











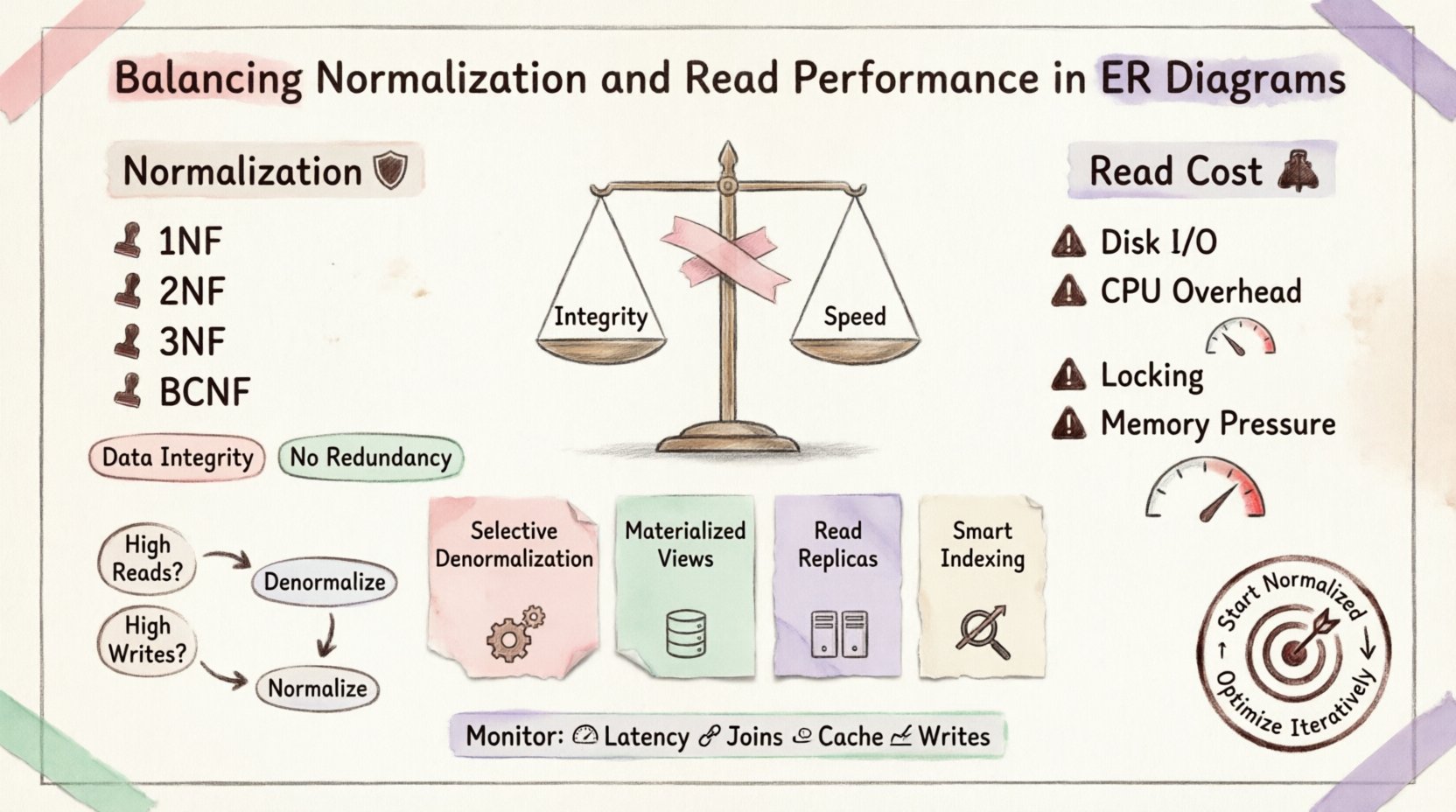
Die Gestaltung einer Datenbank-Schema ist selten eine binäre Wahl zwischen Geschwindigkeit und Struktur. Es ist ein Übung in Kompromissen. Wenn Architekten Entitäts-Beziehungs-Diagramme (ERD) erstellen, stehen sie oft vor der Spannung zwischen strenger Datenintegrität und der rohen Geschwindigkeit, die für Anwendungen mit hoher Datenmenge erforderlich ist. Die Normalisierung minimiert Redundanz und stellt sicher, dass die Daten konsistent bleiben. Der Preis für die Aufrechterhaltung dieser Konsistenz wird jedoch oft in Form einer eingeschränkten Leseleistung bezahlt.
Dieser Artikel untersucht die technischen Feinheiten dieses Gleichgewichts. Wir werden analysieren, wie die Normalisierung Joins beeinflusst, wie Lese-lastige Workloads Schema-Änderungen vorgeben und wo die Grenze zwischen einer gut strukturierten Datenbank und einer leistungsfähigen liegt.
Verständnis der Normalisierung: Die Grundlage 🛡️
Die Normalisierung ist der Prozess der Organisation von Daten, um Redundanz zu reduzieren und die Datenintegrität zu verbessern. Dabei werden große Tabellen in kleinere, logische aufgeteilt und Beziehungen zwischen ihnen definiert. Ziel ist es, Anomalien bei Einfügung, Aktualisierung und Löschung zu vermeiden.
Wichtige Normalformen
-
Erste Normalform (1NF): Stellt Atomarität sicher. Jede Spalte enthält nur einen Wert. Keine wiederholten Gruppen.
-
Zweite Normalform (2NF): Baut auf 1NF auf. Alle nicht-schlüsselbasierten Attribute müssen vollständig vom Primärschlüssel abhängen. Entfernt partielle Abhängigkeiten.
-
Dritte Normalform (3NF): Baut auf 2NF auf. Entfernt transitive Abhängigkeiten. Nicht-schlüsselbasierte Attribute hängen nur vom Schlüssel, dem ganzen Schlüssel und nichts sonst ab.
-
Boyce-Codd-Normalform (BCNF): Eine strengere Version der 3NF zur Behandlung spezifischer Abhängigkeitsanomalien.
Während die Einhaltung dieser Formen eine saubere Datenbank garantiert, führt sie zu Komplexität bei Abfragen. Jede Beziehung, die im ER-Diagramm definiert ist, wird zu einer möglichen Join-Operation.
Die Kosten der Lesevorgänge 💸
Wenn Sie Daten normalisieren, teilen Sie die Informationen oft über mehrere Tabellen auf. Um ein vollständiges Datensatz zu erhalten, muss die Datenbankengine Join-Operationen durchführen. Joins sind rechenintensiv.
Warum Joins Abfragen verlangsamen
-
Platten-I/O: Wenn Tabellen nicht perfekt indiziert oder im Cache gespeichert sind, muss die Engine Daten an verschiedenen physischen Orten auf der Festplatte suchen.
-
CPU-Aufwand: Die Datenbank muss Schlüssel aus einer Tabelle mit denen aus einer anderen Tabelle abgleichen. Dafür ist erheblicher Rechenaufwand erforderlich.
-
Sperrkonkurrenz: Komplexe Joins können Sperrungen länger halten und andere Transaktionen daran hindern, auf verwandte Daten zuzugreifen.
-
Speicherdruck: Große Join-Operationen erfordern erhebliche Speicherpuffer zum Sortieren und Hashen von Daten.
In einer Lese-lastigen Umgebung, wie beispielsweise einem Berichts-Dashboard oder einer öffentlich zugänglichen API, ist diese Latenz unakzeptabel. Benutzer erwarten sofortige Rückmeldungen. Eine Abfrage, die 100 Millisekunden benötigt, um normalisierte Daten zurückzugeben, könnte bei einer Denormalisierung nur 10 Millisekunden dauern.
Strategien zur Optimierung 🚀
Um Integrität und Geschwindigkeit ins Gleichgewicht zu bringen, setzen Architekten spezifische Muster ein. Diese Strategien ermöglichen es Ihnen, die Datenbank dort, wo es am wichtigsten ist, normalisiert zu halten, während sie dort, wo es zählt, für Lesevorgänge optimiert wird.
1. Selektive Denormalisierung
Nicht alle Tabellen müssen vollständig normalisiert sein. Identifizieren Sie die am häufigsten abgerufenen Daten und speichern Sie sie redundant. Zum Beispiel spart das Speichern des Benutzernamens direkt in der Bestellungs-Tabelle, wenn Sie häufig Benutzernamen zusammen mit deren Bestellverlauf abfragen, einen Join.
2. Materialisierte Ansichten
Eine materialisierte Ansicht speichert das Ergebnis einer Abfrage physisch auf der Festplatte. Es handelt sich im Wesentlichen um eine vorberechnete Tabelle. Wenn sich die Daten ändern, muss die Ansicht aktualisiert werden. Dies ist ideal für komplexe Aggregationen, die keine Echtzeitgenauigkeit erfordern.
3. Lese-Replikate
Trennen Sie die Lese-Arbeitslast von der Schreib-Arbeitslast. Leiten Sie alle Schreibvorgänge an die primäre Datenbank, die weiterhin normalisiert bleibt. Leiten Sie alle Lesevorgänge an eine Replikat. Dadurch kann das Replikat anders optimiert werden, beispielsweise mit mehr Indizes oder de-normalisierten Strukturen, ohne die Transaktionsintegrität zu beeinträchtigen.
4. Indexstrategie
Selbst normalisierte Datenbanken können mit den richtigen Indizes gut performen. Deckende Indizes ermöglichen es der Datenbank, eine Abfrage ausschließlich anhand des Indexes zu erfüllen und Tabellen-Abfragen zu vermeiden. Zusammengesetzte Indizes können Joins auf häufig verwendeten Fremdschlüsseln beschleunigen.
Wann man de-normalisieren sollte 📉
Die De-Normalisierung ist eine bewusste Entscheidung, kein Standardzustand. Sie sollte auf Grundlage von Leistungsüberwachungsdaten, nicht aufgrund von Annahmen, getroffen werden.
|
Szenario |
Ansatz |
Begründung |
|---|---|---|
|
Hohe Schreibhäufigkeit |
Normalisiert belassen |
Aktualisierungen sind schneller. Weniger Redundanz muss aufrechterhalten werden. |
|
Hohe Lesehäufigkeit |
De-Normalisierung in Betracht ziehen |
Reduziert Joins. Schnellere Abrufzeiten. |
|
Datenkonsistenz ist entscheidend |
Normalisiert belassen |
Ein einziges Quell-System verhindert Datenverschiebung. |
|
Berichterstattung und Analytik |
De-normalisieren |
Aggregationen sind komplex; vorab berechnen hilft. |
|
Skalierungsanforderungen |
Hybrider Ansatz |
Dienste aufteilen oder Caching-Ebenen nutzen. |
Der Kompromiss: Datenintegrität gegenüber Geschwindigkeit ⚙️
Jedes Mal, wenn Sie Redundanz einführen, besteht die Gefahr von Dateninkonsistenzen. Wenn ein Benutzer seine E-Mail-Adresse ändert, aber die E-Mail in beiden Tabellen gespeichert ist,Benutzer Tabelle und die Benachrichtigungen Tabelle kann ein Update fehlschlagen oder verpasst werden. Dies ist als Update-Anomalie bekannt.
Um dies zu minimieren, muss die Anwendungslogik robust sein. Trigger können Konsistenz erzwingen, fügen aber Komplexität hinzu. Alternativ kann das Schema so gestaltet werden, dass die de-normalisierten Daten abgeleitet und unveränderlich sind, wodurch das Risiko von Abweichungen reduziert wird.
Umgang mit Konsistenz
-
Anwendungslogik:Schreiben Sie Code, der alle redundanten Kopien atomar aktualisiert.
-
Datenbanktrigger:Lassen Sie die Datenbank Regeln automatisch durchsetzen. Dadurch bleibt die Logik nahe am Daten.
-
Eventuelle Konsistenz:Akzeptieren Sie, dass die Daten für eine kurze Zeit veraltet sein können. Verwenden Sie Hintergrundaufgaben, um redundante Daten zu synchronisieren.
Überwachung und Wartung 🔧
Ein statisches Design berücksichtigt keine sich ändernden Nutzungsmuster. Was heute funktioniert, könnte nächstes Jahr zu Engpässen führen. Eine kontinuierliche Überwachung ist unerlässlich.
Wichtige Metriken zur Überwachung
-
Abfrageverzögerung:Überwachen Sie die Zeit, die für kritische Leseabfragen benötigt wird.
-
Anzahl der Joins:Verfolgen Sie die Anzahl der Joins pro komplexe Abfrage.
-
Cache-Trefferquote:Wenn Sie Caching verwenden, prüfen Sie, ob es die Datenbanklast effektiv reduziert.
-
Schreibverzögerung:Stellen Sie sicher, dass die De-Normalisierung die Schreibvorgänge nicht zu sehr verlangsamt.
Fazit: Eine kontextabhängige Entscheidung 🎯
Es gibt keinen universellen Standard für die Datenbankgestaltung. Das beste ER-Diagramm ist das, das zu Ihrer spezifischen Arbeitslast passt. Normalisierung bietet Sicherheit; De-Normalisierung bietet Geschwindigkeit. Das Ziel ist es, den Gleichgewichtspunkt zu finden.
Beginnen Sie mit einer normalisierten Gestaltung, um die Datenintegrität zu gewährleisten. Sobald Leistungsengpässe auftreten, identifizieren Sie die spezifischen Abfragen, die Verzögerungen verursachen. Wenden Sie De-Normalisierung oder Caching nur an diesen Stellen an. Dieser iterative Ansatz verhindert vorzeitige Optimierung und stellt sicher, dass das System langfristig wartbar bleibt.
Denken Sie daran, dass die Technologie sich weiterentwickelt. Neue Speicher-Engines und Abfrage-Optimierer verringern weiterhin die Kosten für Joins. Überprüfen Sie regelmäßig Ihr Schema im Hinblick auf aktuelle Möglichkeiten. Das Gleichgewicht verschiebt sich, und Ihre Gestaltung muss sich mit ihm verschieben.
Durch das Verständnis der Mechanismen der Normalisierung und der Realitäten der Leseleistung können Sie Systeme bauen, die sowohl robust als auch reaktionsfreudig sind. Konzentrieren Sie sich auf die Daten, nicht nur auf den Code.