











Trong các kiến trúc dữ liệu hiện đại, tốc độ truy xuất thông tin thường quyết định tính khả dụng của một ứng dụng. Mặc dù nâng cấp phần cứng và các chiến lược bộ nhớ đệm đóng vai trò quan trọng, nền tảng của hiệu suất nằm chính ở cấu trúc dữ liệu. Cụ thể, thiết kế của các Mô hình Quan hệ Thực thể (ERMs) quyết định cách hiệu quả mà một bộ động cơ cơ sở dữ liệu có thể duyệt, nối và tổng hợp dữ liệu. Một lược đồ được tối ưu không chỉ sắp xếp thông tin; nó dẫn dắt bộ tối ưu hóa truy vấn đến các đường đi thực thi nhanh hơn. 📉
Hướng dẫn này khám phá các cơ chế kỹ thuật đằng sau thiết kế lược đồ và mối liên hệ trực tiếp của nó với hiệu suất truy vấn. Chúng ta sẽ xem xét cách các mức độ chuẩn hóa, tính cardinality của mối quan hệ và các chiến lược chỉ mục tương tác trong kế hoạch thực thi truy vấn. Bằng cách hiểu rõ những động lực này, các nhà phát triển và kiến trúc sư cơ sở dữ liệu có thể xây dựng các hệ thống mở rộng được mà không làm tổn hại đến tính toàn vẹn hay tốc độ.
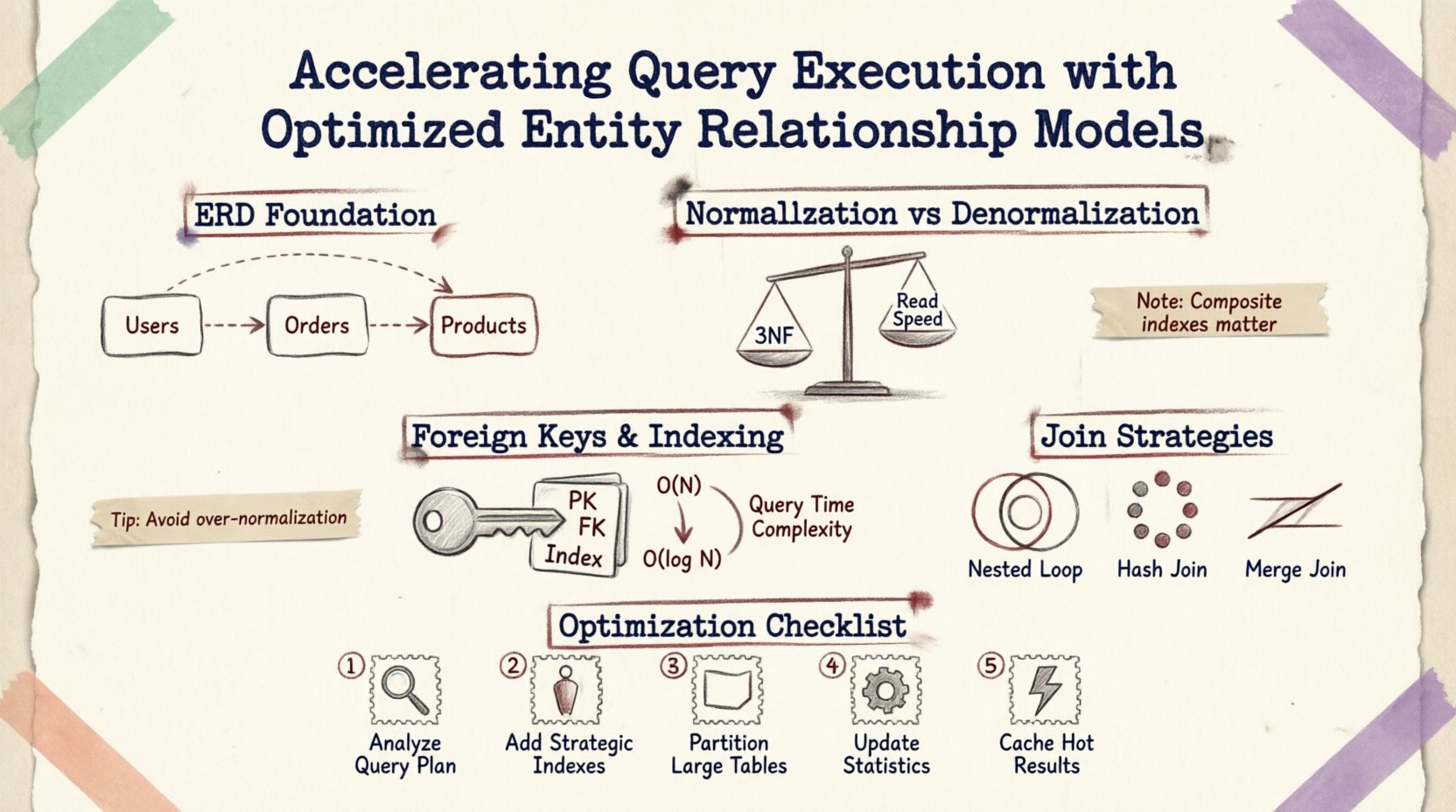
Hiểu rõ nền tảng: ERDs và hiệu suất 🗃️
Sơ đồ quan hệ thực thể không chỉ là công cụ hỗ trợ trực quan cho tài liệu; nó là bản vẽ thiết kế cho logic lưu trữ và truy xuất vật lý. Mỗi đường kẻ giữa các bảng đại diện cho một ràng buộc khóa ngoại, một thao tác nối hoặc một quy tắc toàn vẹn dữ liệu. Khi một truy vấn được gửi đi, bộ động cơ cơ sở dữ liệu sẽ giải mã các mối quan hệ này để xây dựng một kế hoạch thực thi.
Hãy xem xét một truy vấn đơn giản yêu cầu thông tin về đơn hàng của người dùng và chi tiết sản phẩm. Bộ động cơ phải:
- Tìm kiếm bảng
Người dùngbảng. - Theo khóa ngoại đến bảng
Đơn hàngbảng. - Nối với bảng
Chi tiết đơn hàngbảng. - Đi đến bảng
Sản phẩmbảng thông qua một mối quan hệ khác.
Mỗi bước đều bao gồm các thao tác I/O và chu kỳ CPU. Nếu các mối quan hệ được định nghĩa kém, bộ động cơ có thể phải sử dụng quét toàn bộ bảng hoặc các phép nối vòng lặp lồng nhau, làm giảm hiệu suất theo cấp số nhân. Tối ưu hóa ERD giúp giảm khoảng cách dữ liệu phải di chuyển từ ổ đĩa đến bộ nhớ.
Chuẩn hóa so với phi chuẩn hóa: Tìm kiếm sự cân bằng ⚖️
Chuẩn hóa là quá trình tổ chức dữ liệu nhằm giảm thiểu sự trùng lặp và cải thiện tính toàn vẹn. Mặc dù cần thiết để đảm bảo tính nhất quán, nhưng chuẩn hóa quá mức có thể làm phân mảnh dữ liệu trên nhiều bảng nhỏ, dẫn đến việc cần các phép nối phức tạp làm chậm các thao tác đọc dữ liệu.
Chi phí của việc chuẩn hóa sâu
Khi một lược đồ được chuẩn hóa đến dạng chuẩn hóa thứ ba (3NF), dữ liệu được lưu trữ ở trạng thái nguyên tử nhất. Điều này giúp tối thiểu hóa không gian lưu trữ và các bất thường khi cập nhật. Tuy nhiên, việc truy xuất dữ liệu liên quan thường đòi hỏi phải đi qua nhiều khóa ngoại.
- Chi phí nối: Mỗi bảng bổ sung trong chuỗi nối làm tăng độ phức tạp của kế hoạch truy vấn.
- Xung đột khóa: Truy cập nhiều bảng làm tăng khả năng xảy ra xung đột khóa ở cấp độ hàng.
- Sử dụng CPU: Bộ động cơ cơ sở dữ liệu phải hợp nhất các tập kết quả từ các bảng khác nhau.
Khi nào nên phi chuẩn hóa
Việc loại bỏ chuẩn hóa tạo ra sự trùng lặp để tối ưu hiệu suất đọc. Điều này thường là cần thiết trong các môi trường xử lý phân tích hoặc báo cáo có lưu lượng truy cập cao.
- Các tác vụ đọc nhiều: Nếu thao tác ghi ít xảy ra hơn so với thao tác đọc, việc thêm một cột không chuẩn hóa sẽ giúp tiết kiệm các thao tác nối.
- Các tổng hợp đã được tính toán trước: Lưu trữ tổng (ví dụ như
total_order_value) trong bảng người dùng giúp tránh việc tính tổng cho mỗi yêu cầu. - Chia theo chiều ngang: Giữ dữ liệu thường xuyên truy cập cùng nhau giúp cải thiện tính cục bộ của bộ đệm.
Tuy nhiên, việc loại bỏ chuẩn hóa đòi hỏi quản lý cẩn trọng để ngăn ngừa sự bất nhất dữ liệu. Logic ứng dụng phải đảm bảo rằng dữ liệu trùng lặp được cập nhật mỗi khi dữ liệu nguồn thay đổi.
Khóa ngoại và chiến lược lập chỉ mục 🔑
Các ràng buộc khóa ngoại đảm bảo tính toàn vẹn tham chiếu, nhưng chúng đi kèm với chi phí hiệu suất. Cơ sở dữ liệu phải xác minh rằng một giá trị trong một bảng tồn tại trong bảng khác trước khi cho phép chèn hoặc cập nhật. Tối ưu cách lập chỉ mục cho các khóa này là điều quan trọng.
Lập chỉ mục cho khóa ngoại
Mặc định, khóa chính được tự động lập chỉ mục. Tuy nhiên, khóa ngoại thường cần các chỉ mục rõ ràng để tăng tốc các thao tác nối. Không có chỉ mục trên cột khóa ngoại:
- Cơ sở dữ liệu phải thực hiện quét toàn bộ bảng con để tìm các hàng khớp.
- Các thao tác nối trở nên chậm đáng kể, đặc biệt khi kích thước bảng tăng lên hàng triệu hàng.
- Các kiểm tra toàn vẹn tham chiếu trong quá trình xóa trở nên tốn kém.
Một khóa ngoại được lập chỉ mục hợp lý cho phép cơ sở dữ liệu sử dụng thao tác tìm kiếm chỉ mục thay vì quét, giảm độ phức tạp từ O(N) xuống O(log N).
Chỉ mục kết hợp cho các mối quan hệ
Khi nhiều cột xác định một mối quan hệ, chỉ mục kết hợp có thể hiệu quả hơn so với các chỉ mục riêng lẻ. Ví dụ, nếu một truy vấn lọc theo user_id và created_at trong bảng đơn hàng, chỉ mục kết hợp trên cả hai cột đảm bảo động cơ có thể tìm thấy dữ liệu mà không cần quét các bản ghi không liên quan.
Chiến lược nối và kế hoạch thực thi 🔍
Cấu trúc của sơ đồ ERD ảnh hưởng đến thuật toán nối mà bộ tối ưu truy vấn chọn. Hiểu rõ các cơ chế này giúp thiết kế các lược đồ ưu tiên các loại nối hiệu quả.
| Loại nối | Sử dụng tốt nhất khi | Ảnh hưởng đến hiệu suất |
|---|---|---|
| Nối vòng lặp lồng ghép | Các tập kết quả nhỏ hoặc các điều kiện chọn lọc cao | Nhanh với dữ liệu nhỏ; chậm với các phép quét lớn |
| Ghép nối Băm | Các bảng lớn không có chỉ mục | Tốn bộ nhớ; tốt cho dữ liệu chưa được sắp xếp |
| Ghép nối Gộp | Dữ liệu đầu vào đã được sắp xếp theo khóa ghép nối | Rất nhanh nếu dữ liệu đã được sắp xếp |
Thiết kế ERD để hỗ trợ dữ liệu đầu vào đã sắp xếp hoặc tìm kiếm có chỉ mục có thể khuyến khích trình tối ưu chọn phương pháp ghép nối nhanh hơn. Ví dụ, đảm bảo rằng các khóa ghép nối được định nghĩa như một phần của chỉ mục có cấu trúc có thể hỗ trợ các phép ghép nối Gộp.
Những sai lầm phổ biến trong thiết kế lược đồ 🚫
Ngay cả các kiến trúc sư có kinh nghiệm cũng mắc sai lầm ảnh hưởng đến tốc độ truy vấn. Nhận diện những mẫu này sớm sẽ ngăn ngừa việc tái cấu trúc tốn kém về sau.
- Khóa ngoại nối chuỗi:Tạo chuỗi các mối quan hệ nơi Bảng A liên kết với B, B liên kết với C, và C liên kết với D. Các truy vấn kết hợp cả bốn bảng trở nên lồng ghép sâu và chậm.
- Chuỗi có độ dài biến đổi:Sử dụng
VARCHARcho các khóa luôn có độ dài cố định có thể làm lãng phí không gian và làm chậm so sánh hàng. - Nhiều-nhiều mà không có bảng liên kết:Cố gắng lưu trữ nhiều ID trong một cột duy nhất (ví dụ: các giá trị cách nhau bởi dấu phẩy) sẽ ngăn cản việc lập chỉ mục và chuẩn hóa đúng cách.
- Chuyển đổi ngầm định:Định nghĩa kiểu dữ liệu không khớp giữa bảng cha và bảng con buộc động cơ phải chuyển đổi giá trị tại thời điểm chạy, ngăn cản việc sử dụng chỉ mục.
Các bước thực tế để tối ưu hóa 🛠️
Để cải thiện thực thi truy vấn mà không cần viết lại toàn bộ hệ thống, hãy tuân theo các bước có cấu trúc sau:
- Phân tích mẫu truy vấn:Xem xét các thao tác đọc thường xuyên nhất. Xác định các bảng nào thường được kết hợp với nhau nhất.
- Xem xét việc sử dụng chỉ mục:Kiểm tra xem có chỉ mục nào bị thiếu trên các khóa ngoại hoặc các cột thường được lọc không.
- Tinh chỉnh tính cardinality:Đảm bảo các mối quan hệ được mô hình hóa chính xác (một-một so với một-nhiều). Cardinality sai có thể dẫn đến các phép ghép nối không cần thiết.
- Chia nhỏ các bảng lớn: Nếu một bảng vượt quá hàng triệu hàng, hãy cân nhắc phân vùng theo ngày hoặc khu vực để giới hạn lượng dữ liệu được quét cho mỗi truy vấn.
- Theo dõi khóa:Sử dụng các công cụ giám sát để xác định các truy vấn chạy lâu dài đang giữ khóa, thường do đi qua sơ đồ không hiệu quả.
Xem xét về lưu trữ và bộ nhớ 💾
Sắp xếp vật lý của dữ liệu cũng đóng vai trò quan trọng. Các động cơ cơ sở dữ liệu lưu trữ dữ liệu theo trang. Nếu các hàng liên quan được lưu trữ gần nhau về mặt vật lý, thì sẽ cần ít thao tác đọc đĩa hơn để tải một tập dữ liệu.
- Chuỗi hóa:Sắp xếp dữ liệu theo một khóa chung có thể cải thiện các truy vấn phạm vi.
- Lưu trữ cột so với lưu trữ hàng:Đối với các truy vấn phân tích, lưu trữ theo cột có thể mang lại nén tốt hơn và tổng hợp nhanh hơn so với các mô hình truyền thống dựa trên hàng.
- Bộ nhớ đệm:Thiết kế các sơ đồ cho phép bộ nhớ đệm hiệu quả cho toàn bộ tập kết quả thay vì từng hàng riêng lẻ.
Suy nghĩ cuối cùng về sự phát triển sơ đồ 🔄
Thiết kế sơ đồ không phải là một công việc một lần. Khi yêu cầu ứng dụng thay đổi, mô hình dữ liệu phải phát triển theo. Thường xuyên kiểm tra cấu trúc cơ sở dữ liệu đảm bảo hiệu suất vẫn ổn định. Tài liệu về Mô hình quan hệ thực thể cần được duy trì song song với mã nguồn để theo dõi cách các thay đổi ảnh hưởng đến hệ thống.
Bằng cách tập trung vào tính toàn vẹn cấu trúc và các mối quan hệ logic bên trong dữ liệu, bạn tạo ra nền tảng hỗ trợ thực thi truy vấn tốc độ cao. Mục tiêu không phải là xây dựng một hệ thống tĩnh, mà là một kiến trúc linh hoạt có thể thích nghi với tải mà không hy sinh tốc độ mà người dùng mong đợi. 📊
Tối ưu hóa Mô hình quan hệ thực thể là một lĩnh vực kỹ thuật kết hợp lý thuyết cơ sở dữ liệu với kỹ thuật thực tiễn. Nó đòi hỏi sự kiên nhẫn, phân tích và hiểu rõ cách động cơ nền tảng xử lý các yêu cầu. Với cách tiếp cận đúng đắn, các vấn đề hiệu suất trở nên kiểm soát được, và việc truy xuất dữ liệu trở nên trơn tru.