











Проектирование надежной структуры базы данных требует точности и дальновидности. Диаграмма сущность-связь (ERD) служит основополагающим чертежом для этой архитектуры. Без четкого плана избыточность данных и узкие места при выполнении запросов быстро возникают, что приводит к постепенному снижению производительности. В этом руководстве рассматривается, как напрямую извлекать методы оптимизации из этих визуальных моделей. Мы сосредоточены на целостности структуры и настройке производительности без использования специфических возможностей платформы или проприетарных инструментов. Понимая лежащие в основе отношения, вы сможете создавать системы, которые эффективно масштабируются.
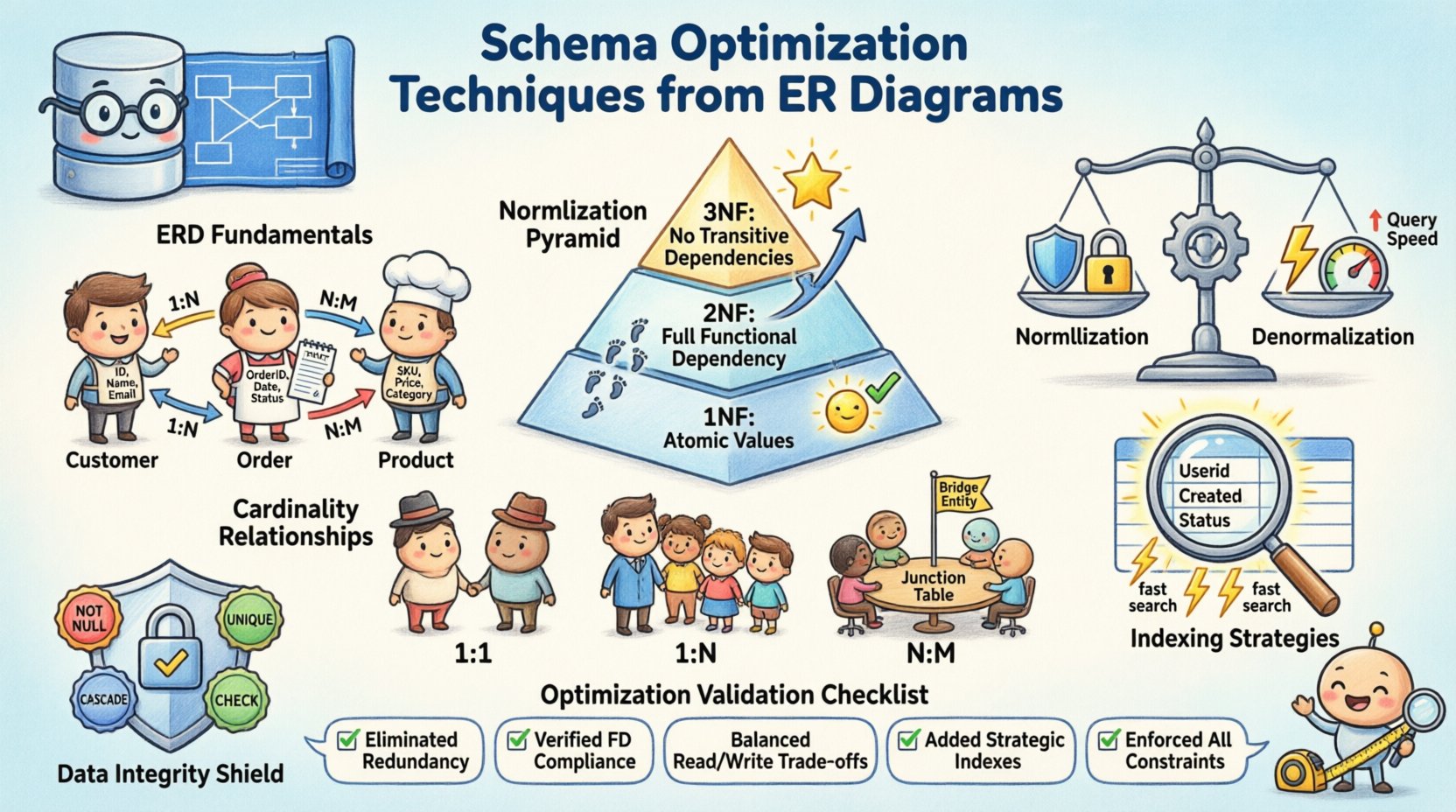
📐 Понимание основ диаграмм сущность-связь
Прежде чем начать оптимизацию, основные компоненты должны быть четко определены. Диаграмма сущность-связь переводит бизнес-требования в логическую модель данных. Она определяет, как информация хранится и доступна. Надежная основа предотвращает накопление структурного долга на более поздних этапах жизненного цикла разработки. Обратите внимание на следующие элементы:
- Сущности: Представляют объекты или понятия, такие как клиенты, заказы или товары. Каждая сущность становится таблицей в физической схеме.
- Атрибуты: Определяют свойства сущностей, такие как имя, идентификатор или метка времени. Они становятся столбцами внутри таблиц.
- Связи: Показывают, как сущности взаимодействуют между собой. Они определяют использование внешних ключей и ограничений.
Визуализация этих компонентов позволяет выявить потенциальные проблемы до написания первой строки кода. Это гарантирует, что логическая последовательность соответствует требованиям физического хранения данных. Такая согласованность критически важна для поддержания целостности данных в сложных приложениях.
🔨 Стратегии нормализации для обеспечения целостности данных
Нормализация — это процесс организации данных с целью уменьшения избыточности и повышения целостности. Она включает разделение больших таблиц на более мелкие логические единицы. Хотя чрезмерная нормализация может замедлить операции чтения, полное её пропуск приводит к аномалиям обновления. Цель — найти баланс, подходящий для вашей конкретной рабочей нагрузки.
Первое нормальное состояние (1НФ)
Первое правило требует, чтобы каждый столбец содержал атомарные значения. Внутри одной ячейки не допускаются повторяющиеся группы или массивы. Это гарантирует, что каждая часть данных является уникальной и доступной для запросов. Например, список номеров телефонов должен быть разделён на отдельные строки или в отдельную связанную таблицу, а не храниться в виде строки, разделённой запятыми.
Второе нормальное состояние (2НФ)
После выполнения 1НФ 2НФ решает проблему частичных зависимостей. Все атрибуты, не являющиеся ключевыми, должны зависеть от всего первичного ключа. При составных ключах это предотвращает дублирование данных, когда только часть ключа определяет атрибут. Этот шаг уточняет структуру, чтобы каждая часть информации правильно связывалась со своим родителем.
Третье нормальное состояние (3НФ)
Третье нормальное состояние устраняет транзитивные зависимости. Атрибуты, не являющиеся ключевыми, не должны зависеть от других атрибутов, не являющихся ключевыми. Это означает, что если атрибут А зависит от атрибута В, а В зависит от ключа, то А не должен находиться в той же таблице. Перемещение такой информации в отдельную таблицу улучшает поддерживаемость и уменьшает потери хранилища.
В таблице ниже приведено резюме прогресса нормализации:
| Нормальная форма | Основная цель | Ключевое ограничение |
|---|---|---|
| 1НФ | Атомарные значения | Нет повторяющихся групп |
| 2НФ | Полная зависимость | Устранить частичные зависимости |
| 3НФ | Независимость | Удалить транзитивные зависимости |
⚡ Денормализация для производительности
Хотя нормализация обеспечивает целостность, она часто требует сложных соединений при выполнении запросов. В системах с высокой нагрузкой на чтение накладные расходы от соединения нескольких таблиц могут стать узким местом. Денормализация сознательно вводит избыточность для ускорения извлечения данных. Это компромисс между эффективностью использования хранилища и производительностью запросов.
Рассмотрим следующие сценарии, в которых денормализация является подходящей:
- Панели отчетов:Агрегированные данные могут быть заранее рассчитаны и сохранены, чтобы избежать вычислений в реальном времени.
- Уровни кэширования:Часто используемые данные могут быть скопированы в хранилище, оптимизированное для чтения.
- Транзакции с высокой пропускной способностью:Снижение глубины соединения минимизирует конкуренцию за блокировки и использование ЦП.
При реализации этого необходимо установить четкий процесс обновления избыточных данных. Несогласованность возникает, если источник истины изменяется без обновления копий. Автоматические триггеры или логика приложения должны обеспечивать синхронизацию для поддержания точности.
🔗 Управление кардинальностью и отношениями
Кардинальность определяет числовое отношение между сущностями. Она определяет, как реализуются внешние ключи и как связаны данные. Понимание этих паттернов необходимо для предотвращения появления «сиротских» записей и обеспечения целостности ссылок.
- Один к одному:Редко встречается в общих системах, часто используется для таблиц безопасности или расширения. Одна строка в таблице A связана ровно с одной строкой в таблице B.
- Один ко многим: Самое распространённое отношение. Один родительский элемент связан с несколькими дочерними элементами. Внешний ключ находится в дочерней таблице.
- Многие ко многим:Требует промежуточной таблицы для разрешения отношения. Эта промежуточная таблица связывает первичные ключи обеих сущностей.
Неправильные предположения о кардинальности приводят к неэффективному использованию хранилища или некорректному состоянию данных. Например, если рассматривать отношение «многие ко многим» как простое поле, это не позволит создавать несколько связей. Правильное моделирование этих связей обеспечивает, что база данных сможет соблюдать бизнес-правила, определённые на диаграмме.
📉 Стратегии индексации на основе структурного анализа
Индексы — это механизм, который позволяет базе данных быстро находить данные. Структура ERD напрямую определяет, какие столбцы должны быть проиндексированы. Слепое добавление индексов потребляет место на диске и замедляет операции записи.
Ключевые моменты при индексации включают:
- Первичные ключи:По умолчанию всегда индексируются. Они определяют уникальную идентичность каждой строки.
- Внешние ключи:Часто требуют индексации для ускорения операций соединения и проверки ограничений.
- Составные ключи:Используются, когда запросы фильтруют по нескольким столбцам. Порядок столбцов в индексе имеет значение для производительности.
- Выборочные столбцы:Индексируйте столбцы с высокой кардинальностью. Низкая выборочность (например, пол) редко приносит пользу от индекса.
Проанализируйте свои шаблоны запросов по отношению к проектированию схемы. Если определённое соединение выполняется часто, убедитесь, что столбец внешнего ключа проиндексирован. Это сокращает время, которое база данных тратит на сканирование целых таблиц.
🛡️ Целостность данных и ссылочные ограничения
Ограничения целостности защищают точность и согласованность данных. Они служат барьером против недопустимых вводов или случайного удаления. Хотя некоторые ограничения реализуются приложением, ограничения на уровне базы данных более надёжны.
Распространённые типы ограничений включают:
- NOT NULL:Гарантирует, что столбец всегда содержит значение. Предотвращает пробелы в критически важных полях данных.
- UNIQUE:Гарантирует, что ни две строки не имеют одинакового значения в определённом столбце. Полезно для электронной почты или имён пользователей.
- CASCADE: Определяет, что происходит с дочерними записями при удалении родительской. Варианты включают ограничение, каскадное удаление или установку значения NULL.
- CHECK: Принуждает соблюдение определённых условий для значений данных, таких как диапазоны дат или числовые пределы.
Реализация этих правил на уровне базы данных предотвращает необходимость валидации каждого отдельного элемента данных приложением. Это централизует логику проверки корректности данных, сокращая дублирование кода и потенциальные ошибки.
🔄 Итеративная доработка и эволюция схемы
Проектирование схемы — это не разовое задание. Требования бизнеса меняются, и модель данных должна эволюционировать. Регулярный анализ диаграммы ERD и физической схемы помогает выявить области для улучшения. Мониторинг производительности запросов даёт понимание, где структура испытывает трудности.
Во время доработки рассмотрите следующие шаги:
- Проверьте использование индексов: Удалите неиспользуемые индексы, чтобы снизить накладные расходы при записи.
- Проверьте партиционирование: Большие таблицы могут выиграть от разделения данных по диапазонам или ключам.
- Обновите кардинальность: По мере изменения бизнес-логики отношения могут измениться с одного к многим на многие к многим.
- Контроль версий: Рассматривайте изменения схемы как код. Отслеживайте изменения, чтобы иметь возможность отката при необходимости.
Этот итеративный подход обеспечивает, что база данных остаётся согласованной с потребностями приложения с течением времени. Он предотвращает накопление технического долга, который замедляет будущую разработку.
✅ Чек-лист оптимизации
Используйте этот список для проверки вашей схемы перед развертыванием:
- Убедитесь, что все таблицы соответствуют по крайней мере Третьей нормальной форме (3NF).
- Убедитесь, что внешние ключи индексируются там, где часто выполняются соединения.
- Проверьте наличие циклических зависимостей в отношениях.
- Убедитесь, что первичные ключи определены для каждой таблицы.
- Проверьте ограничения, чтобы убедиться, что правила согласованности данных соблюдаются.
- Проанализируйте шаблоны запросов, чтобы выявить потенциальные возможности денормализации.
- Документируйте все предположения, касающиеся кардинальности и объема данных.
Следуя этим шагам, создается устойчивая основа для хранения данных. Это позволяет системе справляться с ростом без необходимости полной перестройки. Хорошо оптимизированная схема — это разница между медленным приложением и отзывчивым.