











Die Datenbankgestaltung ist eine Übung in Balance. Sie erfordert die Strukturierung von Daten, um reale Beziehungen widerzuspiegeln, während Leistung und Integrität gewahrt bleiben. Ein häufiger Fehler in diesem Prozess ist die Einführung zirkulärer Abhängigkeiten innerhalb von Entitäts-Beziehungs-Diagrammen (ERD). Diese Schleifen entstehen, wenn eine Kette von Fremdschlüsselbeziehungen letztendlich wieder auf die ursprüngliche Entität verweist. Obwohl solche Strukturen isoliert betrachtet scheinbar logisch erscheinen, verursachen sie erhebliche Herausforderungen für die Datenverwaltung, die Abfrageoptimierung und die Systemstabilität.
Die Lösung dieser Probleme erfordert ein tiefes Verständnis der relationalen Theorie und sorgfältige architektonische Planung. Dieser Leitfaden untersucht die Mechanismen zirkulärer Abhängigkeiten, ihre Auswirkungen auf die Datenbankgesundheit und bewährte Strategien zur Umgestaltung von Schemata für optimale Leistung.
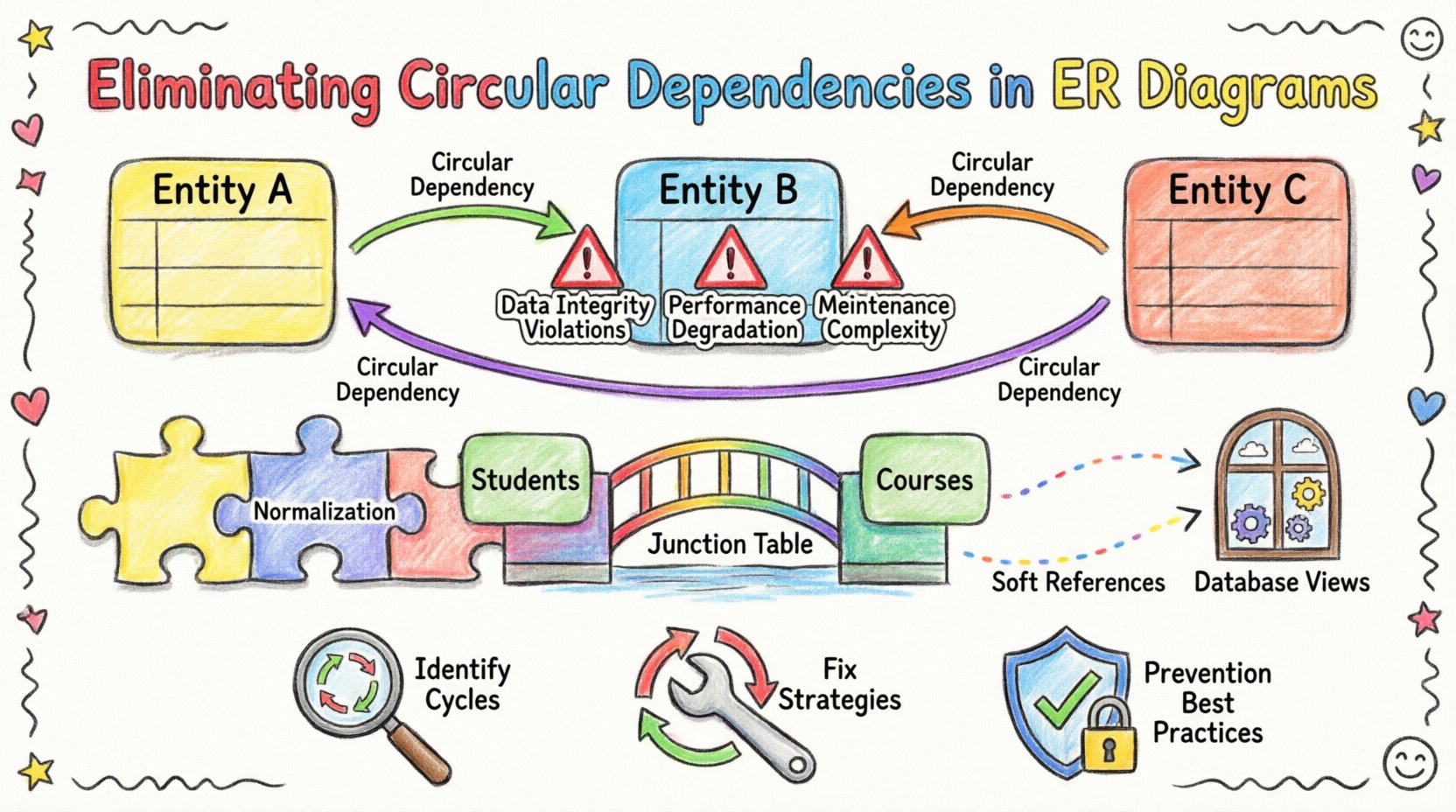
🧩 Verständnis zirkulärer Abhängigkeiten in ERD
Im Standard-Relational-Modell stellt eine Fremdschlüsselbeschränkung eine Verbindung von einer Kindtabelle zu einer Elterntabelle her. Diese Verbindung gewährleistet die Referenzintegrität und stellt sicher, dass die Daten in der Kindtabelle gültigen Einträgen in der Elterntabelle entsprechen. Eine zirkuläre Abhängigkeit entsteht, wenn diese Kette nicht sauber endet. Stattdessen verweist Entity A auf Entity B, das wiederum auf Entity C verweist, das letztendlich auf Entity A verweist.
Betrachten Sie eine Situation mit einer hierarchischen Struktur. Wenn jeder Knoten in einem Baum sowohl seinen Elternknoten als auch seine Kindknoten kennen muss, können bidirektionale Beziehungen leicht Schleifen bilden. Ohne sorgfältige Handhabung kann die Datenbankengine die Reihenfolge der Operationen beim Daten-Einfügen oder -Löschen nicht lösen.
Arten zirkulärer Verweise
- Direkte Zyklen:Entity A verweist über einen Fremdschlüssel auf Entity B, und Entity B verweist über einen Fremdschlüssel zurück auf Entity A. Dies tritt häufig bei bidirektionalen Beziehungen auf, bei denen beide Seiten die andere verfolgen.
- Indirekte Zyklen:Eine Kette aus drei oder mehr Entitäten schließt sich wieder. Zum Beispiel A → B → C → A. Diese sind in komplexen Schemata visuell schwer zu erkennen.
- Selbstreferenzielle Schleifen:Eine Entität verweist auf sich selbst. Obwohl dies bei hierarchischen Daten (wie einer Mitarbeiter-Tabelle, in der ein Manager ebenfalls ein Mitarbeiter ist) üblich ist, kann eine falsche Implementierung zu einer unendlichen Rekursion führen.
⚠️ Die Auswirkungen ungeklärter Schleifen
Das unbehandelte Verbleiben zirkulärer Abhängigkeiten ist keine bloß theoretische Sorge. Es bringt greifbare Risiken für die Anwendungsschicht und die Datenbankengine selbst mit sich.
1. Verletzungen der Datenintegrität
Wenn die Datenbankengine versucht, Daten in eine Schleife einzufügen, muss sie die Reihenfolge der Operationen bestimmen. Wenn A voraussetzt, dass B existiert, und B voraussetzt, dass A existiert, kann keiner zuerst erstellt werden. Dies führt zu Einschränkungsverstößen. Obwohl einige Datenbanksysteme eine verzögerte Prüfung von Einschränkungen zulassen, führt die Abhängigkeit von dieser Funktion oft dazu, dass logische Fehler verschleiert werden.
2. Leistungsverschlechterung
Abfragen, die zirkuläre Pfade durchlaufen, können ineffizient werden. Join-Operationen innerhalb einer Schleife können dazu führen, dass der Optimierer suboptimale Ausführungspläne wählt. In den schlechtesten Fällen können rekursive Abfragen, die dazu dienen, eine Hierarchie zu durchlaufen, in endlose Schleifen geraten und CPU- und Speicherressourcen verbrauchen, bis die Verbindung beendet wird.
3. Wartungskomplexität
Die Änderung eines Schemas mit zirkulären Abhängigkeiten ist riskant. Das Löschen einer Tabelle innerhalb einer Schleife kann fehlschlagen, wenn Fremdschlüssel aktiv sind. Kaskadenlöschvorgänge können unerwartete Kettenreaktionen auslösen. Entwickler finden sich oft gezwungen, Logik auf Anwendungsebene zu schreiben, um Datenbankbeschränkungen zu umgehen, was die Verantwortung für die Integrität von der Quelle der Wahrheit wegnimmt.
🔍 Identifizierung zirkulärer Abhängigkeiten
Bevor Sie das Problem beheben, müssen Sie es lokalisieren. Bei kleinen Diagrammen reicht eine visuelle Prüfung aus. Bei Systemen der Unternehmensklasse mit Hunderten von Tabellen ist die manuelle Nachverfolgung anfällig für Fehler. Verwenden Sie die folgenden Techniken, um Ihr Schema zu überprüfen.
- Graph-Analyse:Behandeln Sie das ERD als gerichteten Graphen. Knoten stellen Tabellen dar, und Kanten stellen Fremdschlüssel dar. Eine Schleife existiert, wenn ein Pfad zurück zum Ausgangsknoten führt.
- Abhängigkeitsbäume:Erstellen Sie für jede Tabelle einen Abhängigkeitsbaum. Wenn eine Tabelle in diesem Baum als eigener Vorfahre erscheint, existiert eine Schleife.
- Abfragen von Systemtabellen:Die meisten Datenbankverwaltungssysteme speichern Fremdschlüssel-Metadaten in Systemkatalogen. Schreiben Sie Abfragen, um diese Beziehungen programmatisch zu durchlaufen.
🛠️ Strategien zur Lösung
Sobald sie identifiziert wurden, müssen zirkuläre Abhängigkeiten aufgelöst werden. Ziel ist es, die logische Beziehung beizubehalten, ohne eine physische Schleife zu erzeugen. Nachfolgend sind die wichtigsten Methoden zur Erreichung dieses Zieles aufgeführt.
1. Schema normalisieren
Die Normalisierung ist der Prozess der Datenorganisation zur Reduzierung von Redundanz und Verbesserung der Integrität. Zirkuläre Abhängigkeiten entstehen oft aus dem Versuch, Beziehungen zu modellieren, die nicht auf einer einzigen Abstraktionsebene gehören.
- Dritte Normalform (3NF):Stellen Sie sicher, dass nichtschlüsselbasierte Attribute sich ausschließlich auf den Primärschlüssel beziehen. Wenn eine Tabelle einen Fremdschlüssel auf sich selbst enthält, um eine Hierarchie darzustellen, überlegen Sie, die Hierarchielogik in eine separate Beziehungstabelle zu verlegen.
- Redundanz entfernen: Wenn Entity A und Entity B sich gegenseitig referenzieren, fragen Sie sich, ob eine der Referenzen überflüssig ist. Kann die Beziehung nur in einer Richtung dargestellt werden?
2. Einführung einer Verbindungstabelle
Viele-zu-viele-Beziehungen sind eine häufige Quelle zirkulärer Schleifen. Statt Fremdschlüssel direkt in die primären Entitäten zu setzen, verwenden Sie eine Zwischentabelle.
Zum Beispiel, wennSchüler und Kurseeine viele-zu-viele-Beziehung haben, fügen Sie keinen kurs_id zur Tabelle Schüler und keinen schüler_id zur Tabelle Kurse Tabelle. Stattdessen erstellen Sie eine AnmeldungenTabelle, die beide IDs enthält. Dadurch wird die direkte Verbindung zwischen den beiden Hauptentitäten aufgehoben.
3. Ansichten für logische Beziehungen verwenden
Manchmal muss die physische Speicherung nicht die logische Anforderung widerspiegeln. Wenn die Anwendung eine Beziehung zwischen A und B sehen muss, aber deren direkte Speicherung eine Schleife erzeugt, verwenden Sie eine Datenbankansicht.
- Physisches Modell: Speichern Sie A und B ohne direkte Fremdschlüsselverknüpfung.
- Logisches Modell: Erstellen Sie eine Ansicht, die A und B basierend auf einem gemeinsamen Attribut oder einer separaten Beziehungstabelle verknüpft.
Dies trennt die Speicherbeschränkungen von der Anwendungslogik, wodurch die Datenbank die Integrität dort durchsetzen kann, wo sie wichtig ist, ohne physische Schleifen zu erzeugen.
4. Implementieren Sie weiche Verweise
In einigen Fällen ist eine strenge Referenzintegrität für die Beziehung nicht erforderlich. Sie können die ID der zugehörigen Entität als einfache Ganzzahlspalte speichern, anstatt eine Fremdschlüsselbeschränkung zu verwenden.
- Vorteile: Entfernt die Beschränkungsprüfung bei Einfügen/Löschen, wodurch die Schleife physisch existieren kann, ohne Operationen zu blockieren.
- Nachteile: Die Datenbank erzwingt die Beziehung nicht mehr. Die Anwendungslogik muss validieren, dass die referenzierte ID existiert.
📊 Vergleich von Refactoring-Ansätzen
| Ansatz | Komplexität | Durchsetzung der Integrität | Beste Einsatzmöglichkeit |
|---|---|---|---|
| Normalisierung | Hoch | Vollständig | Wenn Datenredundanz die Ursache ist. |
| Zwischentabelle | Mittel | Vollständig | Mehrzeilige Beziehungen. |
| Ansichten | Niedrig | Teilweise (Abfrageebene) | Berichterstattung oder Lese-lastige Workloads. |
| Weiche Verweise | Niedrig | Keine (Anwendungsebene) | Veraltete Systeme oder optionale Beziehungen. |
🛡️ Verhinderung und Best Practices
Sobald ein Schema refaktorisiert wurde, verschiebt sich der Fokus auf die Verhinderung zukünftiger Schleifen. Gestaltungsmuster und Governance-Prozesse können das Risiko der erneuten Einführung dieser Probleme verringern.
1. Beziehungsrichtung definieren
Legen Sie eine Regel fest, dass Fremdschlüssel immer in eine bestimmte Richtung fließen sollen. Zum Beispiel verweisen Kindtabellen immer auf Eltern, niemals umgekehrt. Wenn eine Elterntabelle auf Kinddaten zugreifen muss, verwenden Sie eine Abfrage oder eine Ansicht anstelle eines Fremdschlüssels.
2. Hierarchien sorgfältig modellieren
Selbstreferenzierende Tabellen sind üblich für Organigramme oder Kommentarverläufe. Um Schleifen zu vermeiden:
- Nur Eltern: Speichern Sie nur die
parent_id. Speichern Sie nichtchildren_idsin derselben Zeile. - Pfadenumeration: Bei tiefen Hierarchien speichern Sie die vollständige Pfadzeichenfolge (z. B.
/1/5/9/) um eine schnelle Abfrage ohne rekursive Joins zu ermöglichen.
3. Automatisierte Schema-Prüfungen
Integrieren Sie die Zykluserkennung in die CI/CD-Pipeline. Skripte können die Schema-Definitionsdateien (z. B. SQL-Migrationsdateien) parsen und alle neuen Fremdschlüsseldefinitionen markieren, die einen Zyklus verursachen, bevor die Bereitstellung erfolgt.
4. Dokumentation
Halten Sie ein aktuelles ERD auf dem neuesten Stand. Wenn ein Entwickler eine Tabelle hinzufügt, sollte er das Diagramm aktualisieren. Diese visuelle Hilfestellung hilft, potenzielle Zyklen zu erkennen, bevor Code geschrieben wird. Werkzeuge, die Dokumentation automatisch aus dem Datenbankschema generieren, werden für große Teams dringend empfohlen.
🔄 Umgang mit veralteten Systemen
Ein Refactoring einer Produktionsdatenbank ist aufgrund von Ausfallkosten oder Datenmenge nicht immer möglich. In solchen Fällen ist ein schrittweiser Ansatz notwendig.
- Kritische Pfade identifizieren:Priorisieren Sie das Aufbrechen von Zyklen, die die am häufigsten abgerufenen Abfragen beeinflussen.
- Anwendungslogik nutzen:Verschieben Sie die Verwaltung der Beziehung vorübergehend in die Anwendungsschicht. Speichern Sie IDs als einfache Spalten und überprüfen Sie sie im Code.
- Migration planen:Planen Sie einen Wartungszeitraum, um die Anwendungsebenen-Verweise nach Stabilisierung der neuen Struktur in physische Einschränkungen umzuwandeln.
📝 Letzte Überlegungen zur Schema-Gesundheit
Ein sauberes ERD ist die Grundlage einer robusten Anwendung. Zirkuläre Abhängigkeiten sind ein Zeichen dafür, dass das Design die Bequemlichkeit gegenüber der Struktur bevorzugt hat. Durch Einhaltung der Normalisierungsprinzipien und gegebenenfalls Nutzung von Verbindungstabellen können Sie sicherstellen, dass Ihre Daten konsistent und abfragbar bleiben.
Denken Sie daran, dass die Datenbankgestaltung iterativ ist. Mit sich ändernden Geschäftsanforderungen ändern sich auch die Beziehungen. Überprüfen Sie regelmäßig Ihr Schema, um sicherzustellen, dass es weiterhin Ihren Zielen entspricht. Kontinuierliche Validierung und eine disziplinierte Herangehensweise an Fremdschlüssel halten Ihre Architektur widerstandsfähig gegenüber der Komplexität wachsender Datenanforderungen.