











संबंधात्मक डेटाबेस तालिकाओं और पंक्तियों पर आधारित होते हैं, जो समतल डेटा के लिए डिज़ाइन की गई संरचना है। हालांकि, वास्तविक दुनिया ऐसी सरलता का अनुसरण करने वाली बहुत कम होती है। संगठन, फाइल प्रणालियाँ, कमेंट धागे और श्रेणी वृक्ष सभी में पदानुक्रमिक संरचनाएँ। एक मानक एंटिटी रिलेशनशिप आरेख (ईआरडी) में इन माता-पिता बच्चा संबंधों का प्रतिनिधित्व करने के लिए विशिष्ट डिज़ाइन पैटर्न की आवश्यकता होती है, जो डेटा अखंडता को बनाए रखते हुए कुशल पुनर्प्राप्ति की अनुमति देते हैं।
जब आप एक वृक्ष संरचना को समतल स्कीमा पर मानचित्रित करने की कोशिश करते हैं, तो आप नॉर्मलाइजेशन और प्रदर्शन के बीच पारंपरिक तनाव का सामना करते हैं। यह गाइड पदानुक्रमिक डेटा के मॉडलिंग के मुख्य तकनीकों का अध्ययन करता है, प्रत्येक दृष्टिकोण के लाभ-हानि का मूल्यांकन करके आपको टिकाऊ प्रणालियों के डिज़ाइन करने में मदद करता है।
🧩 समतल स्कीमा की चुनौती
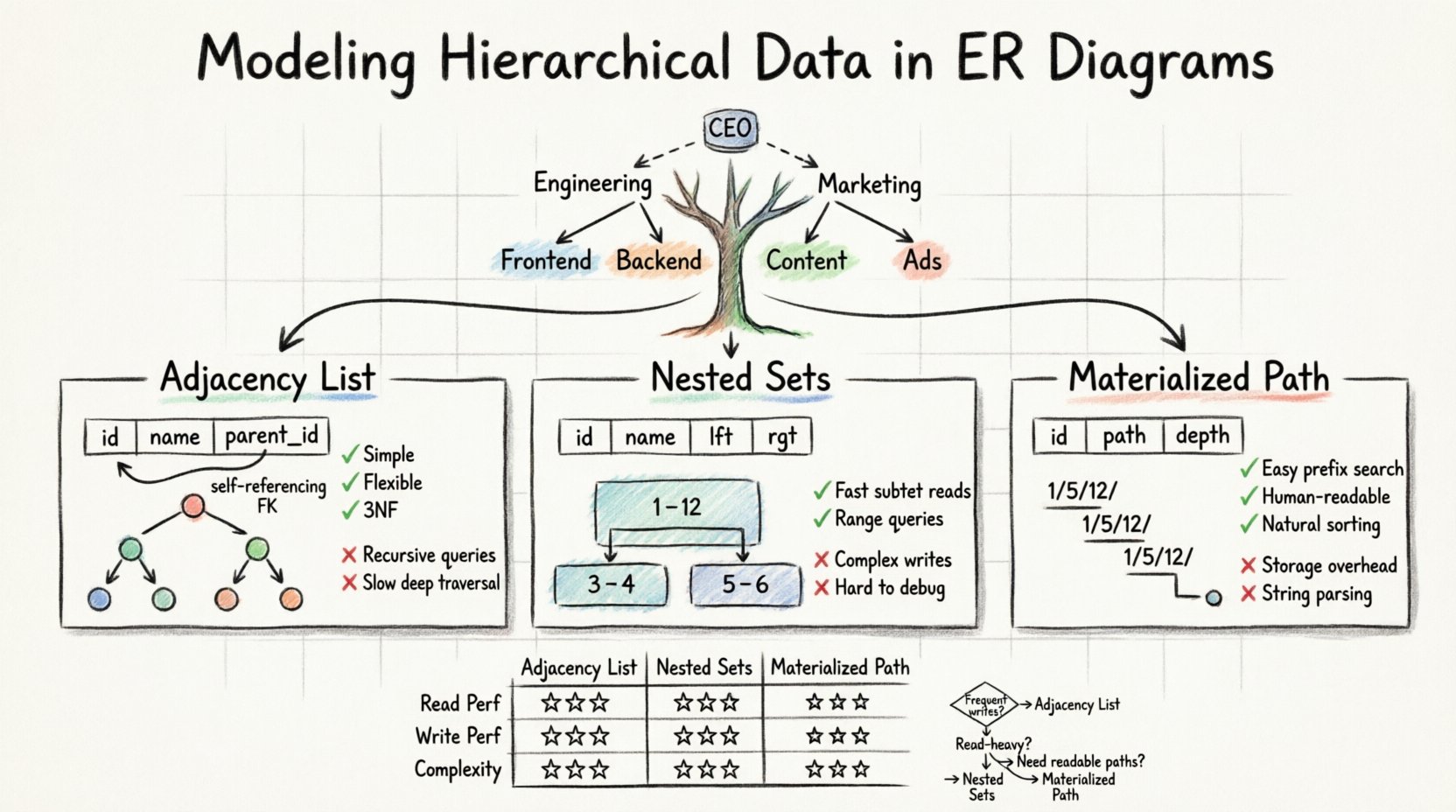
एक एंटिटी रिलेशनशिप आरेख आमतौर पर एंटिटी को बॉक्स के रूप में और संबंधों को रेखाओं के रूप में दर्शाता है। एक मानक संबंध में, एक तालिका एक विदेशी कुंजी के माध्यम से दूसरी तालिका से जुड़ती है। यह बहु-से-बहु या एक-से-बहु परिदृश्य में पूरी तरह से काम करता है जहां दिशा निश्चित होती है। लेकिन जब एक श्रेणी में उप-श्रेणियाँ हो सकती हैं, जो उप-उप-श्रेणियों को भी जन्म दे सकती हैं, जो संभवतः अनंत तक जाती हैं, तो क्या होता है?
मानक संबंधात्मक मॉडल चर गहराई के साथ कठिनाई में हैं। एक समतल तालिका एक अनिश्चित लंबाई के मार्ग को आसानी से संग्रहीत नहीं कर सकती है। इस समस्या को हल करने के लिए, हमें स्कीमा को बदलकर पदानुक्रम को स्पष्ट रूप से संग्रहीत करने की आवश्यकता होती है। डेटा वास्तुकार इस उद्देश्य को प्राप्त करने के लिए तीन मुख्य पैटर्न का उपयोग करते हैं:
- पड़ोसी सूची:बच्चे के रिकॉर्ड के भीतर माता-पिता के आईडी को संग्रहीत करना।
- नेस्टेड सेट्स:रेंज को परिभाषित करने के लिए बाएँ और दाएँ मान निर्धारित करना।
- मार्ग संख्यांकन:मूल से वर्तमान नोड तक पूर्ण मार्ग को संग्रहीत करना।
🔗 पड़ोसी सूची मॉडल
पड़ोसी सूची मानक ईआरडी में पदानुक्रम का प्रतिनिधित्व करने का सबसे आम और सीधा तरीका है। इसका आधार एक स्व-संदर्भित संबंध पर है। इसका अर्थ है कि एक ही तालिका में एक कॉलम होता है जो अपने ही मुख्य कुंजी को संदर्भित करता है।
📐 स्कीमा संरचना
इस मॉडल में, आप डेटा संग्रहीत करने के लिए एक ही तालिका बनाते हैं। प्रत्येक पंक्ति वृक्ष में एक नोड का प्रतिनिधित्व करती है। महत्वपूर्ण जोड़ एक कॉलम है, जिसे अक्सर नामित किया जाता है माता-पिता_आईडी या पूर्वज_आईडीजो माता-पिता नोड की अद्वितीय पहचान को संग्रहीत करता है। यदि कोई नोड पदानुक्रम के शीर्ष पर है, तो इस कॉलम में नॉल मान होता है।
मान लीजिए एक तालिका के लिए विभाग:
- आईडी:विभाग के लिए अद्वितीय मुख्य कुंजी।
- नाम:विभाग का प्रदर्शन नाम।
- माता-पिता_आईडी: उच्च विभाग का पहचान संख्या (शीर्ष स्तर के लिए खाली छोड़ सकते हैं)।
✅ लाभ
- सरलता: स्कीमा विकासकर्ताओं और डेटाबेस प्रबंधकों के लिए स्पष्ट और समझने में आसान है।
- लचीलापन: एक उप-वृक्ष को हटाना सरल है; आपको केवल
माता-पिता_आईडीउस उप-वृक्ष के मूल नोड को अपडेट करने की आवश्यकता होती है। - नॉर्मलीकरण: डेटा की दोहराव नहीं होती है, इसलिए यह तृतीय सामान्य रूप (3NF) का अच्छी तरह से पालन करता है।
❌ कमियाँ
- प्रश्न की जटिलता: सभी प्रतिनिधियों को प्राप्त करने के लिए आवर्धित प्रश्नों या एप्लिकेशन साइड प्रोसेसिंग की आवश्यकता होती है।
- प्रदर्शन: विशिष्ट इंडेक्सिंग रणनीतियों या आवर्धित सामान्य तालिका अभिव्यक्तियों (CTEs) के बिना गहन यात्राएँ धीमी हो सकती हैं।
- संदर्भात्मक अखंडता: जबकि विदेशी कुंजियाँ मदद करती हैं, यदि नियमों को सख्ती से लागू नहीं किया जाता है तो चक्रीय संदर्भ अभी भी हो सकते हैं।
🌲 नेस्टेड सेट मॉडल
नेस्टेड सेट मॉडल वृक्ष संरचना को अंतरालों के सेट में बदल देता है। माता-पिता के संकेतक के बजाय, प्रत्येक नोड को दो संख्याएँ निर्धारित की जाती हैं: बाएँ और दाएँ। इन मानों का अर्थ वृक्ष के पूर्व-क्रम अनुक्रमण में नोड की स्थिति होती है।
📐 स्कीमा संरचना
एक वृक्ष की कल्पना करें जहाँ मूल नोड पूरी सेट है। जैसे ही आप वृक्ष के माध्यम से यात्रा करते हैं, आप एक गिनती बढ़ाते हैं। जब आप किसी नोड में प्रवेश करते हैं, तो आप वर्तमान गिनती को बाएँ के रूप में रिकॉर्ड करते हैं। जब आप उस नोड और उसके सभी बच्चों को प्रोसेस कर लेते हैं, तो आप गिनती को दाएँ के रूप में रिकॉर्ड करते हैं। द दाएँ मान हमेशा उससे अधिक होता हैबाएं मान।
एक श्रेणी तालिका इस तरह दिखेगी:
- पहचान: एकल पहचानकर्ता।
- नाम: श्रेणी का नाम।
- बाएं: बाएं सीमा मान।
- दाएं: दाएं सीमा मान।
✅ लाभ
- तेजी से प्राप्त करना: उप-वृक्ष प्राप्त करना एक सरल सीमा प्रश्न है जिसमें
बीचतर्क का उपयोग करके। - कार्यक्षमता: अनुक्रमण सूचियों की तुलना में बड़े, गहन वृक्षों के लिए पठन प्रदर्शन उत्कृष्ट है।
❌ कमियां
- लेखन लागत: नोड को डालना या हटाना महंगा है। आपको
बाएंऔरदाएंअंतरालों की अखंडता बनाए रखने के लिए कई अन्य नोड्स के मान को अपडेट करना होगा। - जटिलता: निर्दिष्ट लाइब्रेरी समर्थन के बिना इस तर्क को लागू करना और डीबग करना कठिन है।
🛣️ पथ संख्यांकन और सामग्रीकृत पथ
पथ संख्यांकन विधियाँ एक नोड की उत्पत्ति को एक स्ट्रिंग या विभाजित सूची के रूप में संग्रहीत करती हैं। इस दृष्टिकोण को अक्सर सामग्रीकृत पथ पैटर्न कहा जाता है। यह अडजेसेंसी सूची की सरलता और पथ की पठनीयता को जोड़ता है।
📐 स्कीमा संरचना
इस मॉडल में, प्रत्येक रिकॉर्ड में रूट से पूर्ण पथ संग्रहीत होता है। उदाहरण के लिए, फाइल सिस्टम मॉडल में, एक फाइल के पथ स्ट्रिंग जैसे हो सकता है/home/user/documents/report.txt. एक डेटाबेस में, इसे अक्सर कॉलम के भीतर विभाजित स्ट्रिंग के रूप में संग्रहीत किया जाता है, जैसे कि1/5/12/.
तालिका में शामिल है:
- आईडी:प्राथमिक कुंजी।
- पथ:उत्पत्ति का प्रतिनिधित्व करने वाली एक स्ट्रिंग।
- गहराई:एक पूर्णांक जो बताता है कि नोड कितने स्तर तक गहरा है।
✅ लाभ
- आसान ट्रैवर्सल: आप पथ पूर्वसर्ग के मिलान द्वारा सभी वंशजों को खोज सकते हैं।
- पठनीयता: डेटा मानव-पठनीय होता है और डीबग करना आसान होता है।
- क्रमबद्धता: पथ स्ट्रिंग द्वारा क्रमबद्ध करने से अक्सर सही ट्री क्रम प्राकृतिक रूप से प्राप्त होता है।
❌ कमियाँ
- स्टोरेज ओवरहेड: लंबे पथ निर्णायक स्टोरेज स्थान का उपयोग कर सकते हैं।
- स्ट्रिंग पार्सिंग: प्रश्नों को अक्सर स्ट्रिंग संशोधन फंक्शन की आवश्यकता होती है, जो पूर्णांक तुलना की तुलना में धीमी हो सकती है।
📊 तुलनात्मक विश्लेषण
सही मॉडल का चयन आपके पढ़ने-लिखने के अनुपात और आपके हिरार्की की गहराई पर बहुत निर्भर करता है। निम्नलिखित तालिका प्रत्येक विधि की विशेषताओं को चित्रित करती है।
| विशेषता | संलग्न सूची | नेस्टेड सेट्स | सामग्री मार्ग |
|---|---|---|---|
| पढ़ने का प्रदर्शन | कम से मध्यम | उच्च | मध्यम से उच्च |
| लेखन प्रदर्शन | उच्च | कम | मध्यम |
| कार्यान्वयन की जटिलता | कम | उच्च | मध्यम |
| गहन वृक्षों का समर्थन करता है | हाँ | हाँ | हाँ (सीमाओं के साथ) |
| प्रश्न तर्क | पुनरावर्ती | रेंज स्कैन | पूर्वसर्ग मिलान |
⚙️ प्रदर्शन पर विचार
हिरार्की के मॉडलिंग के समय, आपको डेटाबेस इंजन द्वारा डेटा के संभाले जाने के तरीके को ध्यान में रखना होगा। चाहे मॉडल का चयन कितना भी क्यों न हो, इंडेक्सिंग रणनीतियाँ एक महत्वपूर्ण भूमिका निभाती हैं।
- संलग्न सूची: इंडेक्स करें
माता-पिता_आईडीकॉलम को भारी मात्रा में। इससे डेटाबेस को एक विशिष्ट नोड के सभी बच्चों को पूरी टेबल के स्कैन किए बिना तेजी से ढूंढने में सक्षम बनाता है। - नेस्टेड सेट्स: दोनों को इंडेक्स करें
बाएंऔरदाएं. कॉम्पोजिट इंडेक्स सीमा क्वेरी को महत्वपूर्ण रूप से ऑप्टिमाइज़ कर सकते हैं। - मैटेरियलाइज़्ड पथ: को इंडेक्स करें
पथकॉलम। डेटाबेस के आधार पर, उप-पेड़ फ़िल्टर करने के लिए प्रीफ़िक्स इंडेक्स लाभदायक हो सकता है।
🛠️ रखरखाव और अपडेट्स
डेटा मॉडल स्थिर नहीं होते हैं। जैसे-जैसे आपके संगठन का विस्तार होता है, आपकी व्यवस्था बदलती है। एक शाखा से दूसरी शाखा में एक नोड को हटाना एक सामान्य संचालन है जो प्रत्येक मॉडल को अलग-अलग तरीके से प्रभावित करता है।
🔄 नोड्स को हटाना
एक में पड़ोसी सूची, नोड को हटाना एक ही अपडेट स्टेटमेंट है। आप माता-पिता_आईडीउप-पेड़ के रूट का। हालांकि, आपको यह सुनिश्चित करना होगा कि कोई चक्रीय संदर्भ न बने।
एक में नेस्टेड सेटमॉडल में, नोड को हटाना जटिल है। इसमें लक्ष्य उप-पेड़ में सभी नोड्स के बाएं और दाएंमान की पुनर्गणना शामिल है ताकि हटाए गए नोड के लिए जगह बनाई जा सके। यह अक्सर एक लेनदेन ऑपरेशन होता है जिसमें कई टेबल अपडेट शामिल होते हैं।
एक में मैटेरियलाइज़्ड पथमॉडल में, आप हटाए गए नोड और उसके सभी उत्पत्तियों के पथ स्ट्रिंग को अपडेट करते हैं। इसके लिए प्रत्येक बच्चे के लिए पथ को अपडेट करने की आवश्यकता होती है, जो बड़े पेड़ों के लिए एक भारी लेखन ऑपरेशन हो सकता है।
🎯 डेटा मॉडलिंग के लिए सर्वोत्तम प्रथाएं
यह सुनिश्चित करने के लिए कि आपका ईआरडी बनाए रखने योग्य और प्रदर्शनीय रहे, जब आप पदानुक्रमित संरचनाओं को लागू करते हैं तो इन दिशानिर्देशों का पालन करें।
- स्पष्ट नामकरण प्रणाली का उपयोग करें: सामान्य नामों जैसे कि बचें
कॉलम1. उपयोग करेंमाता_पिता_आईडी,पूर्वज_आईडी,बाएं, यादाएंस्पष्ट रूप से। - प्रतिबंधों को लागू करें: चक्रीय संदर्भों को रोकने के लिए डेटाबेस प्रतिबंधों का उपयोग करें। एक नोड अपने ही पूर्वज नहीं हो सकता।
- गहराई सीमा निर्धारित करें: तकनीकी रूप से संभव होने के बावजूद, बहुत गहरे हायरार्की (उदाहरण के लिए, 10 से अधिक स्तरों) के लिए अक्सर डिजाइन की कमी का संकेत होता है। यदि संभव हो तो संरचना को समतल करने के बारे में सोचें।
- चयन को दस्तावेज़ित करें: चूंकि इन पैटर्नों को मानक SQL विशेषताएं नहीं हैं, इसलिए यह दस्तावेज़ करें कि स्कीमा दस्तावेज़न में कौन सा पैटर्न उपयोग किया गया है।
- हाइब्रिड दृष्टिकोणों पर विचार करें: कुछ प्रणालियां पढ़ने और लिखने के प्रदर्शन को संतुलित करने के लिए एडजेसेंसी सूचियों और मैटेरियलाइज्ड पथों को मिलाती हैं।
🧠 सही रणनीति का चयन करें
हर परिदृश्य के लिए एक ही “सही” उत्तर नहीं है। निर्णय आपके एप्लिकेशन की विशिष्ट आवश्यकताओं पर निर्भर करता है।
- एडजेसेंसी सूची चुनें यदि: आपके डेटा के बार-बार बदलने की संभावना है, और हायरार्की की गहराई मामूली है। यह अधिकांश सामान्य उद्देश्य वाले एप्लिकेशन के लिए सबसे सुरक्षित डिफ़ॉल्ट है।
- नेस्टेड सेट्स चुनें यदि: आपके पास एक पढ़ने पर अधिक निर्भर एप्लिकेशन है जहां डेटा को बार-बार नहीं हटाया जाता है, और आपको बड़े उप-उपांगों को तेजी से प्राप्त करने की आवश्यकता है।
- मैटेरियलाइज्ड पथ चुनें यदि: आपको मानव-पठनीय पथ (जैसे URL) की आवश्यकता है और हायरार्की की गहराई आपेक्षाकृत सतही है।
इन संरचनात्मक बातों को समझने से आप विस्तार करने वाले डेटाबेस डिज़ाइन करने में सक्षम होते हैं। अपने एंटिटी रिलेशनशिप डायग्राम के लिए उपयुक्त पैटर्न चुनकर, आप यह सुनिश्चित करते हैं कि आपके डेटा की निरंतरता, पहुंच और कुशलता प्रणाली के जीवनचक्र भर बनी रहे।