाठ्यक्रमके बीच बहु-से-बहु संबंध है, तो कृपया एकपाठ्यक्रम_idकोछात्रतालिका में और एकछात्र_idकोपाठ्यक्रमतालिका में। इसके बजाय, एकपंजीकरणतालिका बनाएं जो दोनों कुंजियों को संग्रहीत करती है। इससे दो मुख्य एंटिटी के बीच सीधा संबंध तोड़ दिया जाता है।
3. तार्किक संबंधों के लिए दृश्यों का उपयोग करें
कभी-कभी, भौतिक भंडारण को तार्किक आवश्यकता की छवि नहीं बनानी होती है। यदि एप्लिकेशन को A और B के बीच संबंध देखने की आवश्यकता है, लेकिन इसे सीधे भंडारित करने से एक चक्र बनता है, तो डेटाबेस दृश्य का उपयोग करें।
- भौतिक मॉडल:A और B को सीधे विदेशी कुंजी लिंक के बिना भंडारित करें।
- तार्किक मॉडल:एक दृश्य बनाएं जो A और B को एक सामान्य विशेषता या अलग संबंध तालिका के आधार पर जोड़ता है।
यह स्टोरेज सीमाओं को एप्लिकेशन लॉजिक से अलग करता है, जिससे डेटाबेस को तब इंटीग्रिटी को लागू करने की अनुमति मिलती है जब यह महत्वपूर्ण होता है, बिना भौतिक लूप बनाए।
4. सॉफ्ट संदर्भों का कार्यान्वयन करें
कुछ मामलों में, संबंध के लिए सख्त रेफरेंशियल इंटीग्रिटी की आवश्यकता नहीं होती है। आप संबंधित एंटिटी के ID को विदेशी कुंजी सीमा के बजाय सामान्य पूर्णांक कॉलम के रूप में संग्रहीत कर सकते हैं।
- लाभ: इन्सर्ट/डिलीट के दौरान सीमा जांच हटा देता है, जिससे लूप को भौतिक रूप से ब्लॉक किए बिना अस्तित्व में रहने दिया जाता है।
- नुकसान: डेटाबेस अब संबंध को लागू नहीं करता है। एप्लिकेशन लॉजिक को यह सत्यापित करना होगा कि संदर्भित ID मौजूद है।
📊 रिफैक्टरिंग दृष्टिकोणों की तुलना
| दृष्टिकोण | जटिलता | इंटीग्रिटी लागू करना | सर्वोत्तम उपयोग केस |
|---|---|---|---|
| नॉर्मलाइजेशन | उच्च | पूर्ण | जब डेटा अतिरेक जड़ कारण हो। |
| जंक्शन टेबल | मध्यम | पूर्ण | बहु-से-बहु संबंध। |
| व्यूज | निम्न | आंशिक (प्रश्न स्तर पर) | रिपोर्टिंग या पढ़ने पर अधिक निर्भर कार्यभार। |
| सॉफ्ट संदर्भ | निम्न | कोई नहीं (एप्लिकेशन स्तर पर) | पुराने प्रणाली या वैकल्पिक संबंध। |
🛡️ रोकथाम और बेस्ट प्रैक्टिसेज
जब एक स्कीमा को रिफैक्टर कर लिया जाता है, तो ध्यान भविष्य के चक्करों को रोकने की ओर बदल जाता है। डिज़ाइन पैटर्न और गवर्नेंस प्रक्रियाएं इन समस्याओं को फिर से लाने के जोखिम को कम कर सकती हैं।
1. संबंध दिशा को परिभाषित करें
एक नियम स्थापित करें कि विदेशी कुंजियाँ हमेशा एक निश्चित दिशा में प्रवाहित होनी चाहिए। उदाहरण के लिए, बच्चे की तालिकाएँ हमेशा माता-पिता को संदर्भित करती हैं, कभी भी विपरीत नहीं। यदि माता-पिता को बच्चे के डेटा तक पहुँच की आवश्यकता है, तो विदेशी कुंजी के बजाय क्वेरी या दृश्य का उपयोग करें।
2. हायरार्की को सावधानी से मॉडल करें
स्व-संदर्भित तालिकाएँ संगठनात्मक चार्ट या कमेंट प्रवाह के लिए सामान्य हैं। लूप से बचने के लिए:
- केवल माता-पिता: केवल संग्रहीत करें
माता-पिता_आईडी. संग्रहीत न करेंबच्चे_आईडीजउसी पंक्ति में। - पाथ संख्याकरण: गहन हायरार्की के लिए, पूर्ण पाथ स्ट्रिंग संग्रहीत करें (उदाहरण के लिए,
/1/5/9/) ताकि रिकर्सिव जॉइन्स के बिना तेजी से क्वेरी करने की अनुमति मिले।
3. स्वचालित स्कीमा ऑडिट
साइकिल डिटेक्शन को CI/CD पाइपलाइन में एकीकृत करें। स्क्रिप्ट स्कीमा परिभाषा फ़ाइलों (जैसे SQL माइग्रेशन स्क्रिप्ट) को पार्स कर सकती हैं और डेप्लॉयमेंट से पहले किसी भी नए विदेशी कुंजी परिभाषा को चिह्नित कर सकती हैं जो एक लूप बनाती है।
4. दस्तावेज़ीकरण
एक अद्यतन ERD बनाए रखें। जब कोई डेवलपर एक तालिका जोड़ता है, तो वह आरेख को अद्यतन करना चाहिए। यह दृश्य सहायता कोड लिखे जाने से पहले संभावित साइकिलों की पहचान करने में मदद करती है। बड़ी टीमों के लिए डेटाबेस स्कीमा से स्वचालित दस्तावेज़ीकरण बनाने वाले टूल्स की अत्यधिक सिफारिश की जाती है।
🔄 लीगेसी सिस्टम का प्रबंधन
उत्पादन डेटाबेस के रिफैक्टरिंग को डाउनटाइम लागत या डेटा आयतन के कारण हमेशा संभव नहीं होता है। इस मामले में एक चरणबद्ध दृष्टिकोण आवश्यक है।
- महत्वपूर्ण मार्गों की पहचान करें: उन साइकिलों को तोड़ने का प्राथमिकता दें जो सबसे अधिक उपयोग किए जाने वाले प्रश्नों को प्रभावित करती हैं।
- एप्लीकेशन लॉजिक का उपयोग करें: संबंध प्रबंधन को अस्थायी रूप से एप्लीकेशन लेयर में स्थानांतरित करें। आईडी को सामान्य कॉलम के रूप में संग्रहीत करें और कोड में उनकी पुष्टि करें।
- माइग्रेशन की योजना बनाएं: जब नई संरचना स्थिर हो जाए, तो एप्लीकेशन-लेवल संदर्भों को भौतिक प्रतिबंधों में बदलने के लिए एक रखरखाव खंड स्थापित करें।
📝 स्कीमा स्वास्थ्य के लिए अंतिम विचार
एक साफ़ ERD एक विश्वसनीय एप्लीकेशन की नींव है। वृत्ताकार निर्भरता एक डिज़ाइन का लक्षण है जिसने सुविधा को संरचना की तुलना में प्राथमिकता दी है। नॉर्मलाइजेशन सिद्धांतों का पालन करने और उचित स्थानों पर जंक्शन तालिकाओं का उपयोग करने से आप यह सुनिश्चित कर सकते हैं कि आपके डेटा की सुसंगतता बनी रहे और उस पर प्रश्न किए जा सकें।
याद रखें कि डेटाबेस डिज़ाइन एक चक्रीय प्रक्रिया है। जैसे-जैसे व्यापार आवश्यकताएँ विकसित होती हैं, संबंध बदलते हैं। नियमित रूप से अपने स्कीमा की समीक्षा करें ताकि यह अभी भी आपके लक्ष्यों के अनुरूप रहे। निरंतर मान्यता और विदेशी कुंजियों के प्रति अनुशासित दृष्टिकोण आपकी संरचना को बढ़ती डेटा आवश्यकताओं की जटिलता के खिलाफ लचीला रखेगा।