











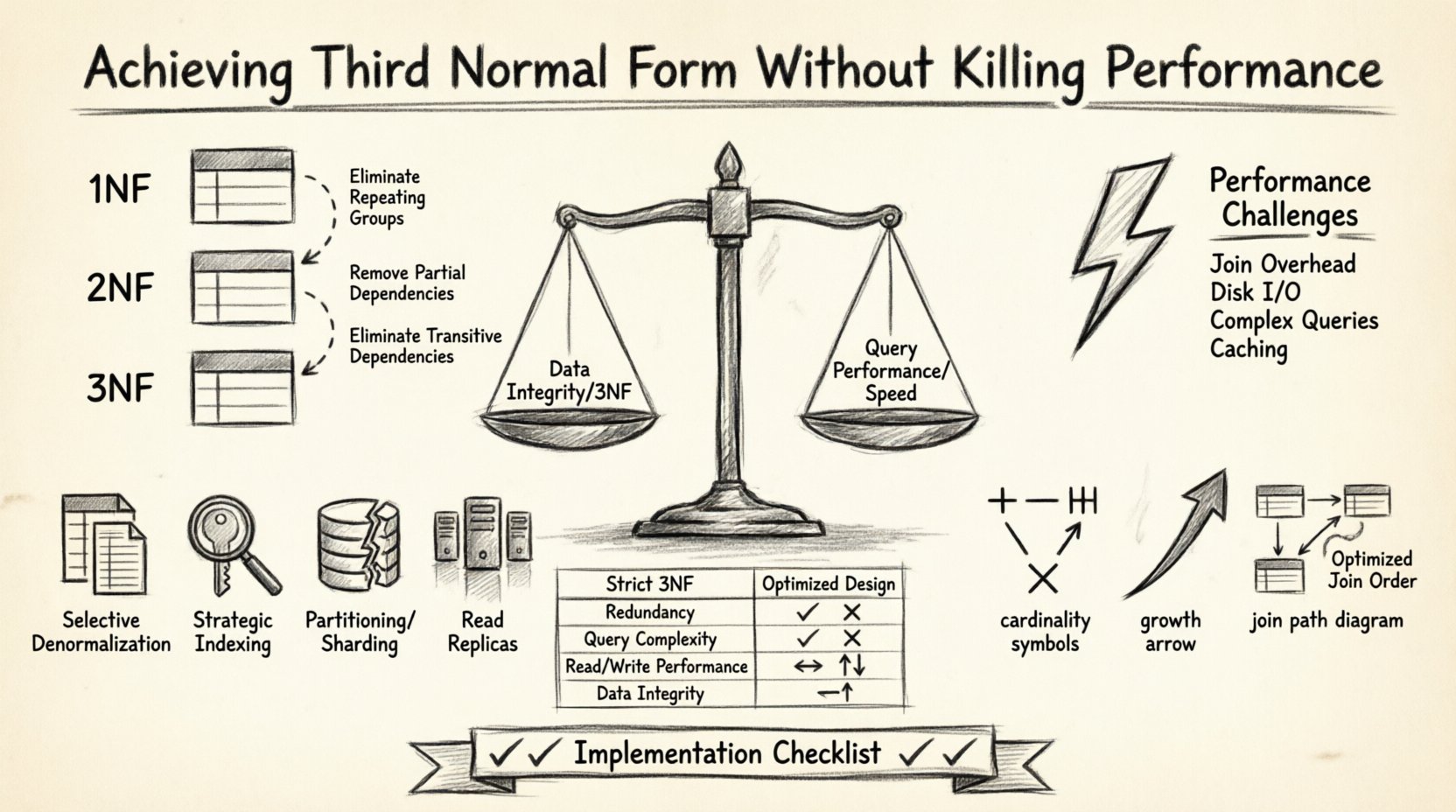
Die Gestaltung einer robusten Datenbankstruktur ist ein Ausgleichsakt. Auf der einen Seite steht die Datenintegrität und die Beseitigung von Redundanz durch Normalisierung. Auf der anderen Seite steht die Abfragegeschwindigkeit und die Reaktionsfähigkeit des Systems. Viele Datenbankarchitekten stehen vor einer schwierigen Entscheidung: strikte Normalisierungsregeln beibehalten und das Risiko langsamer Abfragen eingehen, oder stark denormalisieren und das Risiko von Dateninkonsistenzen eingehen. Das Ziel ist es, eine Mittelposition zu finden, in der die Datenbank der dritten Normalform (3NF) folgt, während gleichzeitig eine hohe Leistung aufrechterhalten wird. In diesem Artikel wird untersucht, wie man Entity-Relationship-Diagramme (ERD) gestaltet, um dieses Gleichgewicht zu erreichen, ohne die Integrität oder die Geschwindigkeit zu beeinträchtigen.
Verständnis der dritten Normalform 🧩
Die dritte Normalform ist ein spezifischer Grad der Datenbanknormalisierung. Bevor man die 3NF erreicht, muss eine Tabelle zunächst die erste Normalform (1NF) und die zweite Normalform (2NF) erfüllen. Der zentrale Grundsatz der 3NF besagt, dass alle Attribute sich ausschließlich auf den Primärschlüssel beziehen müssen. Es dürfen keine transitiven Abhängigkeiten bestehen.
- Erste Normalform: Beseitigt wiederholte Gruppen und stellt atomare Werte sicher.
- Zweite Normalform: Beseitigt partielle Abhängigkeiten, bei denen Nicht-Schlüssel-Attribute sich nur auf einen Teil eines zusammengesetzten Schlüssels beziehen.
- Dritte Normalform: Beseitigt transitive Abhängigkeiten. Wenn A B bestimmt und B C bestimmt, dann sollte C in derselben Tabelle nicht direkt von A abhängen.
Wenn Sie die 3NF erreichen, minimieren Sie Aktualisierungsanomalien. Dabei handelt es sich um Fehler, die auftreten, wenn Daten an einer Stelle geändert werden, aber nicht an anderen, was zu Inkonsistenzen führt. Zum Beispiel, wenn die Adresse eines Kunden sowohl in der Tabelle Aufträge als auch in der Tabelle Kunden gespeichert ist, führt eine Änderung der Adresse in einer Tabelle, aber nicht in der anderen, zu einer Diskrepanz. Die 3NF zwingt Sie, diese Adresse an nur einer Stelle zu speichern.
Der Leistungsabwägung ⚡
Während die 3NF hervorragend für die Datenintegrität ist, geht sie oft mit einem Leistungsaufwand einher. Normalisierte Datenbanken erfordern typischerweise mehr Tabellen. Um ein vollständiges Datenset abzurufen, muss die Datenbankengine mehrere Joins durchführen. Jeder Join-Vorgang erfordert, dass das System Daten von der Festplatte oder aus dem Speicher liest, Schlüssel vergleicht und Ergebnisse zusammenführt.
Stellen Sie sich eine Berichtsabfrage vor, die Kundennamen, Auftragsdetails, Produktbeschreibungen und Versandadressen benötigt. Bei einer vollständig normalisierten 3NF-Struktur könnte dies das Verknüpfen von fünf oder mehr Tabellen erfordern. Wenn das Datenvolumen groß ist, können diese Joins zu einer Engstelle werden.
Hier sind die spezifischen Leistungsprobleme, die mit der 3NF verbunden sind:
- Erhöhter Join-Aufwand: Jede Beziehung erfordert während Leseabfragen einen Join-Vorgang.
- Disk-I/O:Die Verteilung der Daten über viele Tabellen erhöht die Anzahl der Seiten, die die Datenbankengine zugreifen muss.
- Komplexe Abfrage-Logik:Anwendungen müssen komplexere SQL-Anweisungen erstellen, um verwandte Daten abzurufen.
- Komplexität des Cachens:Das Cachen einer einzelnen denormalisierten Zeile ist einfacher als das Cachen mehrerer verwandter Zeilen.
Strategien zur Abwägung von Integrität und Geschwindigkeit 🚀
Sie müssen die Normalisierung nicht aufgeben, um die Leistung zu verbessern. Es gibt spezifische Techniken, um eine 3NF-Datenbank zu optimieren, ohne die Struktur zu verändern. Die folgenden Strategien helfen dabei, die Datenqualität zu erhalten, ohne die Geschwindigkeit zu opfern.
1. Selektive Denormalisierung
Nicht jede Tabelle muss streng 3NF sein. Identifizieren Sie die leseschweren Tabellen und die kritischen Datenpfade. Sie können kontrollierte Redundanz in diesen spezifischen Bereichen einführen. Zum Beispiel speichern Sie den Namen eines Kunden direkt in der BestellungenTabelle. Obwohl dadurch Daten dupliziert werden, ist die Leistungssteigerung bei der Bestellabfrage erheblich. Sie müssen dann einen Trigger oder Anwendungslogik implementieren, um diese Kopie aktualisiert zu halten, wenn sich der Kundeneintrag ändert.
2. Strategisches Indizieren
Indizes sind das primäre Werkzeug zur Beschleunigung von Joins. Ohne Indizes führt eine Datenbank für jede Join-Bedingung eine vollständige Tabellenabfrage durch. Mit geeigneten Indizes werden Abfragen nahezu sofort ausgeführt.
- Fremdschlüssel-Indizes: Indizieren Sie immer Spalten, die in Fremdschlüsselbeziehungen verwendet werden. Dadurch wird sichergestellt, dass das Verknüpfen von Tabellen schnell erfolgt.
- Komposite Indizes: Erstellen Sie Indizes auf mehreren Spalten, wenn Ihre Abfragen häufig nach dieser Kombination filtern.
- Deckende Indizes: Gestalten Sie Indizes, die alle Spalten enthalten, die für eine bestimmte Abfrage benötigt werden. Dadurch kann die Datenbank die Abfrage ausschließlich anhand des Indexes erfüllen und einen Zugriff auf die Haupttabellendaten vermeiden.
3. Partitionierung und Sharding
Wenn die Datensammlung zu groß wird, kann das Aufteilen der Tabellen die Leistung verbessern. Die Partitionierung teilt eine große Tabelle in kleinere, übersichtlichere physische Teile basierend auf einem Schlüssel, wie Datum oder Region. Das Sharding verteilt Daten über mehrere Datenbankinstanzen. Beide Methoden reduzieren die Menge an Daten, die die Engine scannen muss, um eine bestimmte Abfrage zu beantworten.
4. Lese-Replicas
Trennen Sie Ihre Schreibvorgänge von Ihren Lesevorgängen. Verwenden Sie eine primäre Datenbankinstanz für Transaktionen und Aktualisierungen. Replizieren Sie diese Daten auf eine oder mehrere schreibgeschützte Replikate. Komplexe Berichtsabfragen, die das System belasten, können auf den Replikaten ausgeführt werden, wodurch das Hauptsystem schnell für Benutzerinteraktionen bleibt.
ERD-Designüberlegungen 📐
Beim Zeichnen eines Entitäts-Beziehungs-Diagramms beeinflusst die visuelle Darstellung, wie Entwickler Abfragen schreiben. Ein klares ERD hilft, Beziehungen frühzeitig zu erkennen. Ein Diagramm, das auf Papier perfekt aussieht, kann jedoch in der Produktion schlecht performen. Hier ist, wie Sie beim ERD-Design für Leistung vorgehen sollten.
- Klare Identifizierung der Kardinalität: Stellen Sie sicher, dass jede Beziehung eine definierte Kardinalität hat (eins-zu-eins, eins-zu-viele, viele-zu-viele). Mehrdeutige Beziehungen führen zu ineffizienten Joins.
- Planen Sie für Wachstum: Berücksichtigen Sie zukünftige Datenmengen. Ein Design, das für 10.000 Zeilen funktioniert, könnte bei 10 Millionen Zeilen versagen.
- Überprüfen Sie Join-Pfade: Verfolgen Sie die Pfade, die eine häufige Abfrage durch das Diagramm nimmt. Wenn ein Pfad zu lang ist, überlegen Sie, eine de-normalisierte Spalte hinzuzufügen.
- Dokumentieren Sie Einschränkungen: Dokumentieren Sie explizit, welche Einschränkungen von der Datenbank und welche von der Anwendungsschicht verwaltet werden.
Vergleich: Normalisiertes vs. Optimiertes Design 📊
Die folgende Tabelle zeigt die Unterschiede zwischen einem strengen 3NF-Ansatz und einem optimierten Ansatz für einen bestimmten Fall.
| Funktion | Strenger 3NF-Entwurf | Optimierter Entwurf |
|---|---|---|
| Redundanz | Minimal | Kontrolliert und begrenzt |
| Abfragekomplexität | Hoch (Mehrere Verknüpfungen) | Mäßig (Weniger Verknüpfungen) |
| Schreibleistung | Schnell (Weniger Daten) | Variabel (Aktualisierungs-Triggern) |
| Lesegeschwindigkeit | Langsam (Datenträger-I/O) | Schneller (Gecachte Daten) |
| Datenintegrität | Hoch | Hoch (mit Validierung) |
Wann man die Regeln brechen sollte 🛑
Es gibt gültige Szenarien, in denen die strenge 3NF beiseite gelassen werden sollte. Das Verständnis dafür, wann man davon abweichen sollte, ist für Datenbankarchitekten entscheidend.
- Berichterstattung und Analytik:Datenlagern verwenden oft ein Sternschema anstelle der 3NF. Ziel hier ist die Lesegeschwindigkeit für Analysen, nicht die Transaktionsintegrität.
- Systeme mit hoher Durchsatztransaktion: Wenn das System Millionen von Schreibvorgängen pro Sekunde verarbeitet, könnten komplexe Verknüpfungen zu Sperrkonflikten führen. Die Vereinfachung des Schemas kann die Sperrbelastung reduzieren.
- Veraltete Systeme: Wenn von einem alten System migriert wird, könnte es schneller sein, vorübergehend zu denormalisieren, während die Anwendungsschicht neu aufgebaut wird.
- Anwendungen mit hohem Leseaufwand: Wenn Ihre Anwendung Daten 100-mal liest, für jeden Schreibvorgang, überwiegt die Kosten für die Aufrechterhaltung der 3NF-Konsistenz die Vorteile.
Implementierungs-Checkliste ✅
Bevor Sie Ihr Datenbankschema bereitstellen, durchlaufen Sie diese Checkliste, um sicherzustellen, dass Sie ein Gleichgewicht zwischen Leistung und Normalisierung erreicht haben.
- Analysieren Sie Abfragemuster: Identifizieren Sie die häufigsten Leseabfragen. Erfordern sie zu viele Verknüpfungen?
- Messen Sie die aktuelle Leistung:Stellen Sie Ihre Systembasis ein. Kennen Sie die aktuelle Latenz kritischer Abfragen.
- Überprüfen Sie die Indexnutzung:Überprüfen Sie, ob Indizes genutzt werden oder ob sie während Schreibvorgänge eine zusätzliche Belastung verursachen.
- Testen Sie die Schreiblast:Stellen Sie sicher, dass jede Denormalisierungsstrategie die Schreibvorgänge nicht zu sehr verlangsamt.
- Planen Sie die Datenabstimmung:Wenn Sie Daten duplizieren, wie halten Sie sie synchron? Definieren Sie die Mechanismen.
- Überwachen Sie Anomalien:Richten Sie Warnungen für Dateninkonsistenzen ein, wenn Sie eine teilweise Denormalisierung verwenden.
Abschließende Gedanken zur Datenbankarchitektur 🏗️
Die Erreichung der dritten Normalform ohne Leistungseinbußen erfordert einen differenzierten Ansatz. Es handelt sich nicht um eine binäre Wahl zwischen Geschwindigkeit und Integrität. Durch das Verständnis der Kosten von Joins, die effektive Nutzung von Indizes und die gezielte Denormalisierung an geeigneten Stellen können Sie Systeme bauen, die sowohl zuverlässig als auch schnell sind. Die beste Datenbankarchitektur ist die, die sich an die spezifische Arbeitslast der Anwendung anpasst. Überprüfen Sie regelmäßig Ihr ERD und die Abfrageleistung, während das System wächst. Anpassung ist der Schlüssel für langfristigen Erfolg im Datenmanagement.