











Die Gestaltung einer robusten Datenbankstruktur erfordert Präzision und Weitsicht. Das Entity-Relationship-Diagramm (ERD) dient als grundlegende Bauplan für diese Architektur. Ohne eine klare Karte entstehen Datenredundanz und Abfrageengpässe schnell, was im Laufe der Zeit zu einer Leistungsverschlechterung führt. Dieser Leitfaden untersucht, wie Optimierungstechniken direkt aus diesen visuellen Modellen abgeleitet werden können. Wir konzentrieren uns auf strukturelle Integrität und Leistungsoptimierung, ohne auf spezifische Plattformfunktionen oder proprietäre Werkzeuge zurückzugreifen. Durch das Verständnis der zugrundeliegenden Beziehungen können Sie Systeme aufbauen, die effizient skalieren.
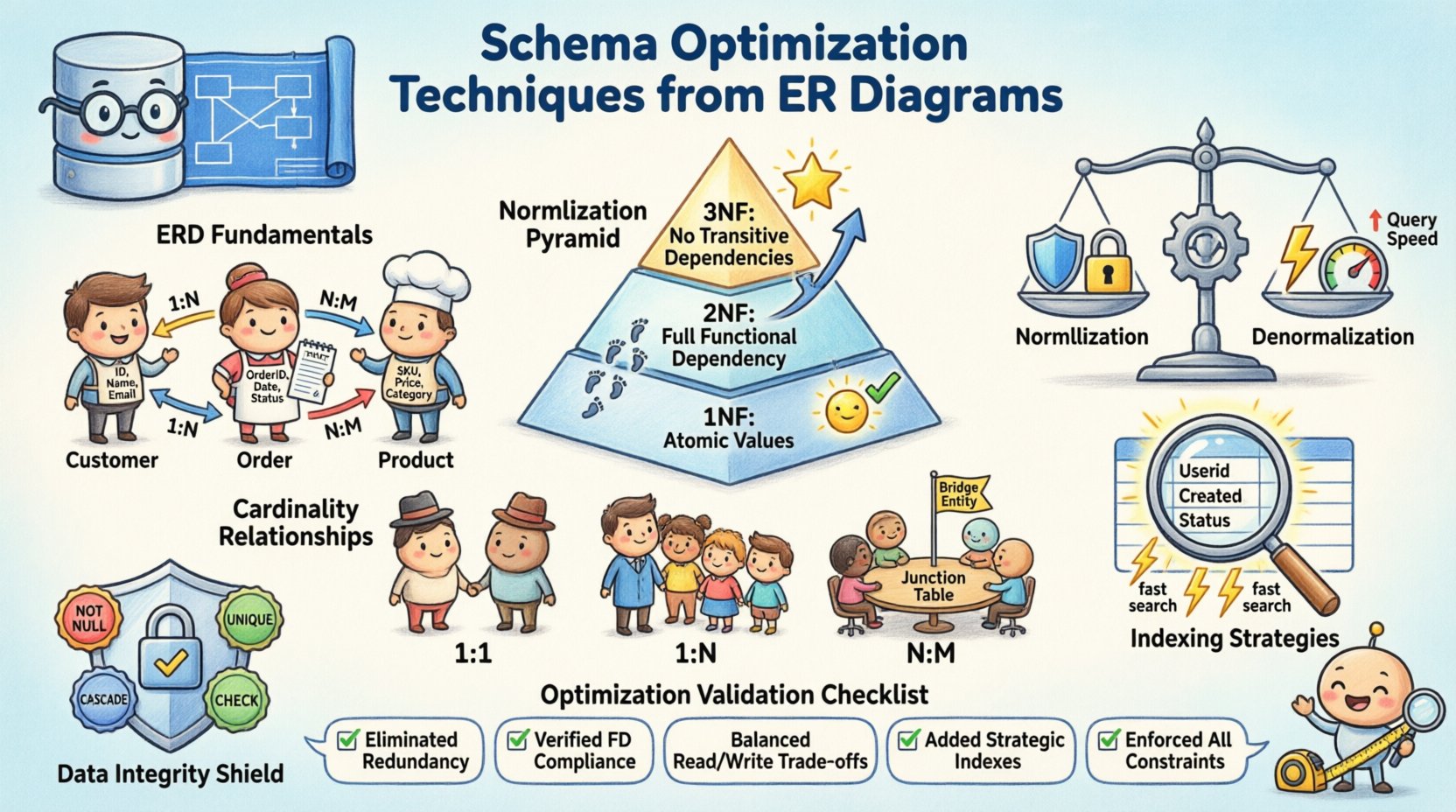
📐 Verständnis der ERD-Grundlagen
Bevor die Optimierung beginnt, müssen die zentralen Komponenten klar sein. Ein ER-Diagramm übersetzt geschäftliche Anforderungen in ein logisches Datenmodell. Es definiert, wie Informationen gespeichert und abgerufen werden. Eine solide Grundlage verhindert strukturelle Schulden später im Entwicklungszyklus. Berücksichtigen Sie die folgenden Elemente:
- Entitäten: Stellen Objekte oder Konzepte dar, wie Kunden, Bestellungen oder Produkte. Jede Entität wird in der physischen Schemastruktur zu einer Tabelle.
- Attribute: Definieren Eigenschaften von Entitäten, wie Name, ID oder Zeitstempel. Diese werden zu Spalten innerhalb der Tabellen.
- Beziehungen: Zeigen, wie Entitäten miteinander interagieren. Diese bestimmen die Verwendung von Fremdschlüsseln und Einschränkungen.
Die Visualisierung dieser Komponenten ermöglicht es Ihnen, potenzielle Probleme zu erkennen, bevor Sie eine einzige Codezeile schreiben. Es stellt sicher, dass der logische Ablauf den physischen Speicheranforderungen entspricht. Diese Ausrichtung ist entscheidend, um die Datenkonsistenz in komplexen Anwendungen aufrechtzuerhalten.
🔨 Normalisierungsstrategien für Datenintegrität
Die Normalisierung ist der Prozess der Organisation von Daten, um Redundanz zu reduzieren und die Integrität zu verbessern. Dabei werden große Tabellen in kleinere, logische Einheiten aufgeteilt. Während eine übermäßige Normalisierung das Lesen verlangsamen kann, führt das vollständige Weglassen dazu, dass Aktualisierungsanomalien entstehen. Ziel ist es, das Gleichgewicht zu finden, das Ihrer spezifischen Arbeitslast entspricht.
Erste Normalform (1NF)
Die erste Regel verlangt, dass jede Spalte atomare Werte enthält. Wiederholte Gruppen oder Arrays sind innerhalb einer einzigen Zelle nicht erlaubt. Dies stellt sicher, dass jedes Datenstück eindeutig und abfragbar ist. Zum Beispiel sollte eine Liste von Telefonnummern in separate Zeilen oder eine zugehörige Tabelle aufgeteilt werden, nicht als durch Kommas getrennte Zeichenkette gespeichert werden.
Zweite Normalform (2NF)
Sobald 1NF erfüllt ist, behandelt 2NF partielle Abhängigkeiten. Alle nicht-schlüsselbasierten Attribute müssen sich auf den gesamten Primärschlüssel beziehen. Bei zusammengesetzten Schlüsseln verhindert dies Datenredundanz, bei der nur ein Teil des Schlüssels ein Attribut bestimmt. Dieser Schritt verfeinert die Struktur, um sicherzustellen, dass jedes Informationsstück korrekt mit seinem Elternobjekt verknüpft ist.
Dritte Normalform (3NF)
Die dritte Form beseitigt transitive Abhängigkeiten. Nicht-schlüsselbasierte Attribute sollten nicht von anderen nicht-schlüsselbasierten Attributen abhängen. Das bedeutet, wenn Attribut A von Attribut B abhängt und B vom Schlüssel abhängt, sollte A nicht in derselben Tabelle existieren. Das Verschieben solcher Daten in eine separate Tabelle verbessert die Wartbarkeit und reduziert Speicherverschwendung.
Die folgende Tabelle fasst die Entwicklung der Normalisierung zusammen:
| Normalform | Hauptziel | Schlüsselbeschränkung |
|---|---|---|
| 1NF | Atomare Werte | Keine wiederholten Gruppen |
| 2NF | Vollständige Abhängigkeit | Partielle Abhängigkeiten entfernen |
| 3NF | Unabhängigkeit | Transitive Abhängigkeiten entfernen |
⚡ Denormalisierung zur Leistungssteigerung
Während die Normalisierung die Integrität gewährleistet, erfordert sie oft komplexe Joins bei Abfragen. In lesedichten Systemen kann die Overhead-Kosten durch das Verknüpfen mehrerer Tabellen zu einer Engstelle werden. Die Denormalisierung führt bewusst Redundanz ein, um die Abrufgeschwindigkeit zu verbessern. Dies ist ein Kompromiss zwischen Speichereffizienz und Abfrageleistung.
Berücksichtigen Sie die folgenden Szenarien, in denen eine Denormalisierung angemessen ist:
- Berichts-Boards: Aggregierte Daten können vorab berechnet und gespeichert werden, um Echtzeitberechnungen zu vermeiden.
- Caching-Ebenen: Häufig abgerufene Daten können in einem lesungsoptimierten Speicher dupliziert werden.
- Hochdurchsatz-Transaktionen: Die Reduzierung der Join-Tiefe minimiert die Sperrkonkurrenz und die CPU-Nutzung.
Bei der Implementierung sollte ein klarer Prozess für die Aktualisierung der redundanten Daten festgelegt werden. Inkonsistenzen entstehen, wenn die Quelle der Wahrheit sich ändert, ohne dass die Kopien aktualisiert werden. Automatisierte Trigger oder Anwendungslogik müssen die Synchronisation übernehmen, um die Genauigkeit zu gewährleisten.
🔗 Verwaltung von Kardinalität und Beziehungen
Die Kardinalität definiert die numerische Beziehung zwischen Entitäten. Sie bestimmt, wie Fremdschlüssel implementiert werden und wie Daten verknüpft sind. Das Verständnis dieser Muster ist entscheidend, um verwaiste Datensätze zu vermeiden und die Referenzintegrität sicherzustellen.
- Ein-zu-Eins: Selten in allgemeinen Systemen, oft verwendet für Sicherheits- oder Erweiterungstabellen. Eine einzelne Zeile in Tabelle A verweist genau auf eine Zeile in Tabelle B.
- Ein-zu-Viele: Die häufigste Beziehung. Eine übergeordnete Datensatz verweist auf mehrere untergeordnete Datensätze. Der Fremdschlüssel befindet sich in der Kindtabelle.
- Viele-zu-Viele: Erfordert eine Verbindungstabelle zur Auflösung der Beziehung. Diese Zwischentabelle verknüpft die Primärschlüssel beider Entitäten.
Falsche Annahmen zur Kardinalität führen zu ineffizientem Speicherplatz oder ungültigen Datenzuständen. Beispielsweise verhindert die Behandlung einer Viele-zu-Viele-Beziehung als einfache Spalte mehrfache Verknüpfungen. Die korrekte Modellierung dieser Verbindungen stellt sicher, dass die Datenbank die in der Darstellung definierten Geschäftsregeln erzwingen kann.
📉 Indexierungsstrategien basierend auf struktureller Analyse
Indizes sind die Methode, die es dem Datenbank-Engine ermöglicht, Daten schnell zu finden. Die Struktur des ERD gibt direkt an, welche Spalten indiziert werden sollten. Blindes Hinzufügen von Indizes verbraucht Speicherplatz und verlangsamt Schreibvorgänge.
Wichtige Überlegungen bei der Indexierung umfassen:
- Primärschlüssel: Werden standardmäßig immer indiziert. Sie definieren die eindeutige Identität jeder Zeile.
- Fremdschlüssel: Erfordern oft eine Indexierung, um Joins und Constraint-Prüfungen zu beschleunigen.
- Komposite Schlüssel: Werden verwendet, wenn Abfragen nach mehreren Spalten filtern. Die Reihenfolge der Spalten im Index ist für die Leistung entscheidend.
- Selektive Spalten:Indizieren Sie Spalten mit hoher Kardinalität. Geringe Selektivität (z. B. Geschlecht) profitiert selten von einem Index.
Analysieren Sie Ihre Abfragemuster im Vergleich zur Schema-Design. Wenn eine bestimmte Verknüpfung häufig ausgeführt wird, stellen Sie sicher, dass die Fremdschlüsselspalte indiziert ist. Dies reduziert die Zeit, die die Datenbank mit dem Scannen ganzer Tabellen verbringt.
🛡️ Datenintegrität und referenzielle Einschränkungen
Integritätsbeschränkungen schützen die Genauigkeit und Konsistenz der Daten. Sie wirken als Schutzschiene gegen ungültige Eingaben oder versehentliche Löschungen. Während einige Beschränkungen von der Anwendung durchgesetzt werden, sind datenbankbasierte Beschränkungen zuverlässiger.
Häufige Beschränkungstypen umfassen:
- NICHT NULL:Stellt sicher, dass eine Spalte immer einen Wert enthält. Verhindert Lücken in kritischen Datenfeldern.
- EINDEUTIG:Stellt sicher, dass keine zwei Zeilen denselben Wert in einer bestimmten Spalte teilen. Nützlich für E-Mail-Adressen oder Benutzernamen.
- CASCADE:Definiert, was mit Kind-Records geschieht, wenn ein Eltern-Record gelöscht wird. Optionen sind einschränken, durchführen oder auf NULL setzen.
- CHECK:Setzt bestimmte Bedingungen für Datenwerte durch, wie z. B. Datumsbereiche oder numerische Grenzen.
Die Implementierung dieser Regeln auf Datenbankebene verhindert, dass die Anwendung jedes einzelne Datenfeld validieren muss. Sie zentralisiert die Logik für die Daten Gültigkeit, reduziert Code-Duplikate und mögliche Fehler.
🔄 Iterative Verbesserung und Schema-Evolution
Das Schema-Design ist keine einmalige Aufgabe. Geschäftsanforderungen ändern sich, und das Datenmodell muss sich weiterentwickeln. Regelmäßige Überprüfungen des ERD und des physischen Schemas helfen, Bereiche zur Verbesserung zu identifizieren. Die Überwachung der Abfrageleistung liefert Einblicke in Bereiche, in denen die Struktur Schwierigkeiten hat.
Bei der Verbesserung sollten die folgenden Schritte berücksichtigt werden:
- Überprüfung der Index-Nutzung:Entfernen Sie nicht verwendete Indizes, um die Schreib-Overhead zu reduzieren.
- Überprüfung der Partitionierung:Große Tabellen können von der Aufteilung der Daten basierend auf Bereichen oder Schlüsseln profitieren.
- Aktualisierung der Kardinalität:Wenn sich die Geschäftslogik ändert, können Beziehungen von ein-zu-viele zu viele-zu-viele wechseln.
- Versionskontrolle:Behandeln Sie Schema-Änderungen wie Code. Verfolgen Sie Änderungen, um bei Bedarf eine Rückgängigmachung zu ermöglichen.
Dieser iterative Ansatz stellt sicher, dass die Datenbank im Laufe der Zeit mit den Anforderungen der Anwendung übereinstimmt. Er verhindert die Ansammlung technischer Schulden, die die zukünftige Entwicklung verlangsamen.
✅ Optimierungs-Checkliste
Verwenden Sie diese Liste, um Ihr Schema-Design vor der Bereitstellung zu überprüfen:
- Stellen Sie sicher, dass alle Tabellen mindestens der dritten Normalform (3NF) entsprechen.
- Stellen Sie sicher, dass Fremdschlüssel indiziert sind, wo Verknüpfungen häufig vorkommen.
- Überprüfen Sie auf zirkuläre Abhängigkeiten in Beziehungen.
- Bestätigen Sie, dass für jede Tabelle Primärschlüssel definiert sind.
- Überprüfen Sie Einschränkungen, um sicherzustellen, dass Regeln zur Datenkonsistenz durchgesetzt werden.
- Analysieren Sie Abfragemuster, um mögliche Möglichkeiten zur De-Normalisierung zu identifizieren.
- Dokumentieren Sie alle Annahmen bezüglich der Datenkardinalität und -menge.
Durch die Einhaltung dieser Schritte entsteht eine widerstandsfähige Grundlage für die Datenspeicherung. Es ermöglicht dem System, Wachstum zu bewältigen, ohne eine vollständige Neukonstruktion zu erfordern. Eine gut optimierte Schema ist der Unterschied zwischen einer träge reagierenden Anwendung und einer reaktionsschnellen.