











डेटाबेस स्कीमा डिज़ाइन करना आमतौर पर गति और संरचना के बीच द्विआधारी चयन नहीं होता है। यह एक समझौते का अभ्यास है। जब वास्तुकार एंटिटी-रिलेशनशिप आरेख (ERD) बनाते हैं, तो वे अक्सर सख्त डेटा अखंडता और उच्च आयतन एप्लिकेशनों के लिए आवश्यक बेसी गति के बीच तनाव का सामना करते हैं। नॉर्मलाइजेशन अतिरेक को कम करता है, जिससे डेटा संगत बना रहता है। हालांकि, इस संगतता को बनाए रखने की कीमत अक्सर पढ़ने के प्रदर्शन में चुकाई जाती है।
यह लेख इस संतुलन के तकनीकी बारीकियों का अध्ययन करता है। हम देखेंगे कि नॉर्मलाइजेशन जॉइन्स को कैसे प्रभावित करता है, पढ़ने पर आधारित कार्यभार की ओर स्कीमा परिवर्तन कैसे निर्देशित करते हैं, और एक अच्छी तरह से संरचित डेटाबेस और एक प्रदर्शन वाले डेटाबेस के बीच कहाँ रेखा खींची जाती है।
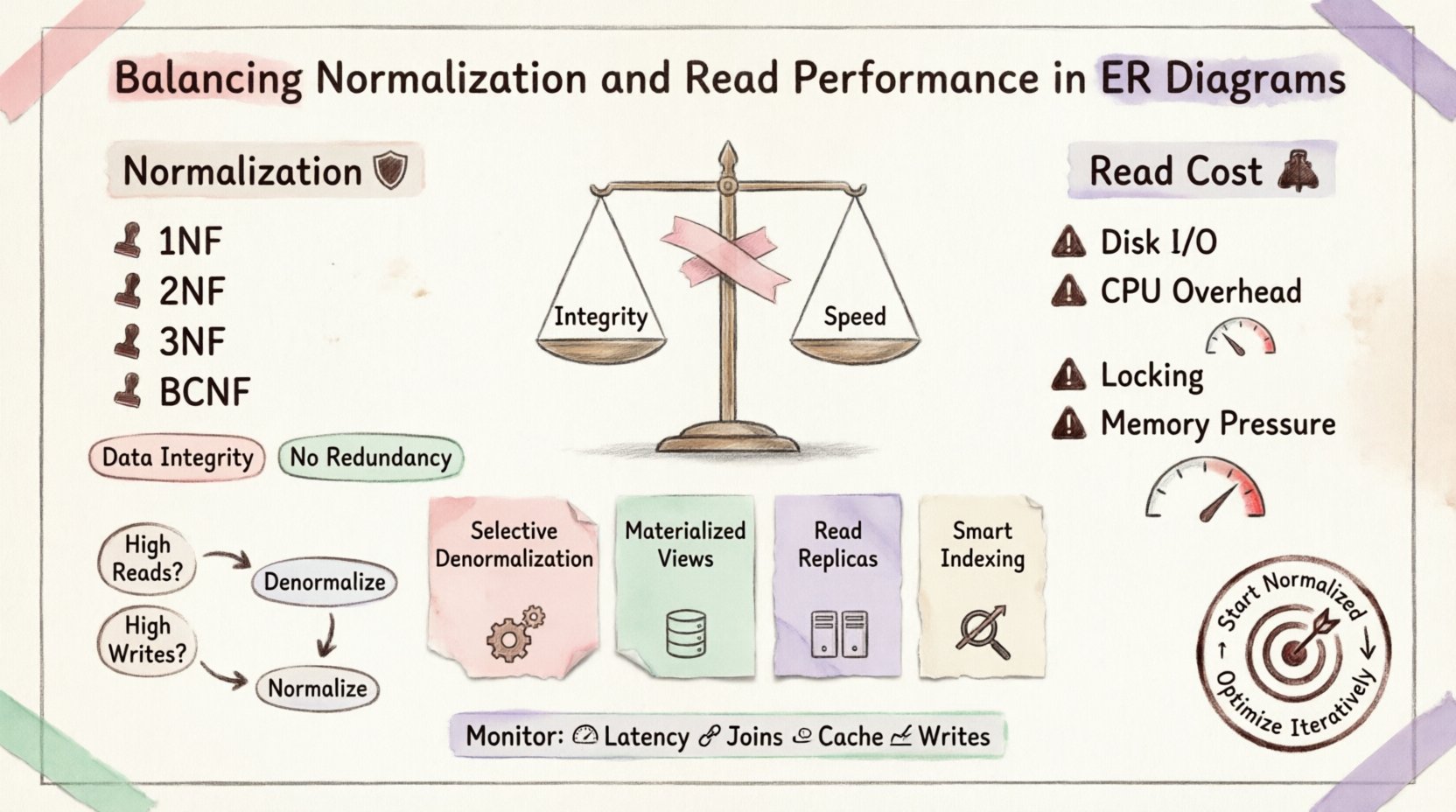
नॉर्मलाइजेशन को समझना: आधार 🛡️
नॉर्मलाइजेशन डेटा को अतिरेक को कम करने और डेटा अखंडता में सुधार करने के लिए व्यवस्थित करने की प्रक्रिया है। इसमें बड़ी तालिकाओं को छोटी, तार्किक तालिकाओं में विभाजित करना और उनके बीच संबंध निर्धारित करना शामिल है। लक्ष्य इन्सर्शन, अपडेट और डिलीट के दौरान असंगतियों को दूर करना है।
मुख्य नॉर्मल रूप
-
पहला सामान्य रूप (1NF):परमाणुता सुनिश्चित करता है। प्रत्येक कॉलम में केवल एक मान होता है। कोई भी दोहराए गए समूह नहीं हैं।
-
दूसरा सामान्य रूप (2NF):1NF पर आधारित है। सभी गैर-की विशेषताएं मुख्य की पर पूर्ण निर्भरता होनी चाहिए। आंशिक निर्भरताओं को हटाता है।
-
तीसरा सामान्य रूप (3NF):2NF पर आधारित है। स्थानांतरित निर्भरताओं को हटाता है। गैर-की विशेषताएं केवल की, पूरी की और केवल की पर निर्भर होती हैं।
-
बॉयस-कॉड सामान्य रूप (BCNF):विशिष्ट निर्भरता विचलनों को संभालने के लिए 3NF का कठोर संस्करण।
इन रूपों का पालन करने से एक साफ डेटाबेस की गारंटी मिलती है, लेकिन यह प्रश्न पूछने में जटिलता लाता है। ER आरेख में परिभाषित प्रत्येक संबंध एक संभावित जॉइन संचालन बन जाता है।
पढ़ने की कीमत 💸
जब आप डेटा को नॉर्मलाइज़ करते हैं, तो आप आमतौर पर जानकारी को कई तालिकाओं में विभाजित कर देते हैं। एक पूर्ण रिकॉर्ड प्राप्त करने के लिए, डेटाबेस इंजन को जॉइन संचालन करने की आवश्यकता होती है। जॉइन्स कंप्यूटेशनल रूप से महंगे होते हैं।
जॉइन्स क्यों प्रश्नों को धीमा करते हैं
-
डिस्क I/O:यदि तालिकाओं को पूरी तरह से सूचीबद्ध या कैश किया गया है, तो इंजन को डिस्क पर अलग-अलग भौतिक स्थानों पर डेटा खोजना होगा।
-
CPU ओवरहेड:डेटाबेस को एक तालिका से दूसरी तालिका में कीज़ को मैच करना होता है। इसके लिए महत्वपूर्ण प्रोसेसिंग शक्ति की आवश्यकता होती है।
-
लॉकिंग प्रतिस्पर्धा:जटिल जॉइन्स लॉक्स को लंबे समय तक रख सकते हैं, जिससे अन्य लेनदेन संबंधित डेटा तक पहुंचने से रोके जाते हैं।
-
मेमोरी दबाव:बड़े जॉइन संचालनों के लिए डेटा को क्रमबद्ध और हैश करने के लिए बड़े मेमोरी बफर की आवश्यकता होती है।
पढ़ने पर आधारित वातावरण में, जैसे कि रिपोर्टिंग डैशबोर्ड या सार्वजनिक एपीआई में, यह लेटेंसी अस्वीकार्य है। उपयोगकर्ता तुरंत प्रतिक्रिया की अपेक्षा करते हैं। एक प्रश्न जो नॉर्मलाइज्ड डेटा लौटाने में 100 मिलीसेकंड लेता है, यदि डेनॉर्मलाइज्ड हो, तो केवल 10 मिलीसेकंड में लौट सकता है।
अनुकूलन के लिए रणनीतियाँ 🚀
अखंडता और गति के बीच संतुलन बनाए रखने के लिए, वास्तुकार विशिष्ट पैटर्न का उपयोग करते हैं। इन रणनीतियों के माध्यम से आप डेटाबेस को वहां नॉर्मलाइज्ड रख सकते हैं जहां यह सबसे ज्यादा महत्वपूर्ण है, जबकि पढ़ने के लिए जहां यह महत्वपूर्ण है, उसके लिए अनुकूलित कर सकते हैं।
1. चयनात्मक डेनॉर्मलाइजेशन
सभी तालिकाओं को पूरी तरह से सामान्यीकृत करने की आवश्यकता नहीं है। सबसे अधिक प्राप्त किए जाने वाले डेटा की पहचान करें और उसे बहुलक रूप से संग्रहित करें। उदाहरण के लिए, यदि आप अक्सर उपयोगकर्ता नामों के साथ उनके आदेश इतिहास के साथ प्रश्न पूछते हैं, तो आदेश तालिका में उपयोगकर्ता नाम को सीधे संग्रहित करने से जॉइन करने की आवश्यकता बचती है।
2. सामग्री दृश्य
एक सामग्री दृश्य डिस्क पर एक प्रश्न के परिणाम को भौतिक रूप से संग्रहित करता है। यह मूल रूप से एक पूर्व-गणना की गई तालिका है। जब डेटा में परिवर्तन होता है, तो दृश्य को ताजा करने की आवश्यकता होती है। यह जटिल संघननों के लिए आदर्श है जिन्हें वास्तविक समय की सटीकता की आवश्यकता नहीं होती है।
3. पठन प्रतिकृतियाँ
पठन कार्यभार को लेखन कार्यभार से अलग करें। सभी लेखन संचालन को मुख्य डेटाबेस में निर्देशित करें, जो सामान्यीकृत रहता है। सभी पठन संचालन को एक प्रतिकृति में निर्देशित करें। इससे प्रतिकृति को अलग तरीके से अनुकूलित करने की अनुमति मिलती है, शायद अधिक सूचकांकों या असामान्य संरचनाओं के साथ, बिना लेनदेन की अखंडता के प्रभावित किए बिना।
4. सूचकांक रणनीति
सामान्यीकृत डेटाबेस भी सही सूचकांकों के साथ अच्छा प्रदर्शन कर सकते हैं। कवरिंग सूचकांक डेटाबेस को केवल सूचकांक का उपयोग करके एक प्रश्न को संतुष्ट करने की अनुमति देते हैं, तालिका खोज से बचने के लिए। संयुक्त सूचकांक सामान्य विदेशी कुंजियों पर जॉइन को तेज कर सकते हैं।
जब असामान्यीकरण करें 📉
असामान्यीकरण एक जानबूझकर निर्णय है, एक डिफ़ॉल्ट स्थिति नहीं है। इसे प्रदर्शन निगरानी से प्राप्त साक्ष्य के आधार पर किया जाना चाहिए, अनुमानों के आधार पर नहीं।
|
परिदृश्य |
प्रक्रिया |
तर्क |
|---|---|---|
|
उच्च लेखन आवृत्ति |
सामान्यीकृत रखें |
अपडेट तेज होते हैं। बनाए रखने के लिए कम अतिरिक्तता। |
|
उच्च पठन आवृत्ति |
असामान्यीकरण के बारे में सोचें |
जॉइन कम करता है। तेजी से प्राप्ति समय। |
|
डेटा सुसंगतता महत्वपूर्ण है |
सामान्यीकृत रखें |
एकमात्र सत्य का स्रोत डेटा विचलन को रोकता है। |
|
रिपोर्टिंग और विश्लेषण |
असामान्यीकृत करें |
संघनन जटिल हैं; पूर्व-गणना मदद करती है। |
|
स्केलेबिलिटी की आवश्यकता |
हाइब्रिड दृष्टिकोण |
सेवाओं को विभाजित करें या कैशिंग परतों का उपयोग करें। |
ट्रेड-ऑफ: डेटा अखंडता बनाम गति ⚙️
हर बार जब आप अतिरिक्तता लाते हैं, तो आप डेटा असंगति के जोखिम में डालते हैं। यदि उपयोगकर्ता अपना ईमेल पता बदलता है, लेकिन ईमेल दोनों स्थानों पर संग्रहित है, तोउपयोगकर्ता टेबल और वह सूचनाएँ टेबल, एक अपडेट विफल हो सकती है या छूट जा सकती है। इसे अपडेट विचलन के रूप में जाना जाता है।
इसके निवारण के लिए, एप्लिकेशन लॉजिक को मजबूत होना चाहिए। ट्रिगर सुसंगतता को लागू कर सकते हैं, लेकिन वे जटिलता बढ़ाते हैं। वैकल्पिक रूप से, स्कीमा को इस तरह डिज़ाइन करें कि डेनॉर्मलाइज़्ड डेटा निर्मित और अपरिवर्तनीय हो, जिससे विचलन के जोखिम को कम किया जा सके।
सुसंगतता का प्रबंधन
-
एप्लिकेशन-स्तरीय तर्क: सभी अतिरिक्त प्रतियों को परमाणु रूप से अपडेट करने वाला कोड लिखें।
-
डेटाबेस ट्रिगर्स: डेटाबेस को नियमों को स्वचालित रूप से लागू करने दें। इससे तर्क डेटा के पास रहता है।
-
अंततः सुसंगतता: यह स्वीकार करें कि डेटा एक छोटे समय के लिए पुराना हो सकता है। अतिरिक्त डेटा को सिंक करने के लिए बैकग्राउंड जॉब्स का उपयोग करें।
निगरानी और रखरखाव 🔧
एक स्थिर डिज़ाइन बदलते उपयोग पैटर्न को ध्यान में नहीं रखता है। आज काम करने वाला कुछ अगले साल बैंडविड्थ की समस्या बन सकता है। निरंतर निगरानी आवश्यक है।
ट्रैक करने वाले मुख्य मापदंड
-
प्रश्न लेटेंसी: महत्वपूर्ण पढ़ने वाले प्रश्नों के लिए लिए लिया गया समय ट्रैक करें।
-
जॉइन काउंट: प्रत्येक जटिल प्रश्न में जॉइन की संख्या को ट्रैक करें।
-
कैश हिट अनुपात: यदि आप कैशिंग का उपयोग करते हैं, तो जांचें कि क्या यह डेटाबेस लोड को प्रभावी ढंग से कम कर रहा है।
-
लेखन लेटेंसी: सुनिश्चित करें कि डेनॉर्मलाइज़ेशन लेखन को बहुत धीमा नहीं कर रहा है।
निष्कर्ष: एक संदर्भ-आधारित निर्णय 🎯
डेटाबेस डिज़ाइन के लिए कोई सार्वभौमिक मानक नहीं है। सबसे अच्छा ईआर डायग्राम वह है जो आपके विशिष्ट लोड के अनुरूप हो। नॉर्मलाइज़ेशन सुरक्षा प्रदान करता है; डेनॉर्मलाइज़ेशन गति प्रदान करता है। लक्ष्य संतुलन बिंदु खोजना है।
डेटा अखंडता सुनिश्चित करने के लिए नॉर्मलाइज़्ड डिज़ाइन से शुरुआत करें। जैसे ही प्रदर्शन की समस्याएँ उभरें, विलंब के कारण विशिष्ट प्रश्नों की पहचान करें। केवल उन क्षेत्रों में डेनॉर्मलाइज़ेशन या कैशिंग लागू करें। इस आवर्ती दृष्टिकोण से प्रीमेच्योर ऑप्टिमाइज़ेशन से बचा जाता है और यह सुनिश्चित किया जाता है कि प्रणाली समय के साथ बनाए रखी जा सके।
याद रखें कि तकनीक विकसित होती है। नए स्टोरेज इंजन और प्रश्न अनुकूलक जॉइन की लागत को कम करने के लिए जारी हैं। अपने स्कीमा की वर्तमान क्षमताओं के अनुसार नियमित रूप से समीक्षा करें। संतुलन बदलता है, और आपके डिज़ाइन को इसके साथ बदलना चाहिए।
नॉर्मलाइज़ेशन के तकनीकी पहलुओं और पढ़ने के प्रदर्शन की वास्तविकताओं को समझकर आप ऐसी प्रणालियाँ बना सकते हैं जो दोनों मजबूत और प्रतिक्रियाशील हों। डेटा पर ध्यान केंद्रित करें, केवल कोड पर नहीं।