










Merancang skema basis data yang kuat membutuhkan pemahaman mendalam tentang bagaimana entitas data berinteraksi. Di antara struktur yang paling kompleks untuk dikelola adalah hubungan banyak-ke-banyak. Skenario ini terjadi ketika satu contoh entitas terhubung dengan beberapa contoh entitas lain, dan sebaliknya. Tanpa perencanaan yang tepat, koneksi ini dapat menyebabkan redundansi data, masalah integritas, serta bottleneck kinerja yang signifikan. Panduan ini mengeksplorasi mekanisme mengoptimalkan hubungan-hubungan ini dalam Model Hubungan Entitas (ERMs) untuk memastikan sistem yang dapat diskalakan dan mudah dipelihara.
Memahami Tantangan Inti 🔍
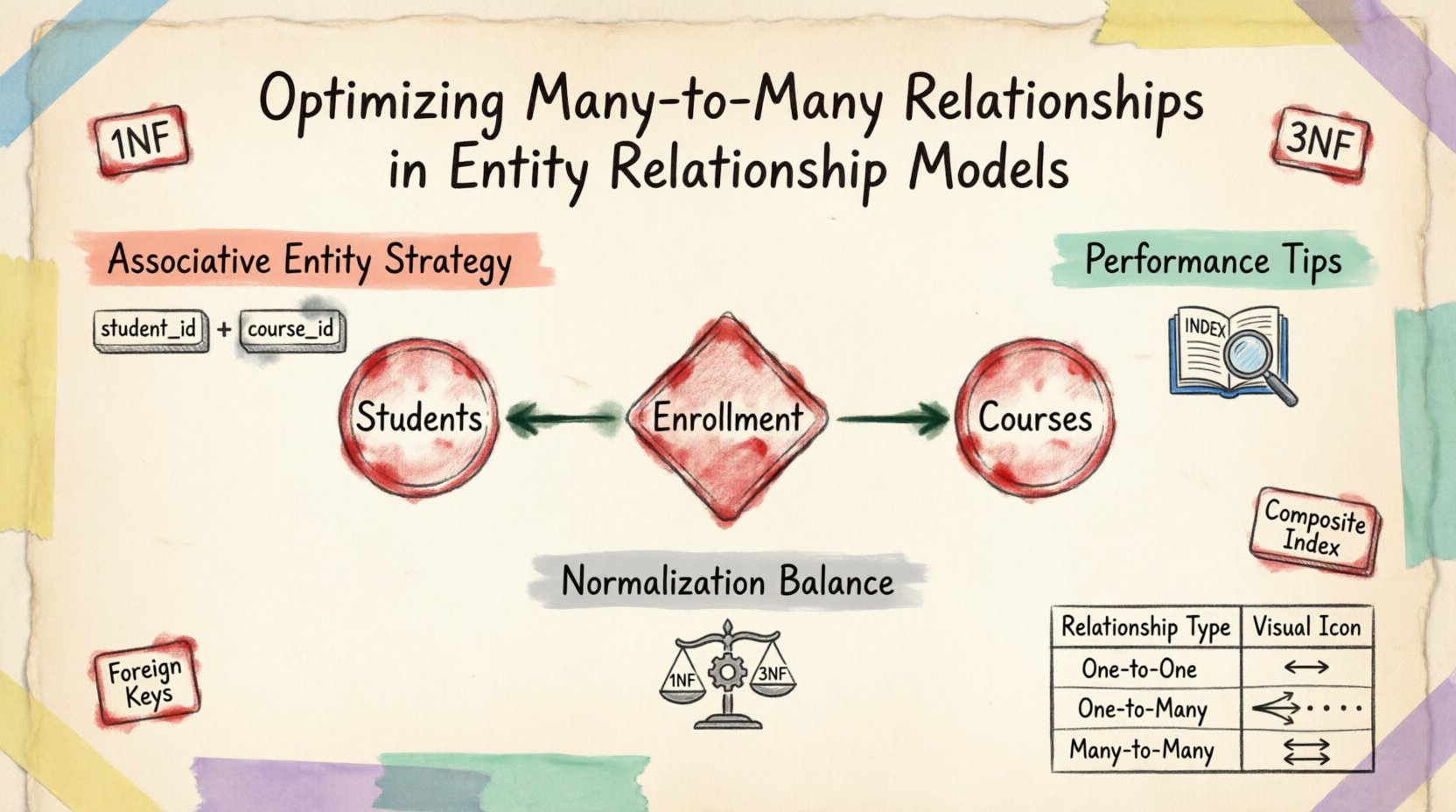
Dalam model konseptual, hubungan banyak-ke-banyak bersifat intuitif. Bayangkan siswa dan mata kuliah. Seorang siswa mendaftar dalam beberapa mata kuliah, dan setiap mata kuliah memiliki beberapa siswa. Mewakili hal ini secara langsung dalam struktur basis data fisik bermasalah. Tabel relasional standar mendukung hubungan satu-ke-banyak dan satu-ke-satu secara bawaan melalui kunci asing. Hubungan banyak-ke-banyak membutuhkan struktur perantara agar dapat berfungsi dengan benar.
Mencoba menyimpan beberapa ID dalam satu kolom (misalnya, daftar yang dipisahkan koma) melanggar Bentuk Normal Pertama (1NF). Pendekatan ini membuat pencarian, pengindeksan, dan pemeliharaan integritas data hampir mustahil. Solusinya terletak pada memecah hubungan menjadi dua hubungan satu-ke-banyak melalui entitas asosiatif, sering disebut tabel sambungan atau tabel jembatan.
Strategi Entitas Asosiatif 🧩
Teknik dasar untuk menyelesaikan hubungan banyak-ke-banyak adalah pengenalan entitas asosiatif. Entitas ini berfungsi sebagai jembatan antara dua tabel induk. Ia berisi kunci utama dari kedua entitas induk sebagai kunci asing, menciptakan kunci utama komposit yang menjamin keunikan untuk setiap contoh hubungan.
- Struktur: Tabel ini mencakup kunci asing yang merujuk pada kunci utama entitas yang terkait.
- Keunikan: Kunci komposit mencegah hubungan ganda antara dua catatan yang sama.
- Atribut: Tabel ini dapat menyimpan data spesifik tentang hubungan itu sendiri, bukan hanya tentang entitasnya.
Pertimbangkan skenario yang menghubungkan Karyawan dan Proyek. Seorang karyawan bekerja pada banyak proyek, dan sebuah proyek memiliki banyak karyawan. Tabel hubungan mungkin menyimpan tanggal penugasan, peran karyawan dalam proyek tersebut, atau jam yang dialokasikan. Atribut-atribut ini milik hubungan, bukan milik karyawan atau proyek secara individual.
Langkah-Langkah Implementasi
- Identifikasi Entitas: Tentukan dua entitas yang berbeda yang terlibat dalam hubungan ini.
- Buat Tabel Sambungan: Buat tabel baru dengan nama deskriptif, seperti
Penugasan_Karyawan_Proyek. - Tambahkan Kunci Asing: Masukkan kolom untuk kunci utama dari kedua entitas induk.
- Tentukan Keterbatasan: Atur keterbatasan kunci asing untuk menegakkan integritas referensial.
- Pengindeksan: Terapkan indeks pada kolom kunci asing untuk mempercepat operasi join.
Normalisasi dan Integritas Data 🛡️
Optimasi sering melibatkan pertukaran antara normalisasi dan kinerja. Meskipun normalisasi mengurangi redundansi, struktur yang terlalu dinormalisasi dapat memerlukan join yang kompleks yang memperlambat query. Saat mengoptimalkan hubungan banyak-ke-banyak, sangat penting untuk menyeimbangkan faktor-faktor ini.
Bentuk Normal Ketiga (3NF) umumnya menjadi tujuan untuk basis data operasional. Dalam keadaan ini, tabel sambungan seharusnya tidak mengandung ketergantungan transitif. Setiap atribut non-kunci harus tergantung pada kunci utama. Jika tabel sambungan berisi data yang hanya tergantung pada salah satu kunci asing, maka data tersebut seharusnya dipindahkan ke tabel induk yang sesuai.
Kesalahan Umum dalam Normalisasi
- Kunci Asing yang Berulang:Memasukkan kunci asing yang sama dalam beberapa tabel hubungan tanpa hierarki yang jelas.
- Keterbatasan yang Hilang:Gagal menerapkan batasan unik pada kombinasi kunci asing.
- Penghapusan Lembut:Tidak mempertimbangkan catatan yang dihapus dalam tabel hubungan, mengakibatkan data terbengkalai.
Strategi Optimasi Kinerja ⚡
Seiring volume data meningkat, jumlah baris dalam tabel hubungan dapat meningkat secara eksponensial. Ini secara langsung memengaruhi waktu eksekusi kueri. Beberapa strategi dapat mengurangi penurunan kinerja.
1. Pengindeksan Strategis
Indeks sangat penting untuk kinerja join. Indeks komposit pada kolom kunci asing sering kali lebih efektif daripada indeks individu. Ini memungkinkan mesin basis data menemukan baris yang terkait lebih cepat tanpa harus memindai seluruh tabel.
- Indeks Berkelompok:Pada beberapa sistem, mengelompokkan tabel berdasarkan kunci komposit dapat meningkatkan kueri rentang.
- Indeks Meliputi:Memasukkan kolom yang sering ditanyakan dalam indeks dapat menghilangkan kebutuhan untuk mengakses heap tabel.
2. Pembagian Partisi
Ketika tabel hubungan menjadi terlalu besar untuk dikelola secara efisien, pembagian partisi berdasarkan tanggal atau wilayah dapat mendistribusikan beban. Ini sangat berguna untuk data historis di mana hubungan terkini lebih sering diakses daripada yang lama.
3. Optimalisasi Kueri
Kueri kompleks yang melibatkan beberapa join dapat membebani sumber daya. Menggunakan petunjuk kueri atau merestrukturisasi SQL untuk meminimalkan subkueri dapat membantu. Penting juga untuk menganalisis rencana eksekusi untuk mengidentifikasi hambatan.
| Strategi | Manfaat | Kompromi |
|---|---|---|
| Pengindeksan Komposit | Pengambilan join yang lebih cepat | Penambahan penyimpanan dan beban tulis |
| Pembagian Partisi Tabel | Peningkatan pemeliharaan dan kecepatan pemindaian | Kompleksitas dalam logika kueri |
| Penyimpanan Sementara | Beban basis data yang berkurang | Risiko konsistensi data |
Menangani Atribut Hubungan 📝
Salah satu keunggulan terbesar dari entitas asosiatif adalah kemampuan untuk menyimpan atribut yang spesifik terhadap hubungan tersebut. Sebagai contoh, dalam sistem manajemen kontrak, Vendor dan Produk memiliki hubungan banyak-ke-banyak. Atribut-atribut tersebut mungkin mencakup harga satuan, tanggal mulai kontrak, dan jumlah yang disepakati.
Jika Anda mencoba menyimpan atribut-atribut ini di tabel Vendor atau Produk, Anda akan menciptakan redundansi. Jika harga berubah, Anda harus memperbarui beberapa baris di tabel produk. Dengan menempatkannya di tabel sambungan, Anda menjaga satu sumber kebenaran untuk instance hubungan tertentu tersebut.
Skenario Lanjutan dan Kasus Tepi 🌐
Pemodelan data dunia nyata sering kali menampilkan tantangan unik yang tidak dapat langsung diatasi oleh pola standar.
- Hubungan yang Mengacu pada Diri Sendiri: Sebuah entitas yang terkait dengan dirinya sendiri (misalnya, seorang Karyawan yang mengelola Karyawan lain). Ini memerlukan kunci asing yang mengarah ke kunci utama tabel yang sama.
- Penghapusan Berantai: Menentukan apakah penghapusan entitas induk harus secara otomatis menghapus catatan hubungannya. Ini mencegah kunci asing yang terpisah, tetapi dapat kehilangan data asosiasi historis.
- Hubungan Rekursif: Hierarki yang kompleks di mana tabel sambungan mengarah kembali ke dirinya sendiri.
Mengquery Skema yang Dioptimalkan 🔎
Setelah skema dioptimalkan, mengquerynya membutuhkan ketepatan. Pengembang harus memahami bagaimana mesin basis data menelusuri jalur join.
Saat mengambil data, seperti semua proyek untuk karyawan tertentu, query harus menggabungkan tabel Karyawan ke tabel Sambungan, lalu ke tabel Proyek. Penulisan SQL yang efisien memastikan bahwa basis data menggunakan indeks yang tersedia dengan benar. Menghindari fungsi pada kolom yang diindeks di dalam klausa WHEREadalah praktik standar untuk menjaga pemanfaatan indeks.
Praktik Terbaik untuk Logika Join
- Gunakan Join yang Jelas: Lebih baik gunakan
INNER JOINatauLEFT JOINdaripada tabel yang dipisahkan secara implisit dengan koma. - Batasi Kolom: Pilih hanya kolom yang diperlukan untuk mengurangi transfer jaringan dan waktu pemrosesan.
- Filter Awal: Terapkan filter di dalam
WHEREklausa sebelum join terjadi jika memungkinkan.
Membandingkan Jenis Hubungan 📊
Memahami di mana banyak-ke-banyak cocok dalam konteks yang lebih luas dari pemodelan data membantu dalam pengambilan keputusan desain yang lebih baik.
| Jenis Hubungan | Struktur | Contoh Kasus Penggunaan |
|---|---|---|
| Satu-ke-Satu | Kunci Asing Tunggal | Profil Pengguna dan Pengaturan Pengguna |
| Satu-ke-Banyak | Kunci Asing Tunggal | Pesanan dan Item Pesanan |
| Banyak-ke-Banyak | Tabel Sambungan | Siswa dan Mata Kuliah |
Menjaga Konsistensi Data 🔄
Memastikan bahwa data tetap konsisten di seluruh tabel yang terkait sangat penting. Ini sering melibatkan manajemen transaksi. Transaksi harus membungkus penyisipan data ke dalam tabel induk dan tabel sambungan. Jika salah satu langkah gagal, seluruh operasi harus dibatalkan untuk mencegah keadaan data parsial.
Triger juga dapat digunakan untuk menerapkan logika bisnis, meskipun harus digunakan secara hemat untuk menghindari biaya kinerja tersembunyi. Sebagai contoh, sebuah trigger dapat mencegah seorang karyawan ditugaskan ke proyek jika departemennya tidak sesuai dengan departemen proyek tersebut.
Pemantauan dan Pemeliharaan 📈
Setelah diimplementasikan, sistem membutuhkan pemantauan berkelanjutan. Pertumbuhan pada tabel sambungan sering menjadi tanda pertama masalah skalabilitas. Audit rutin terhadap ukuran tabel, fragmentasi indeks, dan metrik kinerja query diperlukan.
- Arsipkan: Pindahkan data hubungan historis ke penyimpanan dingin jika data tersebut tidak lagi diproses secara aktif.
- Reindeks: Bangun kembali atau organisasi kembali indeks secara berkala untuk menjaga kinerja optimal.
- Meninjau Gabungan: Pastikan perubahan aplikasi tidak menimbulkan pola query yang tidak efisien.
Pikiran Akhir tentang Desain Skema 🎯
Mengoptimalkan hubungan banyak-ke-banyak bukanlah tugas satu kali, tetapi proses berkelanjutan untuk penyempurnaan. Diperlukan keseimbangan antara kebenaran teoritis dan kinerja praktis. Dengan mematuhi prinsip normalisasi, memanfaatkan entitas asosiatif, dan menerapkan indeks strategis, arsitek basis data dapat membangun sistem yang kokoh dan efisien. Tujuannya adalah menciptakan struktur yang mendukung logika bisnis tanpa memberlakukan batasan yang tidak perlu pada pengambilan atau modifikasi data.