Designing robust data structures requires a balance between theoretical purity and practical performance. When working with complex Entity Relationship Models (ERDs), adhering strictly to normalization rules often creates friction in high-velocity environments. This article explores strategic denormalization tactics designed to enhance query efficiency while maintaining data integrity. We will examine when to deviate from standard forms and how to implement redundancy safely.
Database architects frequently face a choice between optimizing for write operations or read operations. Normalization reduces redundancy, ensuring data consistency. However, it can increase the number of joins required for retrieval, impacting latency. Denormalization reintroduces redundancy to simplify access patterns. This approach is not about abandoning best practices but applying them where the business logic demands it.
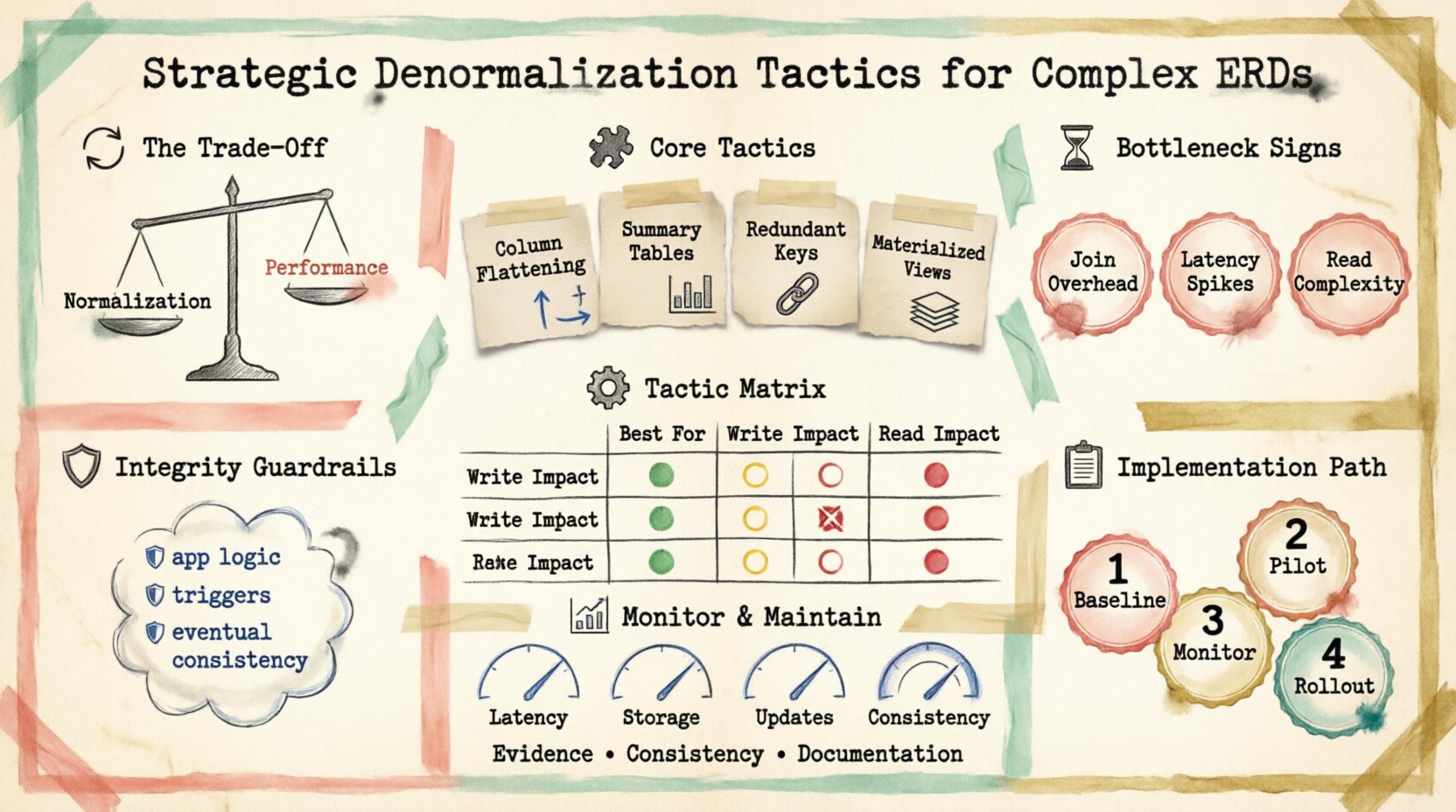
The Cost of Strict Normalization 🔄
In a normalized state, data is organized into distinct tables to minimize duplication. This structure is ideal for storage efficiency and write consistency. However, as the number of relationships grows, the complexity of retrieving a single record increases.
- Join Overhead: Each join operation consumes CPU and memory resources. Complex queries across five or more tables can become bottlenecks.
- Latency: Network round-trips increase with the number of tables involved. In distributed systems, this latency is amplified.
- Read Complexity: Application logic becomes more convoluted as it must orchestrate multiple data retrieval steps.
For reporting dashboards, real-time analytics, or user-facing interfaces where read speed is critical, the cost of normalization may outweigh its benefits. Understanding this trade-off is the first step in strategic optimization.
Identifying Performance Bottlenecks ⏱️
Before altering the schema, you must identify specific pain points. Not every slow query requires denormalization. Use profiling tools to analyze execution plans.
- High I/O Wait: Indicates excessive disk reading, often caused by scanning large tables.
- Lock Contention: Frequent locks during reads can suggest overly fragmented data structures.
- Slow Aggregate Queries: Calculations across multiple tables often suffer from normalization overhead.
When these metrics appear consistently, it signals an opportunity to restructure data. The goal is to reduce the computational load on the engine without compromising the source of truth.
Core Tactical Approaches 🧩
There are several methods to introduce redundancy strategically. The choice depends on the read-to-write ratio of your specific workload.
1. Column Flattening
This involves moving data from related tables directly into the primary table. For example, storing a user’s email address within an order table, rather than joining the user table every time an order is retrieved.
- Benefit: Eliminates the join requirement for user details.
- Constraint: Data must be updated whenever the user profile changes.
2. Summary Tables
Pre-calculated aggregates can sit alongside detailed transactional data. This is common in financial reporting or inventory management.
- Benefit: Instant access to totals, averages, and counts.
- Constraint: Requires a mechanism to keep aggregates in sync with raw data.
3. Redundant Foreign Keys
Often, a parent key is needed in a child table for quick lookups. Adding a redundant foreign key allows direct referencing without traversing the hierarchy.
- Benefit: Faster traversal in deep hierarchies.
- Constraint: Increases storage slightly and requires consistency checks.
Tactic Comparison Matrix
| Tactic | Best For | Write Impact | Read Impact |
|---|---|---|---|
| Column Flattening | Lookup-heavy queries | Medium | Low |
| Summary Tables | Reporting & Analytics | High | Very Low |
| Redundant Keys | Deep Hierarchies | Low | Low |
| Materialized Views | Complex Joins | Medium | Low |
Managing Data Integrity 🛡️
Introducing redundancy creates a risk of data divergence. If the source data changes and the redundant copy does not, the system becomes unreliable. This is the primary challenge of denormalization.
- Application-Level Logic: Ensure code updates all copies of the data within a single transaction.
- Triggers: Database triggers can automate updates to redundant fields when source tables change.
- Eventual Consistency: In some systems, slight delays between updates are acceptable. This reduces load but requires the application to handle stale data gracefully.
Validation rules are essential. Periodic audits should compare source data against redundant copies to detect drift. If a discrepancy is found, a reconciliation script should run to restore consistency.
Implementation Strategy 📋
Do not refactor the entire database at once. Adopt a phased approach to minimize risk.
- Baseline Measurement: Record current query times and resource usage.
- Pilot Denormalization: Select one high-impact query and optimize it.
- Monitoring: Track performance improvements and data consistency errors.
- Rollout: Expand the pattern to other high-volume areas.
Documentation is critical. Clearly label which tables are denormalized and why. Future developers need to understand the trade-offs made in the schema design.
Monitoring Performance Metrics 📊
Once denormalization is active, continuous monitoring ensures the strategy remains effective.
- Query Latency: Watch for increases that might indicate lock contention on updated tables.
- Storage Growth: Redundant data consumes more space. Plan capacity accordingly.
- Update Frequency: High write volumes on denormalized tables can degrade performance.
- Consistency Errors: Log any failures in the synchronization process.
Alerts should be configured for anomalies. If a specific table grows faster than expected, it may indicate a logic error in how data is being replicated.
Maintenance Protocols 🔧
Maintaining a denormalized schema requires discipline. It is not a set-and-forget configuration.
- Schema Versioning: Treat schema changes like code. Review migration scripts regularly.
- Cleanup Routines: Remove redundant data that is no longer needed to save space.
- Review Cadence: Re-evaluate the need for denormalization as business requirements shift.
Sometimes, the initial optimization is no longer necessary if the data volume drops or the access patterns change. Regular reviews prevent technical debt from accumulating.
Strategic Review Cadence 🔄
Database design is not static. What works today may not work tomorrow. Schedule quarterly reviews of the Entity Relationship Model.
- Workload Analysis: Has the ratio of reads to writes changed?
- Hardware Updates: New storage technology might change the cost of joins.
- Business Goals: New features might require different data structures.
Flexibility is key. Be prepared to re-normalize if the cost of maintaining redundancy exceeds the performance gains. The objective is always optimal system behavior, not adherence to a specific design dogma.
Final Thoughts on Schema Evolution 📝
Denormalization is a powerful tool in the database architect’s toolkit. It addresses real-world performance issues that theoretical models sometimes overlook. By applying these tactics methodically, you can build systems that are both fast and reliable.
- Focus on Evidence: Base decisions on metrics, not assumptions.
- Prioritize Consistency: Ensure data remains accurate across all layers.
- Document Decisions: Keep a record of why specific tables were modified.
With careful planning and ongoing maintenance, complex Entity Relationship Models can deliver the performance required by modern applications. The path to efficiency is iterative, requiring constant attention to the balance between structure and speed.