











Die Gestaltung robuster Datenstrukturen erfordert ein Gleichgewicht zwischen theoretischer Reinheit und praktischer Leistungsfähigkeit. Bei der Arbeit mit komplexen Entitäts-Beziehungs-Modellen (ERDs) führt die strikte Einhaltung von Normalisierungsregeln oft zu Reibung in hochgeschwindigen Umgebungen. Dieser Artikel untersucht strategische Denormalisierungsstrategien, die darauf abzielen, die Abfrageeffizienz zu verbessern, ohne die Datenintegrität zu gefährden. Wir werden analysieren, wann von den Standardformen abgewichen werden sollte und wie Redundanz sicher implementiert werden kann.
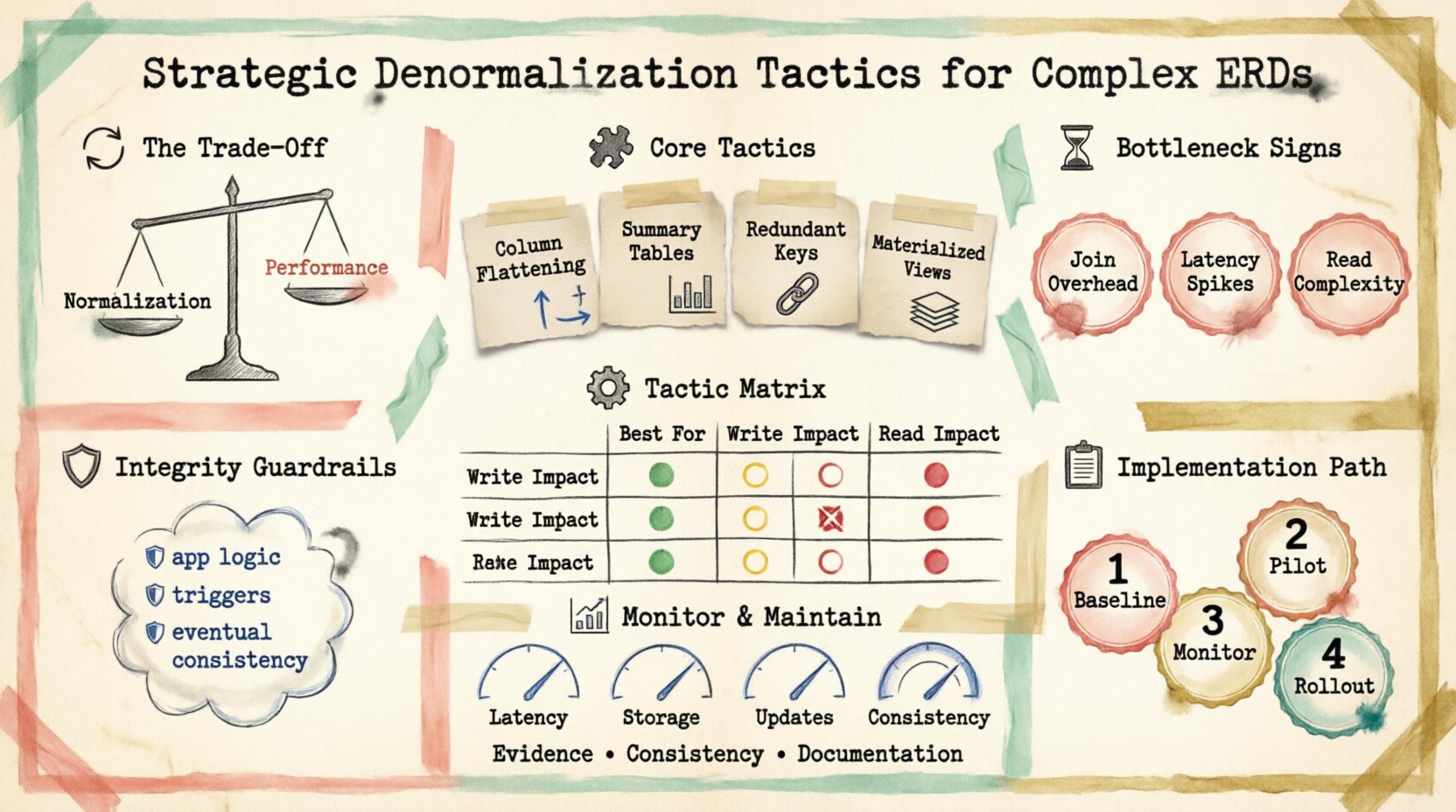
Datenbankarchitekten stehen häufig vor der Wahl, ob sie für Schreiboperationen oder Leseoperationen optimieren sollen. Die Normalisierung reduziert Redundanz und gewährleistet Datenkonsistenz. Sie kann jedoch die Anzahl der benötigten Joins bei der Abrufung erhöhen, was die Latenz beeinflusst. Die Denormalisierung führt Redundanz erneut ein, um Zugriffsmuster zu vereinfachen. Dieser Ansatz geht nicht darum, bewährte Praktiken aufzugeben, sondern sie dort anzuwenden, wo die Geschäftslogik es erfordert.
Die Kosten der strikten Normalisierung 🔄
In einem normalisierten Zustand ist die Datenstruktur in unterschiedliche Tabellen aufgeteilt, um Duplikate zu minimieren. Diese Struktur ist ideal für Speichereffizienz und Schreibkonsistenz. Wenn jedoch die Anzahl der Beziehungen wächst, steigt die Komplexität der Abrufung einzelner Datensätze.
- Join-Aufwand: Jeder Join-Vorgang verbraucht CPU- und Speicherressourcen. Komplexe Abfragen über fünf oder mehr Tabellen können zu Engpässen werden.
- Latenz: Netzwerk-Roundtrips steigen mit der Anzahl der beteiligten Tabellen. In verteilten Systemen wird diese Latenz verstärkt.
- Lesekomplexität: Die Anwendungslogik wird komplexer, da sie mehrere Abrufschritte koordinieren muss.
Für Berichts-Dashboards, Echtzeit-Analysen oder benutzerorientierte Schnittstellen, bei denen die Lese-Geschwindigkeit entscheidend ist, können die Kosten der Normalisierung ihre Vorteile überwiegen. Das Verständnis dieses Kompromisses ist der erste Schritt bei der strategischen Optimierung.
Identifizierung von Leistungsengpässen ⏱️
Bevor Sie das Schema ändern, müssen Sie spezifische Engpässe identifizieren. Nicht jede langsame Abfrage erfordert eine Denormalisierung. Verwenden Sie Profiling-Tools, um Ausführungspläne zu analysieren.
- Hoher I/O-Wartezeit: Zeigt übermäßiges Lesen von Festplatten an, das oft durch das Scannen großer Tabellen verursacht wird.
- Sperrkonflikte: Häufige Sperrungen während Lesevorgänge können auf übermäßig fragmentierte Datenstrukturen hindeuten.
- Langsame Aggregat-Abfragen: Berechnungen über mehrere Tabellen leiden oft unter der Überlastung der Normalisierung.
Wenn diese Metriken konsistent auftreten, deutet dies auf eine Gelegenheit hin, die Datenstruktur neu zu gestalten. Das Ziel ist es, die Rechenlast für die Engine zu reduzieren, ohne die Quelle der Wahrheit zu gefährden.
Kernstrategische Ansätze 🧩
Es gibt mehrere Methoden, um Redundanz strategisch einzuführen. Die Wahl hängt vom Lese-Schreib-Verhältnis Ihrer spezifischen Arbeitslast ab.
1. Spalten-Flachung
Dabei wird Daten aus zugehörigen Tabellen direkt in die Haupttabelle verschoben. Zum Beispiel wird die E-Mail-Adresse eines Benutzers in der Auftragstabelle gespeichert, anstatt bei jeder Abrufung eines Auftrags die Benutzertabelle zu verknüpfen.
- Vorteil: Beseitigt die Join-Anforderung für Benutzerdetails.
- Einschränkung: Die Daten müssen aktualisiert werden, sobald sich das Benutzerprofil ändert.
2. Zusammenfassungstabellen
Vorab berechnete Aggregationen können neben detaillierten transaktionalen Daten stehen. Dies ist bei der Finanzberichterstattung oder der Bestandsverwaltung üblich.
- Vorteil:Sofortiger Zugriff auf Summen, Durchschnitte und Zählwerte.
- Einschränkung: Erfordert einen Mechanismus, um die Aggregationen mit den Rohdaten synchron zu halten.
3. Redundante Fremdschlüssel
Oft wird in einer Kindtabelle ein Elternschlüssel für schnelle Abfragen benötigt. Durch Hinzufügen eines redundanten Fremdschlüssels kann direkt referenziert werden, ohne die Hierarchie durchlaufen zu müssen.
- Vorteil:Schnelleres Durchlaufen tiefer Hierarchien.
- Einschränkung: Erhöht den Speicherplatz geringfügig und erfordert Konsistenzprüfungen.
Matrix zur Vergleichsbeurteilung von Strategien
| Strategie | Am besten geeignet für | Schreibauswirkung | Leseauswirkung |
|---|---|---|---|
| Spaltenflachung | Abfragen mit hohem Abfrageaufwand | Mittel | Niedrig |
| Zusammenfassungstabellen | Berichterstattung und Analytik | Hoch | Sehr niedrig |
| Redundante Schlüssel | Tiefe Hierarchien | Niedrig | Niedrig |
| Materialisierte Ansichten | Komplexe Verknüpfungen | Mittel | Niedrig |
Verwaltung der Datenintegrität 🛡️
Die Einführung von Redundanz birgt das Risiko einer Datenabweichung. Wenn die Quelldaten sich ändern, aber die redundanten Kopien nicht, wird das System unzuverlässig. Dies ist die primäre Herausforderung der De-Normalisierung.
- Anwendungsebene Logik:Stellen Sie sicher, dass der Code alle Kopien der Daten innerhalb einer einzigen Transaktion aktualisiert.
- Auslöser:Datenbankauslöser können Aktualisierungen redundanter Felder automatisieren, wenn die Quelltabellen geändert werden.
- Eventuelle Konsistenz:In einigen Systemen sind geringfügige Verzögerungen zwischen Aktualisierungen akzeptabel. Dies reduziert die Last, erfordert jedoch, dass die Anwendung veraltete Daten reibungslos behandelt.
Validierungsregeln sind entscheidend. Regelmäßige Audits sollten Quelldaten mit redundanten Kopien vergleichen, um Abweichungen zu erkennen. Falls eine Diskrepanz festgestellt wird, sollte ein Rekonstruktions-Skript ausgeführt werden, um die Konsistenz wiederherzustellen.
Implementierungsstrategie 📋
Refaktorisieren Sie die gesamte Datenbank nicht auf einmal. Verwenden Sie einen schrittweisen Ansatz, um das Risiko zu minimieren.
- Basismessung:Notieren Sie aktuelle Abfragezeiten und Ressourcenverbrauch.
- Pilot-De-Normalisierung:Wählen Sie eine hochwirksame Abfrage aus und optimieren Sie sie.
- Überwachung:Verfolgen Sie Leistungsverbesserungen und Fehler der Datenkonsistenz.
- Einführung:Erweitern Sie das Muster auf andere Bereiche mit hohem Volumen.
Dokumentation ist entscheidend. Kennzeichnen Sie deutlich, welche Tabellen de-normalisiert sind und warum. Zukünftige Entwickler müssen die getroffenen Kompromisse bei der Schema-Designs verstehen.
Überwachung von Leistungsmetriken 📊
Sobald die De-Normalisierung aktiv ist, stellt die kontinuierliche Überwachung sicher, dass die Strategie wirksam bleibt.
- Abfrage-Latenz:Achten Sie auf Anstiege, die auf eine Sperrkonkurrenz bei aktualisierten Tabellen hindeuten könnten.
- Speicherwachstum:Redundante Daten verbrauchen mehr Speicherplatz. Planen Sie die Kapazität entsprechend.
- Aktualisierungshäufigkeit:Hohe Schreibvolumina in de-normalisierten Tabellen können die Leistung beeinträchtigen.
- Konsistenzfehler: Protokollieren Sie alle Fehler im Synchronisationsprozess.
Warnungen sollten für Anomalien konfiguriert werden. Wenn eine bestimmte Tabelle schneller wächst, als erwartet, könnte dies auf einen Logikfehler bei der Datenreplikation hinweisen.
Wartungsprotokolle 🔧
Die Pflege eines de-normalisierten Schemas erfordert Disziplin. Es ist keine „einmal einstellen und vergessen“-Konfiguration.
- Schema-Versionierung:Behandeln Sie Schemaänderungen wie Code. Überprüfen Sie Migrationsskripte regelmäßig.
- Aufräumroutinen: Entfernen Sie überflüssige Daten, die nicht mehr benötigt werden, um Platz zu sparen.
- Überprüfungsintervall: Überprüfen Sie erneut die Notwendigkeit der De-Normalisierung, wenn sich die Geschäftsanforderungen ändern.
Manchmal ist die ursprüngliche Optimierung nicht mehr notwendig, wenn das Datenvolumen sinkt oder sich die Zugriffsmuster ändern. Regelmäßige Überprüfungen verhindern, dass technische Schulden anhäufen.
Strategisches Überprüfungsintervall 🔄
Die Datenbankgestaltung ist nicht statisch. Was heute funktioniert, muss morgen nicht mehr funktionieren. Planen Sie vierteljährliche Überprüfungen des Entitäts-Beziehungs-Modells.
- Arbeitslastanalyse: Hat sich das Verhältnis von Lese- zu Schreibvorgängen verändert?
- Hardware-Updates: Neue Speichertechnologien könnten die Kosten von Joins verändern.
- Geschäftsziele: Neue Funktionen könnten andere Datenstrukturen erfordern.
Flexibilität ist entscheidend. Seien Sie bereit, wieder zu normalisieren, wenn die Kosten der Aufrechterhaltung von Redundanz die Leistungsverbesserungen übersteigen. Das Ziel ist immer ein optimaler Systemverhalten, nicht die strikte Einhaltung eines bestimmten Designdogmas.
Abschließende Gedanken zur Schema-Evolution 📝
Die De-Normalisierung ist ein mächtiges Werkzeug im Werkzeugkasten des Datenbankarchitekten. Sie löst praktische Leistungsprobleme, die theoretische Modelle manchmal übersehen. Durch die systematische Anwendung dieser Strategien können Sie Systeme erstellen, die sowohl schnell als auch zuverlässig sind.
- Fokussieren Sie sich auf Beweise: Treffen Sie Entscheidungen auf Basis von Metriken, nicht auf Basis von Annahmen.
- Priorisieren Sie Konsistenz: Stellen Sie sicher, dass die Daten in allen Schichten genau bleiben.
- Dokumentieren Sie Entscheidungen: Führen Sie eine Aufzeichnung darüber, warum bestimmte Tabellen geändert wurden.
Mit sorgfältiger Planung und kontinuierlicher Wartung können komplexe Entitäts-Beziehungs-Modelle die Leistung liefern, die moderne Anwendungen erfordern. Der Weg zur Effizienz ist iterativ und erfordert ständige Aufmerksamkeit für das Gleichgewicht zwischen Struktur und Geschwindigkeit.