











Dalam arsitektur data modern, kecepatan pengambilan informasi sering menentukan kelayakan suatu aplikasi. Meskipun peningkatan perangkat keras dan strategi caching memainkan peran penting, dasar kinerja terletak pada struktur data itu sendiri. Secara khusus, desain Model Hubungan Entitas (ERMs) menentukan seberapa efisien mesin basis data dapat menelusuri, bergabung, dan mengagregasi data. Skema yang dioptimalkan tidak hanya mengatur informasi; ia membimbing optimizer kueri menuju jalur eksekusi yang lebih cepat. 📉
Panduan ini mengeksplorasi mekanisme teknis di balik desain skema dan korelasi langsungnya terhadap kinerja kueri. Kami akan memeriksa bagaimana tingkat normalisasi, kardinalitas hubungan, dan strategi indeks berinteraksi dalam rencana eksekusi kueri. Dengan memahami dinamika ini, pengembang dan arsitek basis data dapat membangun sistem yang dapat diskalakan tanpa mengorbankan integritas atau kecepatan.
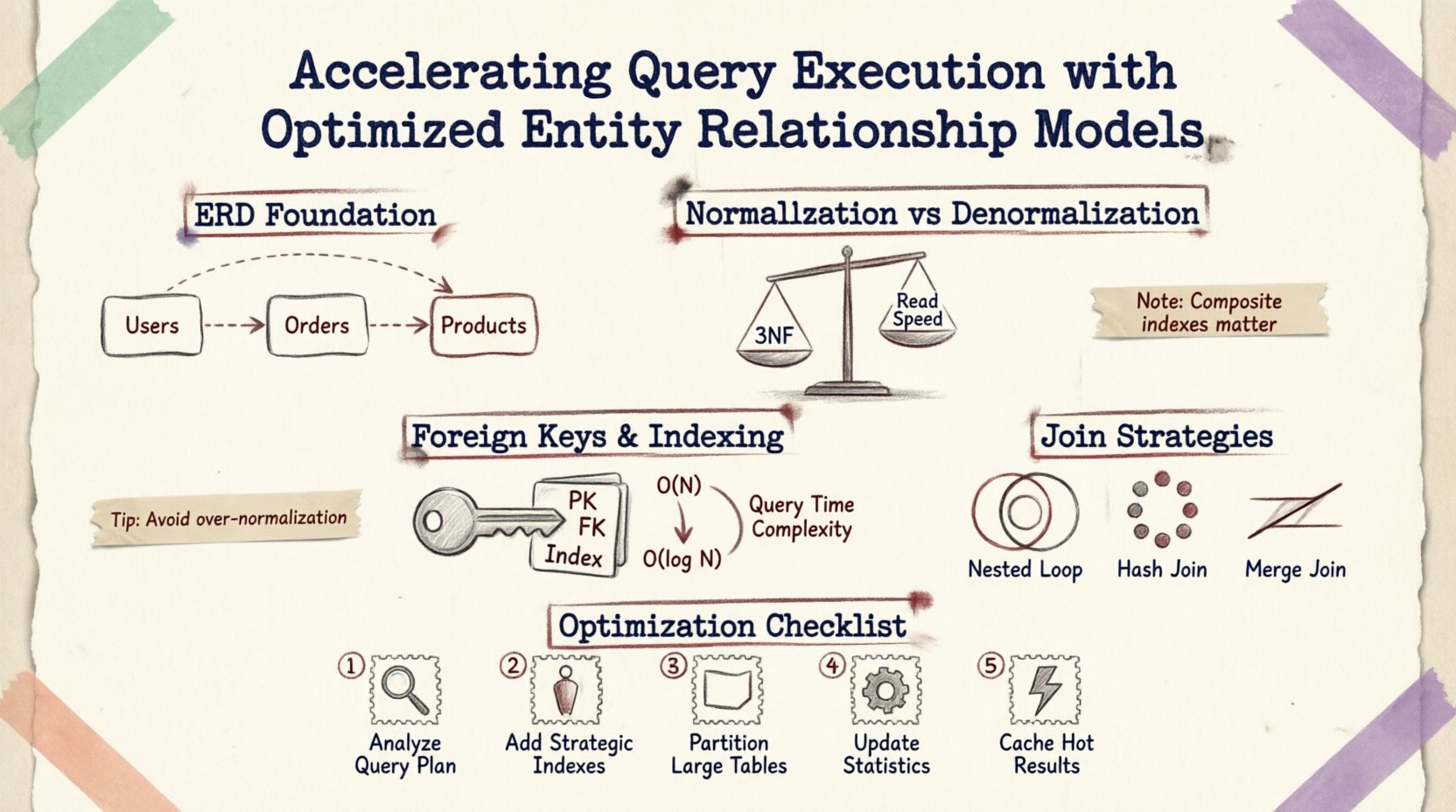
Memahami Dasar: ERD dan Kinerja 🗃️
Diagram Hubungan Entitas lebih dari sekadar alat visual untuk dokumentasi; ia adalah gambaran rancangan untuk logika penyimpanan fisik dan pengambilan data. Setiap garis yang digambar antar tabel mewakili batasan kunci asing, operasi bergabung, atau aturan integritas data. Ketika kueri diajukan, mesin basis data menafsirkan hubungan ini untuk menyusun rencana eksekusi.
Pertimbangkan kueri sederhana yang meminta pesanan pengguna dan detail produk. Mesin harus:
- Temukan tabel
Userstabel. - Ikuti kunci asing ke tabel
Orderstabel. - Gabungkan tabel
OrderItemstabel. - Capai tabel
Productstabel melalui hubungan lain.
Setiap langkah melibatkan operasi I/O dan siklus CPU. Jika hubungan didefinisikan dengan buruk, mesin dapat beralih ke pemindaian tabel penuh atau gabungan loop bersarang yang menurunkan kinerja secara eksponensial. Mengoptimalkan ERD mengurangi jarak data yang harus ditempuh dari disk ke memori.
Normalisasi vs. Denormalisasi: Menemukan Keseimbangan ⚖️
Normalisasi adalah proses mengatur data untuk mengurangi redundansi dan meningkatkan integritas. Meskipun penting untuk konsistensi, normalisasi berlebihan dapat memecah data ke dalam banyak tabel kecil, yang mengharuskan penggabungan kompleks yang memperlambat operasi yang banyak membaca.
Biaya Normalisasi Mendalam
Ketika skema dinormalisasi hingga Bentuk Normal Ketiga (3NF), data disimpan dalam keadaan atomik terkecil. Ini meminimalkan ruang penyimpanan dan anomali pembaruan. Namun, mengambil data yang terkait sering kali memerlukan penelusuran beberapa kunci asing.
- Overhead Gabungan: Setiap tabel tambahan dalam rantai gabungan meningkatkan kompleksitas rencana kueri.
- Persaingan Kunci: Mengakses banyak tabel meningkatkan kemungkinan konflik kunci tingkat baris.
- Penggunaan CPU: Mesin basis data harus menggabungkan hasil dari tabel yang berbeda.
Kapan Saatnya Denormalisasi
Denormalisasi memperkenalkan redundansi untuk mengoptimalkan kinerja baca. Ini sering diperlukan dalam pemrosesan analitik atau lingkungan pelaporan dengan lalu lintas tinggi.
- Beban Kerja dengan Bacaan Berat: Jika penulisan jarang dibandingkan dengan bacaan, menambahkan kolom yang tidak dinormalisasi menghemat operasi join.
- Agregat yang Dihitung Sebelumnya: Menyimpan total (misalnya,
total_order_value) di tabel pengguna menghindari perhitungan jumlah pada setiap permintaan. - Pemartisian Horizontal: Menjaga data yang sering diakses bersama-sama meningkatkan lokalitas cache.
Namun, denormalisasi memerlukan manajemen yang hati-hati untuk mencegah ketidaksesuaian data. Logika aplikasi harus memastikan bahwa data yang berulang diperbarui setiap kali data sumber berubah.
Kunci Asing dan Strategi Pengindeksan 🔑
Kendala kunci asing menegakkan integritas referensial, tetapi datang dengan biaya kinerja. Basis data harus memverifikasi bahwa suatu nilai di satu tabel ada di tabel lain sebelum mengizinkan penyisipan atau pembaruan. Mengoptimalkan cara kunci-kunci ini diindeks sangat penting.
Mengindeks Kunci Asing
Secara default, kunci utama secara otomatis diindeks. Namun, kunci asing sering memerlukan indeks eksplisit untuk mempercepat operasi join. Tanpa indeks pada kolom kunci asing:
- Basis data harus melakukan pemindaian penuh tabel anak untuk menemukan baris yang cocok.
- Operasi join menjadi jauh lebih lambat, terutama saat ukuran tabel tumbuh hingga jutaan baris.
- Pemeriksaan integritas referensial saat penghapusan menjadi mahal.
Kunci asing yang diindeks dengan benar memungkinkan basis data menggunakan pencarian indeks alih-alih pemindaian, mengurangi kompleksitas dari O(N) menjadi O(log N).
Indeks Komposit untuk Hubungan
Ketika beberapa kolom mendefinisikan suatu hubungan, indeks komposit bisa lebih efektif daripada indeks individu. Misalnya, jika suatu kueri menyaring berdasarkan user_id dan created_at dalam tabel pesanan, indeks komposit pada kedua kolom memastikan mesin dapat menemukan data tanpa memindai catatan yang tidak terkait.
Strategi Join dan Rencana Eksekusi 🔍
Struktur ERD memengaruhi algoritma join mana yang dipilih oleh optimizer kueri. Memahami mekanisme ini membantu dalam merancang skema yang mendukung jenis join yang efisien.
| Jenis Join | Paling Cocok Digunakan Ketika | Dampak Kinerja |
|---|---|---|
| Join Lingkaran Bersarang | Hasil set kecil atau predikat yang sangat selektif | Cepat untuk data kecil; lambat untuk pemindaian besar |
| Hash Join | Tabel besar tanpa indeks | Membutuhkan banyak memori; baik untuk data yang tidak terurut |
| Merge Join | Masukan yang telah diurutkan berdasarkan kunci gabungan | Sangat cepat jika data sudah diurutkan |
Mendesain ERD untuk mendukung masukan yang telah diurutkan atau pencarian berbasis indeks dapat mendorong optimizer memilih metode gabungan yang lebih cepat. Sebagai contoh, memastikan bahwa kunci gabungan didefinisikan sebagai bagian dari indeks terkelompok dapat memfasilitasi Merge Joins.
Kesalahan Umum dalam Desain Skema 🚫
Bahkan arsitek berpengalaman membuat kesalahan yang memengaruhi kecepatan kueri. Mengidentifikasi pola-pola ini sejak dini dapat mencegah refaktor yang mahal di kemudian hari.
- Kunci Asing Berantai:Membuat rantai hubungan di mana Tabel A terhubung ke B, B terhubung ke C, dan C terhubung ke D. Kueri yang menggabungkan keempat tabel menjadi sangat bersarang dan lambat.
- String dengan Panjang Variabel: Menggunakan
VARCHARuntuk kunci yang selalu memiliki panjang tetap dapat membuang ruang dan memperlambat perbandingan baris. - Banyak-ke-Banyak tanpa Tabel Hubungan: Berusaha menyimpan beberapa ID dalam satu kolom (misalnya, nilai yang dipisahkan koma) mencegah pengindeksan dan normalisasi yang tepat.
- Konversi Implisit: Mendefinisikan tipe data yang tidak sesuai antara tabel induk dan anak memaksa mesin untuk mengonversi nilai saat runtime, mencegah penggunaan indeks.
Langkah-Langkah Praktis untuk Optimasi 🛠️
Untuk meningkatkan eksekusi kueri tanpa menulis ulang seluruh sistem, ikuti langkah-langkah terstruktur berikut:
- Analisis Pola Kueri: Tinjau operasi baca yang paling sering dilakukan. Identifikasi tabel-tabel mana yang paling sering digabungkan.
- Ulasan Penggunaan Indeks: Periksa apakah ada indeks yang hilang pada kunci asing atau kolom yang sering difilter.
- Perbaiki Kardinalitas: Pastikan hubungan di-model secara akurat (Satu-ke-Satu vs. Satu-ke-Banyak). Kardinalitas yang salah dapat menyebabkan penggabungan yang tidak perlu.
- Partisi Tabel Besar:Jika sebuah tabel melebihi jutaan baris, pertimbangkan untuk membagi data berdasarkan tanggal atau wilayah untuk membatasi jumlah data yang dibaca per query.
- Pantau Penguncian:Gunakan alat pemantauan untuk mengidentifikasi query yang berjalan lama dan memegang kunci, sering kali disebabkan oleh traversing skema yang tidak efisien.
Pertimbangan Penyimpanan dan Memori 💾
Tata letak fisik data juga berperan. Mesin basis data menyimpan data dalam halaman. Jika baris-baris yang terkait disimpan secara fisik berdekatan, maka dibutuhkan lebih sedikit bacaan disk untuk memuat dataset.
- Clustering:Mengatur data berdasarkan kunci umum dapat meningkatkan efisiensi pemindaian rentang.
- Penyimpanan Kolom vs. Penyimpanan Baris:Untuk query analitik, penyimpanan berbasis kolom mungkin menawarkan kompresi yang lebih baik dan agregasi yang lebih cepat dibandingkan model berbasis baris tradisional.
- Penggunaan Cache:Rancang skema yang memungkinkan caching efektif terhadap seluruh hasil query, bukan hanya baris individu.
Pertimbangan Akhir tentang Evolusi Skema 🔄
Desain skema bukanlah tugas satu kali. Seiring perubahan kebutuhan aplikasi, model data harus berkembang. Secara rutin meninjau struktur basis data memastikan kinerja tetap konsisten. Dokumentasi Model Hubungan Entitas harus dipertahankan bersama kode sumber untuk melacak dampak perubahan terhadap sistem.
Dengan fokus pada integritas struktural dan hubungan logis dalam data, Anda menciptakan fondasi yang mendukung eksekusi query berkecepatan tinggi. Tujuannya bukan membangun sistem statis, tetapi arsitektur yang fleksibel yang dapat beradaptasi terhadap beban tanpa mengorbankan kecepatan yang diharapkan pengguna. 📊
Mengoptimalkan Model Hubungan Entitas adalah disiplin teknis yang menggabungkan teori basis data dengan rekayasa praktis. Ini membutuhkan kesabaran, analisis, dan pemahaman yang jelas tentang bagaimana mesin dasar memproses permintaan. Dengan pendekatan yang tepat, masalah kinerja menjadi terkelola, dan pengambilan data menjadi mulus.