Designing a robust database structure requires precision and foresight. The Entity-Relationship Diagram (ERD) serves as the foundational blueprint for this architecture. Without a clear map, data redundancy and query bottlenecks emerge quickly, leading to performance degradation over time. This guide explores how to derive optimization techniques directly from these visual models. We focus on structural integrity and performance tuning without relying on specific platform features or proprietary tools. By understanding the underlying relationships, you can build systems that scale efficiently.
📐 Understanding ERD Fundamentals
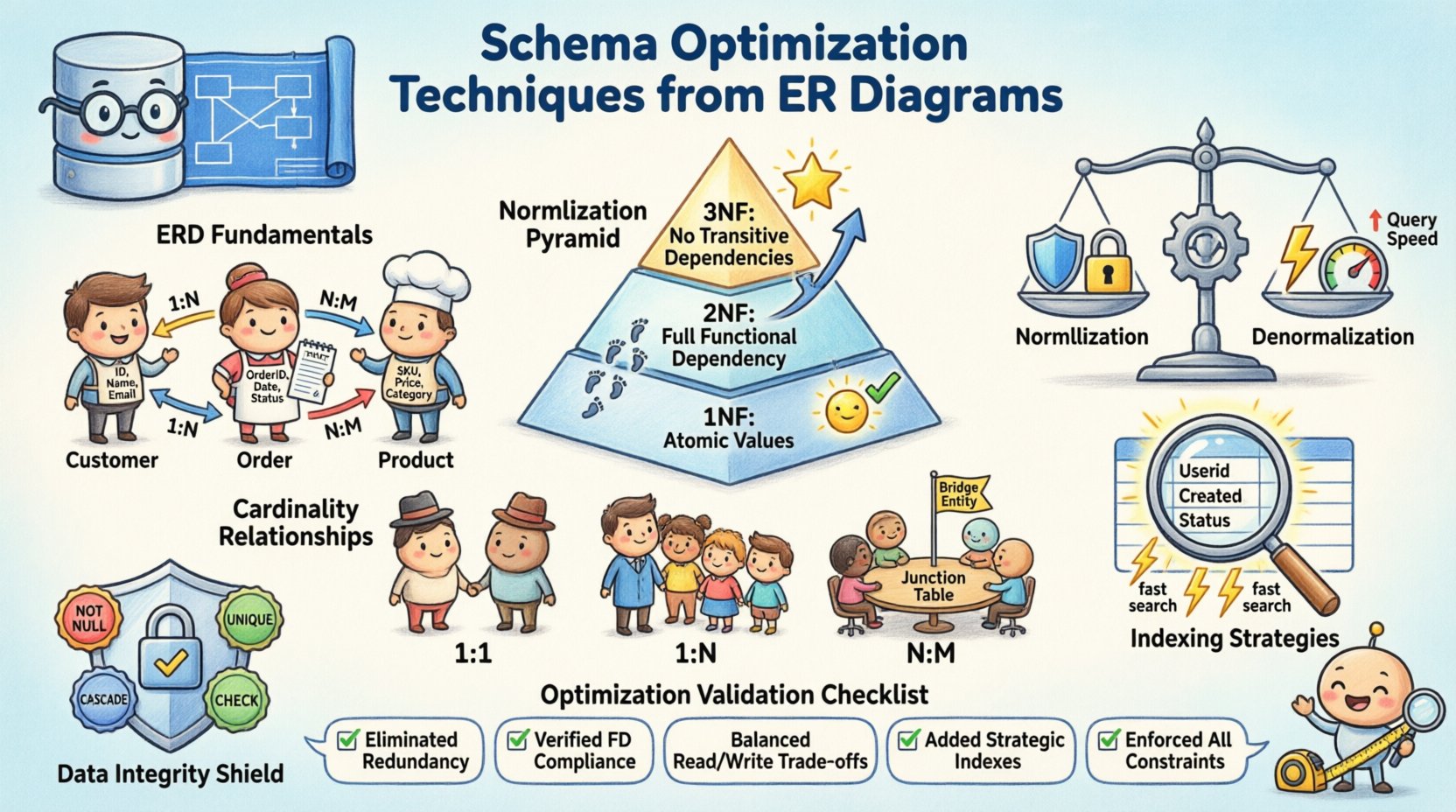
Before optimization begins, the core components must be clear. An ER diagram translates business requirements into a logical data model. It defines how information is stored and accessed. A strong foundation prevents structural debt later in the development lifecycle. Consider the following elements:
- Entities: Represent objects or concepts, such as customers, orders, or products. Each entity becomes a table in the physical schema.
- Attributes: Define properties of entities, like name, ID, or timestamp. These become columns within the tables.
- Relationships: Show how entities interact. These dictate the use of foreign keys and constraints.
Visualizing these components allows you to identify potential issues before writing a single line of code. It ensures that the logical flow matches the physical storage requirements. This alignment is critical for maintaining data consistency across complex applications.
🔨 Normalization Strategies for Data Integrity
Normalization is the process of organizing data to reduce redundancy and improve integrity. It involves dividing large tables into smaller, logical units. While excessive normalization can slow down reads, skipping it entirely creates update anomalies. The goal is to find the balance that suits your specific workload.
First Normal Form (1NF)
The first rule requires that each column contains atomic values. No repeating groups or arrays are allowed within a single cell. This ensures that every piece of data is distinct and queryable. For example, a list of phone numbers should be split into separate rows or a related table, not stored as a comma-separated string.
Second Normal Form (2NF)
Once 1NF is met, 2NF addresses partial dependencies. All non-key attributes must depend on the entire primary key. In composite keys, this prevents data duplication where only part of the key determines an attribute. This step refines the structure to ensure every piece of information is tied correctly to its parent.
Third Normal Form (3NF)
The third form eliminates transitive dependencies. Non-key attributes should not depend on other non-key attributes. This means if Attribute A depends on Attribute B, and B depends on the Key, A should not exist in the same table. Moving such data to a separate table improves maintainability and reduces storage waste.
The table below summarizes the progression of normalization:
| Normal Form | Primary Goal | Key Constraint |
|---|---|---|
| 1NF | Atomic Values | No repeating groups |
| 2NF | Full Dependency | Remove partial dependencies |
| 3NF | Independence | Remove transitive dependencies |
⚡ Denormalization for Performance
While normalization ensures integrity, it often requires complex joins during queries. In read-heavy systems, the overhead of joining multiple tables can become a bottleneck. Denormalization intentionally introduces redundancy to improve retrieval speed. This is a trade-off between storage efficiency and query performance.
Consider the following scenarios where denormalization is appropriate:
- Reporting Dashboards: Aggregated data can be pre-calculated and stored to avoid real-time computation.
- Caching Layers: Frequently accessed data can be duplicated in a read-optimized store.
- High-Throughput Transactions: Reducing join depth minimizes lock contention and CPU usage.
When implementing this, establish a clear process for updating the redundant data. Inconsistencies arise if the source of truth changes without updating the copies. Automated triggers or application logic must handle synchronization to maintain accuracy.
🔗 Managing Cardinality and Relationships
Cardinality defines the numerical relationship between entities. It dictates how foreign keys are implemented and how data is linked. Understanding these patterns is essential for preventing orphaned records and ensuring referential integrity.
- One-to-One: Rare in general systems, often used for security or extension tables. A single row in Table A links to exactly one row in Table B.
- One-to-Many: The most common relationship. One parent record relates to multiple child records. The foreign key resides in the child table.
- Many-to-Many: Requires a junction table to resolve the relationship. This intermediate table links the primary keys of both entities.
Incorrect cardinality assumptions lead to inefficient storage or invalid data states. For instance, treating a many-to-many relationship as a simple column will prevent multiple associations. Properly modeling these links ensures the database can enforce the business rules defined in the diagram.
📉 Indexing Strategies Based on Structural Analysis
Indexes are the mechanism that allows the database engine to find data quickly. The structure of the ERD directly informs which columns should be indexed.盲目 adding indexes consumes disk space and slows down write operations.
Key indexing considerations include:
- Primary Keys: Always indexed by default. They define the unique identity of each row.
- Foreign Keys: Often require indexing to speed up join operations and constraint checks.
- Composite Keys: Used when queries filter by multiple columns. The order of columns in the index matters for performance.
- Selective Columns: Index columns with high cardinality. Low selectivity (e.g., gender) rarely benefits from an index.
Analyze your query patterns against the schema design. If a specific join is executed frequently, ensure the foreign key column is indexed. This reduces the time the database spends scanning entire tables.
🛡️ Data Integrity and Referential Constraints
Integrity constraints protect the accuracy and consistency of the data. They act as a guardrail against invalid inputs or accidental deletions. While some constraints are enforced by the application, database-level constraints are more reliable.
Common constraint types include:
- NOT NULL: Ensures a column always contains a value. Prevents gaps in critical data fields.
- UNIQUE: Ensures no two rows share the same value in a specific column. Useful for emails or usernames.
- CASCADE: Defines what happens to child records when a parent is deleted. Options include restrict, cascade, or set null.
- CHECK: Enforces specific conditions on data values, such as date ranges or numeric limits.
Implementing these rules at the database level prevents the application from having to validate every single data point. It centralizes the logic for data validity, reducing code duplication and potential errors.
🔄 Iterative Refinement and Schema Evolution
Schema design is not a one-time task. Business requirements change, and the data model must evolve. Regular reviews of the ERD and the physical schema help identify areas for improvement. Monitoring query performance provides insights into where the structure is struggling.
During refinement, consider the following steps:
- Review Index Usage: Remove unused indexes to reduce write overhead.
- Check Partitioning: Large tables may benefit from splitting data based on ranges or keys.
- Update Cardinality: As business logic shifts, relationships may change from one-to-many to many-to-many.
- Version Control: Treat schema changes as code. Track modifications to allow for rollback if needed.
This iterative approach ensures the database remains aligned with the application’s needs over time. It prevents the accumulation of technical debt that slows down future development.
✅ Optimization Checklist
Use this list to validate your schema design before deployment:
- Verify all tables meet at least Third Normal Form (3NF).
- Ensure foreign keys are indexed where joins are frequent.
- Check for circular dependencies in relationships.
- Confirm that primary keys are defined for every table.
- Review constraints to ensure data consistency rules are enforced.
- Analyze query patterns to identify potential denormalization opportunities.
- Document all assumptions regarding data cardinality and volume.
Following these steps creates a resilient foundation for data storage. It allows the system to handle growth without requiring a complete rebuild. A well-optimized schema is the difference between a sluggish application and a responsive one.