











Merancang struktur basis data yang kuat membutuhkan ketepatan dan perencanaan jangka panjang. Diagram Entitas-Keterkaitan (ERD) berfungsi sebagai gambaran dasar untuk arsitektur ini. Tanpa peta yang jelas, redundansi data dan kemacetan kueri muncul dengan cepat, yang berakibat pada penurunan kinerja seiring waktu. Panduan ini mengeksplorasi bagaimana menurunkan teknik optimalisasi langsung dari model visual ini. Kami berfokus pada integritas struktural dan penyesuaian kinerja tanpa bergantung pada fitur platform tertentu atau alat khusus. Dengan memahami hubungan dasar yang mendasarinya, Anda dapat membangun sistem yang dapat diskalakan secara efisien.
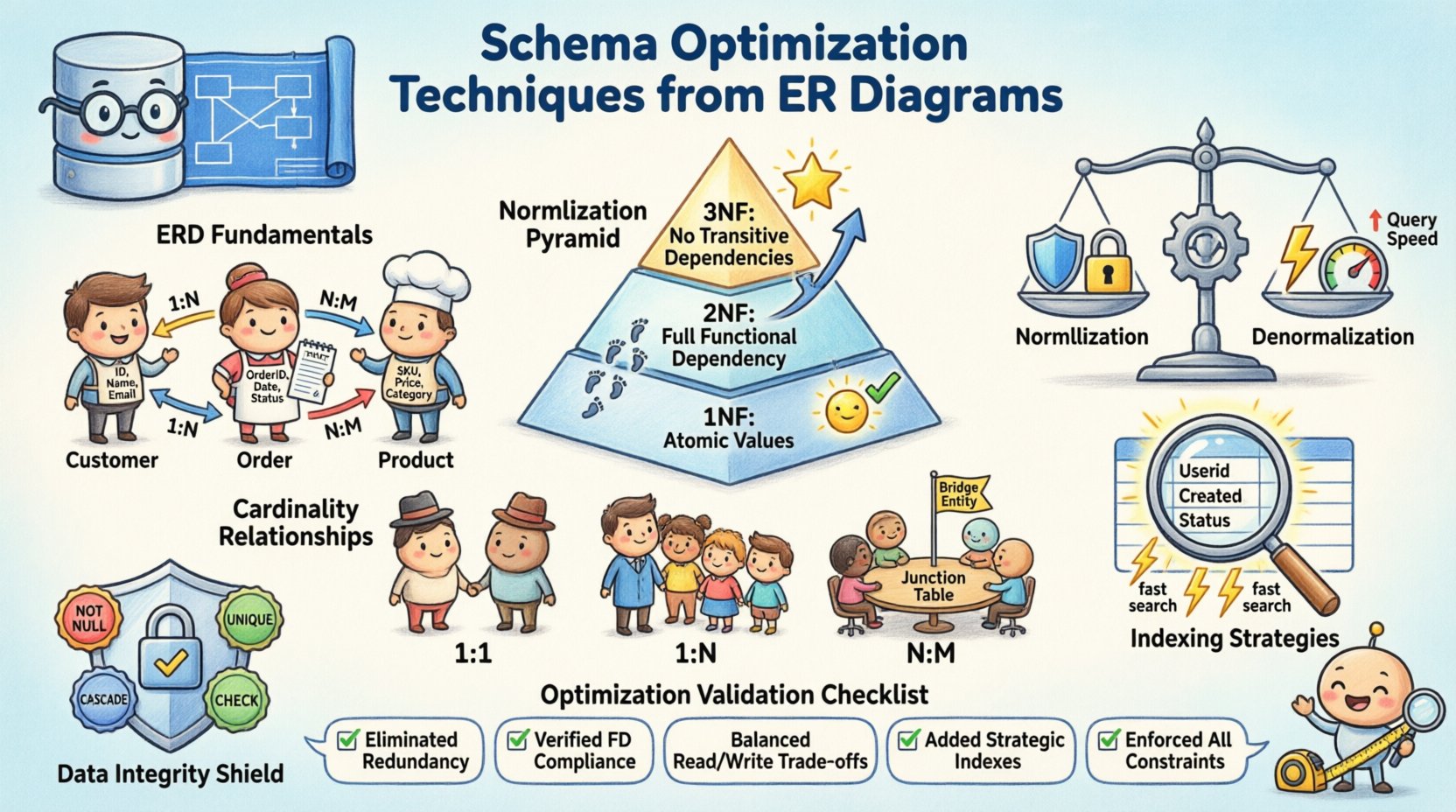
📐 Memahami Dasar-Dasar ERD
Sebelum optimasi dimulai, komponen inti harus jelas. Diagram ER menerjemahkan kebutuhan bisnis menjadi model data logis. Ini menentukan bagaimana informasi disimpan dan diakses. Pondasi yang kuat mencegah utang struktural di kemudian hari dalam siklus pengembangan. Pertimbangkan elemen-elemen berikut:
- Entitas: Mewakili objek atau konsep, seperti pelanggan, pesanan, atau produk. Setiap entitas menjadi tabel dalam skema fisik.
- Atribut: Menentukan sifat-sifat entitas, seperti nama, ID, atau timestamp. Ini menjadi kolom dalam tabel-tabel.
- Keterkaitan: Menunjukkan bagaimana entitas saling berinteraksi. Ini menentukan penggunaan kunci asing dan batasan.
Memvisualisasikan komponen-komponen ini memungkinkan Anda mengidentifikasi masalah potensial sebelum menulis satu baris kode pun. Ini memastikan bahwa alur logis sesuai dengan kebutuhan penyimpanan fisik. Keselarasan ini sangat penting untuk menjaga konsistensi data di seluruh aplikasi yang kompleks.
🔨 Strategi Normalisasi untuk Integritas Data
Normalisasi adalah proses mengorganisasi data untuk mengurangi redundansi dan meningkatkan integritas. Ini melibatkan pembagian tabel besar menjadi unit-unit logis yang lebih kecil. Meskipun normalisasi berlebihan dapat memperlambat operasi baca, mengabaikannya sama sekali akan menciptakan anomali pembaruan. Tujuannya adalah menemukan keseimbangan yang sesuai dengan beban kerja spesifik Anda.
Bentuk Normal Pertama (1NF)
Aturan pertama mengharuskan setiap kolom berisi nilai atomik. Tidak diperbolehkan adanya kelompok berulang atau array dalam satu sel tunggal. Ini memastikan bahwa setiap bagian data bersifat unik dan dapat dipertanyakan. Misalnya, daftar nomor telepon harus dibagi menjadi baris terpisah atau tabel terkait, bukan disimpan sebagai string yang dipisahkan koma.
Bentuk Normal Kedua (2NF)
Setelah 1NF terpenuhi, 2NF menangani ketergantungan parsial. Semua atribut non-kunci harus tergantung pada seluruh kunci utama. Pada kunci komposit, ini mencegah duplikasi data di mana hanya sebagian kunci yang menentukan suatu atribut. Langkah ini menyempurnakan struktur agar setiap informasi terikat dengan benar pada induknya.
Bentuk Normal Ketiga (3NF)
Bentuk ketiga menghilangkan ketergantungan transitif. Atribut non-kunci seharusnya tidak tergantung pada atribut non-kunci lainnya. Artinya, jika Atribut A tergantung pada Atribut B, dan B tergantung pada Kunci, maka A seharusnya tidak berada dalam tabel yang sama. Memindahkan data semacam ini ke tabel terpisah meningkatkan kemudahan pemeliharaan dan mengurangi pemborosan penyimpanan.
Tabel di bawah ini merangkum perkembangan normalisasi:
| Bentuk Normal | Tujuan Utama | Kendala Kunci |
|---|---|---|
| 1NF | Nilai Atomik | Tidak ada kelompok berulang |
| 2NF | Ketergantungan Penuh | Hapus ketergantungan parsial |
| 3NF | Kemerdekaan | Hapus ketergantungan transitif |
⚡ Denormalisasi untuk Kinerja
Sementara normalisasi menjamin integritas, sering kali memerlukan join yang kompleks selama kueri. Pada sistem yang banyak membaca, beban dari menggabungkan beberapa tabel dapat menjadi penghalang. Denormalisasi secara sengaja memperkenalkan redundansi untuk meningkatkan kecepatan pengambilan data. Ini merupakan pertukaran antara efisiensi penyimpanan dan kinerja kueri.
Pertimbangkan skenario berikut di mana denormalisasi tepat digunakan:
- Dasbor Pelaporan: Data yang digabungkan dapat dihitung terlebih dahulu dan disimpan untuk menghindari perhitungan secara real-time.
- Lapisan Penyimpanan Sementara (Caching): Data yang sering diakses dapat diduplikasi di penyimpanan yang dioptimalkan untuk pembacaan.
- Transaksi dengan Volume Tinggi: Mengurangi kedalaman join meminimalkan persaingan kunci dan penggunaan CPU.
Saat menerapkan ini, tetapkan proses yang jelas untuk memperbarui data yang berulang. Ketidaksesuaian muncul jika sumber kebenaran berubah tanpa memperbarui salinannya. Pemicu otomatis atau logika aplikasi harus menangani sinkronisasi untuk menjaga akurasi.
🔗 Mengelola Kardinalitas dan Hubungan
Kardinalitas mendefinisikan hubungan numerik antar entitas. Ini menentukan bagaimana kunci asing diimplementasikan dan bagaimana data dihubungkan. Memahami pola-pola ini sangat penting untuk mencegah catatan terlantar dan memastikan integritas referensial.
- Satu-ke-Satu: Jarang ditemukan dalam sistem umum, sering digunakan untuk tabel keamanan atau tabel perluasan. Satu baris di Tabel A terhubung tepat ke satu baris di Tabel B.
- Satu-ke-Banyak: Hubungan yang paling umum. Satu catatan induk terkait dengan beberapa catatan anak. Kunci asing berada di tabel anak.
- Banyak-ke-Banyak:Membutuhkan tabel sambungan untuk menyelesaikan hubungan. Tabel perantara ini menghubungkan kunci utama kedua entitas.
Asumsi kardinalitas yang salah menyebabkan penyimpanan yang tidak efisien atau keadaan data yang tidak valid. Sebagai contoh, menangani hubungan banyak-ke-banyak sebagai kolom sederhana akan mencegah banyak asosiasi. Memodelkan hubungan ini secara tepat memastikan basis data dapat menerapkan aturan bisnis yang ditentukan dalam diagram.
📉 Strategi Indeks Berdasarkan Analisis Struktural
Indeks adalah mekanisme yang memungkinkan mesin basis data menemukan data dengan cepat. Struktur ERD secara langsung menentukan kolom mana yang harus diindeks. Menambahkan indeks secara membabi buta menghabiskan ruang disk dan memperlambat operasi tulis.
Pertimbangan penting dalam indeks meliputi:
- Kunci Utama:Selalu diindeks secara default. Mereka menentukan identitas unik setiap baris.
- Kunci Asing:Sering kali memerlukan indeks untuk mempercepat operasi join dan pemeriksaan keterbatasan.
- Kunci Komposit:Digunakan ketika kueri melakukan filter berdasarkan beberapa kolom. Urutan kolom dalam indeks berpengaruh terhadap kinerja.
- Kolom Selektif:Indeks kolom dengan kardinalitas tinggi. Selektivitas rendah (misalnya, jenis kelamin) jarang mendapatkan manfaat dari indeks.
Analisis pola kueri Anda terhadap desain skema. Jika suatu join tertentu dieksekusi secara sering, pastikan kolom kunci asing diindeks. Ini mengurangi waktu yang dihabiskan basis data untuk memindai seluruh tabel.
🛡️ Integritas Data dan Kendala Referensial
Kendala integritas melindungi akurasi dan konsistensi data. Mereka berfungsi sebagai pembatas untuk mencegah input yang tidak valid atau penghapusan yang tidak disengaja. Meskipun beberapa kendala diterapkan oleh aplikasi, kendala tingkat basis data lebih dapat diandalkan.
Jenis kendala umum meliputi:
- TIDAK BOLEH KOSONG:Memastikan kolom selalu berisi nilai. Mencegah celah pada bidang data penting.
- UNIK:Memastikan tidak ada dua baris yang berbagi nilai yang sama dalam kolom tertentu. Berguna untuk email atau nama pengguna.
- CASCADE:Menentukan apa yang terjadi pada catatan anak saat induk dihapus. Pilihan termasuk membatasi, cascade, atau mengatur menjadi null.
- CHECK:Menerapkan kondisi tertentu pada nilai data, seperti rentang tanggal atau batas numerik.
Menerapkan aturan ini pada tingkat basis data mencegah aplikasi harus memvalidasi setiap titik data. Ini mengkonsentrasikan logika keabsahan data, mengurangi duplikasi kode dan potensi kesalahan.
🔄 Penyempurnaan Iteratif dan Evolusi Skema
Desain skema bukan tugas satu kali. Persyaratan bisnis berubah, dan model data harus berkembang. Tinjauan rutin terhadap ERD dan skema fisik membantu mengidentifikasi area perbaikan. Memantau kinerja kueri memberikan wawasan tentang di mana struktur mengalami kesulitan.
Selama penyempurnaan, pertimbangkan langkah-langkah berikut:
- Ulasan Penggunaan Indeks:Hapus indeks yang tidak digunakan untuk mengurangi beban tulis.
- Periksa Partisi:Tabel besar mungkin mendapat manfaat dari membagi data berdasarkan rentang atau kunci.
- Perbarui Kardinalitas:Seiring pergeseran logika bisnis, hubungan dapat berubah dari satu-ke-banyak menjadi banyak-ke-banyak.
- Kontrol Versi:Anggap perubahan skema sebagai kode. Lacak modifikasi untuk memungkinkan rollback jika diperlukan.
Pendekatan iteratif ini memastikan basis data tetap selaras dengan kebutuhan aplikasi seiring waktu. Ini mencegah akumulasi utang teknis yang memperlambat pengembangan di masa depan.
✅ Daftar Periksa Optimasi
Gunakan daftar ini untuk memvalidasi desain skema Anda sebelum peluncuran:
- Verifikasi semua tabel memenuhi setidaknya Bentuk Normal Ketiga (3NF).
- Pastikan kunci asing diindeks di tempat penggabungan sering terjadi.
- Periksa adanya ketergantungan melingkar dalam hubungan.
- Konfirmasi bahwa kunci utama didefinisikan untuk setiap tabel.
- Tinjau keterbatasan untuk memastikan aturan konsistensi data diterapkan.
- Analisis pola kueri untuk mengidentifikasi peluang denormalisasi yang mungkin terjadi.
- Dokumentasikan semua asumsi mengenai kardinalitas dan volume data.
Mengikuti langkah-langkah ini menciptakan dasar yang tangguh untuk penyimpanan data. Ini memungkinkan sistem menangani pertumbuhan tanpa perlu direkonstruksi secara menyeluruh. Skema yang dioptimalkan dengan baik adalah perbedaan antara aplikasi yang lambat dan yang responsif.