











Merancang basis data yang kuat dimulai jauh sebelum query pertama dijalankan. Ini dimulai dengan gambaran awal: Diagram Hubungan Entitas (ERD). 📐 Meskipun banyak pengembang fokus pada pembuatan tabel dan tipe kolom, mesin kinerja sejati terletak pada sejauh mana indeks selaras dengan model data Anda. Pengindeksan bukan sekadar pengaturan konfigurasi; ini merupakan manifestasi fisik dari hubungan logis Anda.
Ketika Anda merancang ERD Anda, Anda menentukan kardinalitas dan konektivitas data Anda. Pilihan struktural ini menentukan strategi pengindeksan yang paling efisien. Hubungan satu-ke-satu membutuhkan pendekatan yang berbeda dibandingkan dengan hubungan banyak-ke-banyak. Mengabaikan nuansa ini sering mengakibatkan penggabungan yang lambat, I/O berlebihan, dan penyimpanan yang terfragmentasi. Panduan ini mengeksplorasi bagaimana menerjemahkan ERD Anda menjadi pola pengindeksan berkinerja tinggi tanpa bergantung pada alat khusus vendor.
🔑 Memahami Dasar: ERD dan Pengindeksan
ERD bukan sekadar alat bantu visual; ini adalah kontrak antara logika aplikasi Anda dan mesin penyimpanan. Setiap garis yang digambar antar entitas mewakili batasan yang harus ditegakkan oleh basis data. Indeks berfungsi untuk mempercepat penegakan batasan-batasan ini dan pengambilan data di antaranya.
Bayangkan lapisan penyimpanan sebagai perpustakaan. Tanpa indeks, mencari sebuah buku membutuhkan pemindaian setiap rak (pemindaian tabel penuh). Indeks adalah kartu katalog. Namun, menempatkan kartu katalog secara salah—misalnya berdasarkan genre alih-alih penulis ketika penulis adalah kunci pencarian utama—akan membuat sistem menjadi tidak efisien. ERD Anda memberi tahu Anda siapa penulis dan genre yang ada, serta hubungan mana yang paling penting.
Pertimbangan utama meliputi:
- Kardinalitas: Kolom dengan kardinalitas tinggi (nilai unik) paling banyak diuntungkan oleh indeks.
- Frekuensi Penggabungan: Tabel-tabel yang sering digabungkan membutuhkan pengindeksan khusus pada kunci asing.
- Volume Tulis: Setiap indeks menambah beban pada operasi penyisipan dan pembaruan.
- Pola Query: Bagaimana Anda menyaring? Bagaimana Anda mengurutkan? ERD memberi petunjuk jawabannya.
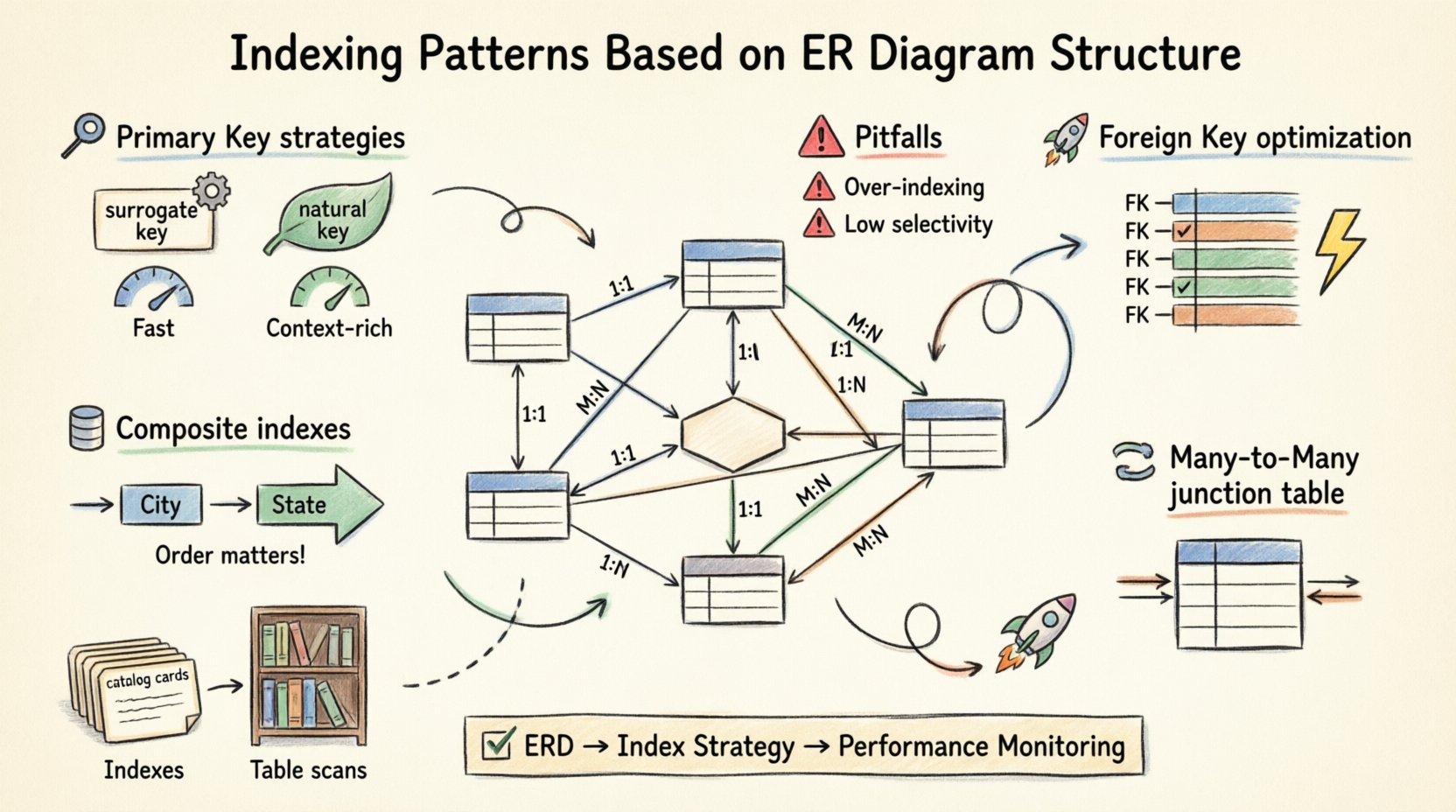
🏗️ Strategi Pengindeksan Kunci Utama
Kunci utama (PK) adalah tulang punggung setiap tabel. Ini menjamin keunikan dan menyediakan mekanisme pengelompokan untuk penyimpanan data dalam banyak sistem. Menyelaraskan pengindeksan Anda dengan definisi PK adalah langkah pertama.
1. Kunci Surrogat vs. Kunci Alami
Memilih antara kunci surrogat (ID otomatis yang bertambah) dan kunci alami (seperti email atau nomor jaminan sosial) secara signifikan memengaruhi kinerja indeks.
- Kunci Surrogat: Ini ideal untuk pengelompokan. Mereka pendek, meningkat secara monoton, dan berurutan. Ini meminimalkan pembagian halaman dan fragmentasi saat menulis. 📈
- Kunci Alami: Meskipun bermakna secara semantik, mereka bisa panjang, panjangnya bervariasi, atau rentan berubah. Mengindeks mereka dapat menyebabkan ukuran indeks yang lebih besar dan pencarian yang lebih lambat dibandingkan dengan kunci berbasis bilangan bulat.
2. Implikasi Indeks Terkelompok
Dalam kebanyakan arsitektur, kunci utama menentukan indeks terkelompok. Ini berarti baris data aktual disimpan secara fisik dalam urutan kunci. Jika ERD Anda menunjukkan bahwa query sering menyaring berdasarkan atribut alami tertentu, Anda mungkin perlu meninjau kembali definisi PK atau menerima bahwa indeks terkelompok akan dioptimalkan untuk satu jenis query, sementara indeks sekunder menangani yang lain.
🔗 Optimalisasi Kunci Asing
Kunci asing (FK) mendefinisikan hubungan antar tabel. Mereka merupakan sumber umum kemacetan kinerja jika dibiarkan tidak diindeks. Ketika Anda menggabungkan dua tabel, mesin basis data harus mencocokkan baris berdasarkan kolom FK. Tanpa indeks, operasi ini menurun menjadi pemindaian loop bersarang, yang sangat mahal secara komputasi untuk data besar.
1. Pengindeksan Kolom Kunci Asing
Selalu buat indeks pada kolom kunci asing di tabel anak. Ini memungkinkan mesin untuk dengan cepat menemukan baris yang terkait tanpa harus memindai seluruh tabel.
| Kesempatan | Persyaratan Pengindeksan | Dampak Kinerja |
|---|---|---|
| Satu-ke-Banyak (Anak) | Indeks FK di Tabel Anak | Memungkinkan pencarian cepat data induk |
| Banyak-ke-Satu (Induk) | Indeks PK di Tabel Induk (biasanya default) | Perilaku kunci utama standar |
| Penghapusan yang Dicabangkan | Indeks FK + PK Induk | Mencegah penguncian seluruh tabel saat menghapus |
2. Kunci Asing Komposit
Kadang-kadang, suatu hubungan bergantung pada beberapa kolom (misalnya, kunci komposit dari tabel induk). Dalam hal ini, Anda harus membuat indeks komposit di tabel anak yang sesuai dengan urutan dan kolom kunci induk. Ketidaksesuaian urutan kolom dalam indeks dapat membuatnya tidak berguna untuk operasi join.
🔀 Menangani Hubungan Banyak-ke-Banyak
Hubungan Banyak-ke-Banyak (M:N) diselesaikan melalui tabel sambungan. Tabel ini berisi kunci asing yang mengarah ke kedua tabel induk. Strategi pengindeksan di sini sangat penting untuk kinerja.
Pertimbangkan skenario di mana Siswa mendaftar di Kursus. Tabel sambungan menghubungkan keduanya. Untuk menemukan semua kursus bagi seorang siswa, Anda perlu melakukan query terhadap tabel sambungan secara efisien.
- Pengindeksan Dua Arah: Anda sebaiknya mengindeks kedua kolom kunci asing secara terpisah. Ini memungkinkan Anda melakukan query hubungan dari kedua sisi (Siswa → Kursus atau Kursus → Siswa) tanpa melakukan pemindaian penuh.
- Pengindeksan Komposit: Jika query Anda selalu mengambil kursus dari seorang siswa tertentu, indeks komposit pada (ID_Siswa, ID_Kursus) lebih efisien daripada dua indeks terpisah. Ini mencakup kriteria pencarian dalam satu kali pencarian.
📊 Indeks Komposit dan Indeks Meliputi
Tidak semua query melakukan filter berdasarkan satu kolom. Query kompleks sering melibatkan beberapa kondisi. Di sinilah indeks komposit bersinar. Indeks komposit adalah indeks tunggal yang dibangun dari beberapa kolom.
1. Urutan Kolom Penting
Urutan kolom dalam indeks komposit tidak sembarangan. Mesin basis data hanya dapat menggunakan indeks hingga titik di mana kondisi kesamaan berhenti. Misalnya, jika Anda mengindeks (Kota, Negara Bagian), query yang melakukan filter berdasarkan Kota akan menggunakan indeks. Query yang hanya melakukan filter berdasarkan Negara Bagian kemungkinan besar akan mengabaikannya.
2. Indeks Meliputi
Indeks meliputi mencakup semua kolom yang diperlukan untuk memenuhi query, termasuk daftar SELECT. Ini memungkinkan basis data mengambil data langsung dari pohon indeks tanpa mengakses tabel utama (heap). Ini merupakan peningkatan kinerja besar untuk operasi baca yang intensif.
⚠️ Kesalahan Umum dan Praktik Terbaik
Bahkan dengan ERD yang sempurna, kesalahan implementasi dapat menurunkan kinerja. Berikut ini adalah jebakan umum yang perlu dihindari saat mengonversi struktur ke penyimpanan.
- Indeks Berlebihan:Setiap indeks mengonsumsi ruang disk dan memperlambat operasi tulis. Hanya indeks kolom yang sering dipanggil atau digunakan untuk keterbatasan.
- Selektivitas Rendah:Mengindeks kolom dengan kardinalitas rendah (misalnya, flag boolean “is_active”) sering kali tidak efisien. Optimizer mungkin memutuskan bahwa pemindaian lengkap tabel lebih cepat daripada melompat ke indeks.
- Mengabaikan Nilai Kosong:Indeks menangani nilai NULL secara berbeda tergantung pada mesinnya. Pastikan logika kueri Anda mempertimbangkan bagaimana nilai NULL diindeks dalam pengaturan spesifik Anda.
- Fragmentasi:Seiring waktu, indeks menjadi terfragmentasi. Pemeliharaan rutin diperlukan untuk menjaga kinerja tetap optimal.
🛠️ Pemantauan dan Pemeliharaan Kinerja
Setelah strategi indeks Anda diterapkan, pemantauan sangat penting. Anda tidak dapat mengoptimalkan apa yang tidak Anda ukur. Tinjau secara rutin rencana eksekusi kueri untuk melihat apakah indeks Anda digunakan secara efektif.
1. Analisis Rencana Eksekusi
Perhatikan operasi seperti “Pemindaian Indeks” vs. “Pencarian Indeks”. Pencarian efisien; pemindaian tidak. Jika Anda melihat pemindaian tabel lengkap pada tabel besar, tinjau kembali strategi indeks Anda berdasarkan pola kueri yang sebenarnya.
2. Lacak Penggunaan Indeks
Kadang-kadang, indeks dibuat tetapi tidak pernah digunakan. Ini menjadi beban berat. Tinjau secara rutin statistik penggunaan indeks untuk mengidentifikasi indeks yang tidak digunakan yang dapat dihapus untuk meningkatkan kinerja tulis.
3. Pertimbangan Pertumbuhan Data
Seiring data Anda tumbuh, biaya pemeliharaan meningkat. Indeks yang berjalan baik dengan 10.000 baris bisa menjadi hambatan pada 10 juta baris. Tinjau ulang pola indeks berbasis ERD Anda saat dataset membesar. Strategi partisi juga mungkin menjadi perlu bersamaan dengan indeks.
🔄 Ringkasan Keselarasan
Menyelaraskan strategi indeks Anda dengan struktur ERD adalah proses berkelanjutan. Ini membutuhkan pemahaman terhadap hubungan data yang didefinisikan dalam desain Anda dan menerjemahkannya menjadi optimasi penyimpanan fisik.
- Kunci Utama:Gunakan untuk pengelompokan dan keunikan.
- Kunci Asing:Indeks untuk kinerja gabungan (join).
- Tabel Hubungan:Indeks dua arah untuk hubungan M:N.
- Pola Kueri:Sesuaikan indeks komposit dengan urutan filter tertentu.
Dengan menghargai integritas struktural ERD Anda, Anda membangun basis data yang dapat berkembang dengan mulus. Anda menghindari kesalahan umum indeksing sesuai kebutuhan dan memastikan data Anda tetap dapat diakses dan berkinerja baik seiring perkembangan aplikasi Anda. Pendekatan disiplin ini memastikan basis data mendukung logika bisnis Anda tanpa menjadi hambatan. 🚀