











Реляционные базы данных построены на основе таблиц и строк, структура, предназначенная для плоских данных. Однако реальный мир редко соответствует такой простоте. Организации, файловые системы, ветки комментариев и деревья категорий все существуют в иерархических структурах. Представление этих родительских и дочерних связей на стандартной диаграмме сущность-связь (ERD) требует специфических паттернов проектирования, которые сохраняют целостность данных, позволяя при этом эффективно извлекать информацию.
Когда вы пытаетесь отобразить дерево в плоской схеме, вы сталкиваетесь с классическим противоречием между нормализацией и производительностью. В этом руководстве рассматриваются основные методы моделирования иерархических данных, оцениваются компромиссы каждого подхода, чтобы помочь вам разрабатывать надежные системы.
🧩 Проблема плоских схем
Диаграмма сущность-связь обычно визуализирует сущности в виде прямоугольников, а связи — в виде линий. В стандартной связи одна таблица связывается с другой с помощью внешнего ключа. Это идеально работает для сценариев «многие ко многим» или «один ко многим», где направление фиксировано. Но что происходит, когда категория может иметь подкатегории, которые, в свою очередь, могут иметь подподкатегории, потенциально бесконечно?
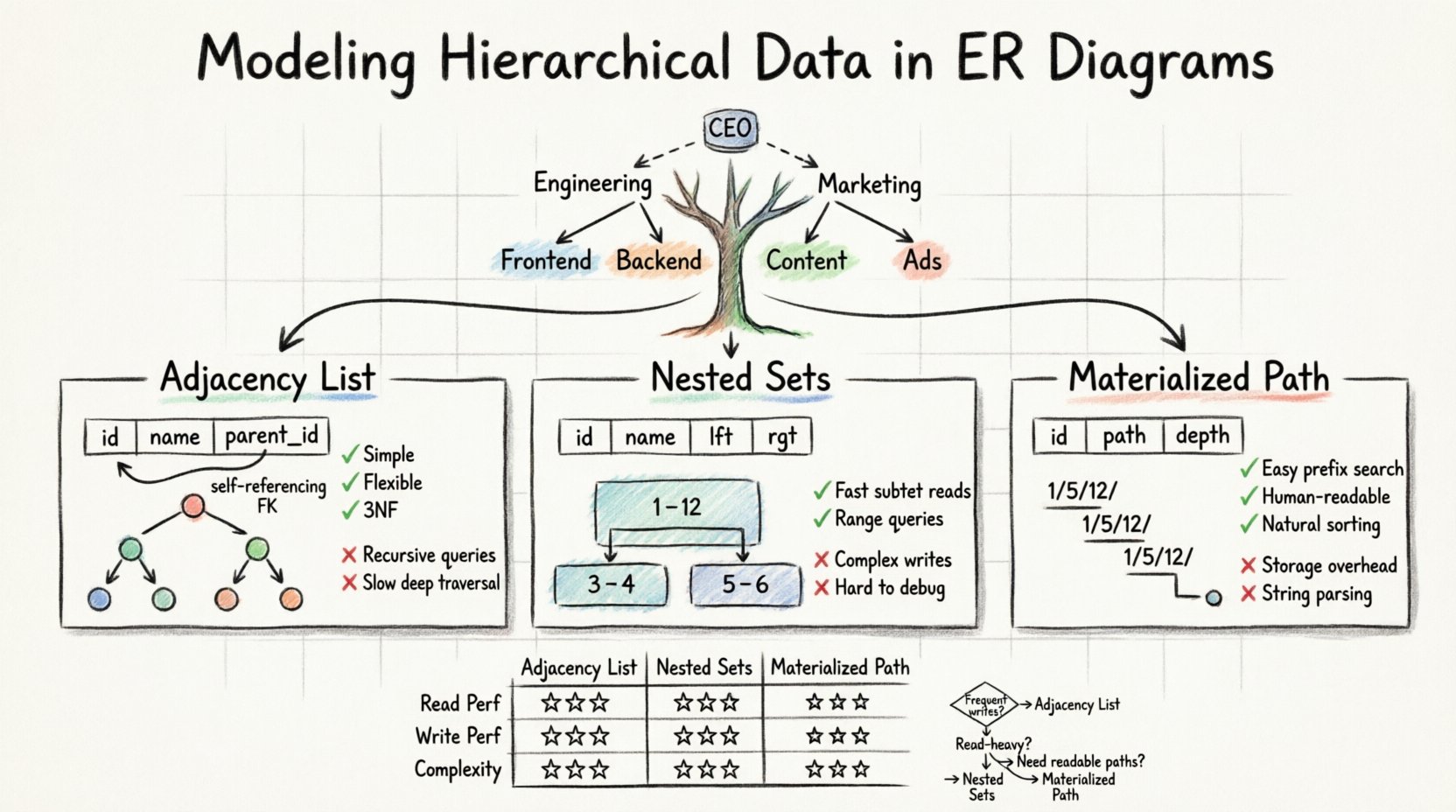
Стандартные реляционные модели испытывают трудности с переменной глубиной. Плоская таблица не может легко хранить путь произвольной длины. Чтобы решить эту проблему, необходимо адаптировать схему для явного хранения иерархии. Существует три основных паттерна, используемых архитекторами данных для достижения этой цели:
- Список смежности: Хранение идентификатора родителя в записи дочернего элемента.
- Вложенные множества: Назначение значений левого и правого, чтобы определить диапазоны.
- Перечисление пути: Хранение полного пути от корня до текущего узла.
🔗 Модель списка смежности
Список смежности — самый распространенный и простой способ представления иерархии на стандартной диаграмме сущность-связь. Он основан на самосвязи. Это означает, что одна таблица содержит столбец, ссылающийся на собственный первичный ключ.
📐 Структура схемы
В этой модели вы создаете одну таблицу для хранения данных. Каждая строка представляет узел дерева. Ключевое дополнение — столбец, обычно называемый parent_id или ancestor_id, который хранит уникальный идентификатор родительского узла. Если узел находится на вершине иерархии, этот столбец содержит значение null.
Рассмотрим таблицу для Отдела:
- id: Уникальный первичный ключ отдела.
- name: Отображаемое имя отдела.
- parent_id: Идентификатор вышестоящего отдела (может быть пустым для верхнего уровня).
✅ Преимущества
- Простота: Схема интуитивно понятна и легко понимается разработчиками и администраторами баз данных.
- Гибкость: Перемещение поддерева простое; вам нужно только обновить
parent_idкорневого узла этого поддерева. - Нормализация: Он хорошо соответствует третьей нормальной форме (3NF), так как данные не повторяются.
❌ Недостатки
- Сложность запросов: Получение всех потомков требует рекурсивных запросов или обработки на стороне приложения.
- Производительность: Глубокие обходы могут быть медленными без специальных стратегий индексации или рекурсивных общих табличных выражений (CTE).
- Целостность ссылок: Хотя внешние ключи помогают, циклические ссылки всё ещё могут возникать, если ограничения не строго соблюдаются.
🌲 Модель вложенных множеств
Модель вложенных множеств преобразует структуру дерева в набор интервалов. Вместо отслеживания указателей на родительский узел, каждому узлу присваиваются два числа:left и right. Эти значения представляют позицию узла при обходе дерева в прямом порядке.
📐 Структура схемы
Представьте дерево, где корневой узел — это всё множество. По мере обхода дерева вы увеличиваете счётчик. Когда вы заходите в узел, вы записываете текущее значение счётчика какleft. Когда вы завершаете обработку этого узла и всех его потомков, вы записываете значение счётчика какright. Значениеright значение всегда больше, чем левый значение.
А Категория таблица будет выглядеть следующим образом:
- id: Уникальный идентификатор.
- имя: Название категории.
- lft: Значение левой границы.
- rgt: Значение правой границы.
✅ Преимущества
- Быстрый доступ: Получение поддерева — это простой запрос диапазона с использованием
BETWEENлогики. - Эффективность: Производительность чтения превосходит производительность для больших, глубоких деревьев по сравнению со списками смежности.
❌ Недостатки
- Стоимость записи: Вставка или перемещение узла является дорогостоящим. Вам необходимо обновить значения
lftиrgtзначений многих других узлов для поддержания целостности интервалов. - Сложность: Логика сложна для реализации и отладки без поддержки специализированной библиотеки.
🛣️ Перечисление путей и материализованные пути
Методы перечисления путей хранят родословную узла в виде строки или разделенного списка. Этот подход часто называют шаблоном материализованного пути. Он сочетает простоту списка смежности с читаемостью пути.
📐 Структура схемы
В этой модели каждый запись хранит полный путь от корня. Например, в модели файловой системы файл может иметь строку пути, например/home/user/documents/report.txt. В базе данных это часто хранится в виде разделённой строки в столбце, например1/5/12/.
Таблица включает:
- id: Первичный ключ.
- path: Строка, представляющая родословную.
- depth: Целое число, указывающее, насколько глубоко находится узел.
✅ Преимущества
- Лёгкий обход: Вы можете найти всех потомков, сопоставляя префикс пути.
- Читаемость: Данные легко читаются человеком и легко отлаживаются.
- Сортировка: Сортировка по строке пути часто даёт правильный порядок дерева естественным образом.
❌ Недостатки
- Накладные расходы на хранение: Длинные пути могут потреблять значительное место на хранение.
- Обработка строк: Запросы часто требуют функций обработки строк, которые могут быть медленнее, чем сравнение целых чисел.
📊 Сравнительный анализ
Выбор правильной модели во многом зависит от соотношения чтения к записи и глубины вашей иерархии. В следующей таблице описаны характеристики каждого метода.
| Функция | Список смежности | Вложенные множества | Материализованный путь |
|---|---|---|---|
| Производительность чтения | Низкая до средней | Высокая | Средняя до высокой |
| Производительность записи | Высокая | Низкая | Средняя |
| Сложность реализации | Низкая | Высокая | Средняя |
| Поддерживает глубокие деревья | Да | Да | Да (с ограничениями) |
| Логика запросов | Рекурсивная | Сканирование диапазона | Совпадение префикса |
⚙️ Соображения производительности
При моделировании иерархии необходимо учитывать, как база данных обрабатывает данные. Стратегии индексации играют ключевую роль независимо от выбранной модели.
- Список смежности: Проиндексируйте
parent_idстолбец сильно. Это позволяет базе данных быстро находить всех потомков конкретного узла, не сканируя всю таблицу. - Вложенные множества: Индексировать оба
lftиrgt. Составные индексы могут значительно оптимизировать запросы диапазона. - Материализованный путь: Индексировать столбец
pathстолбец. В зависимости от базы данных, префиксный индекс может быть полезен для фильтрации поддеревьев.
🛠️ Обслуживание и обновления
Модели данных не являются статичными. По мере роста вашей организации иерархия будет меняться. Перемещение узла с одного филиала на другой — распространенная операция, которая влияет на каждую модель по-разному.
🔄 Перемещение узлов
В списке смежности, перемещение узла — это одна операция обновления. Вы изменяете parent_id корня поддерева. Однако вы должны убедиться, что не создаются циклические ссылки.
В модели Вложенный набор модель перемещение узла является сложным. Это включает пересчет значений lft и rgt для всех узлов в поддереве назначения, чтобы освободить место для перемещаемого узла. Это часто транзакционная операция, включающая несколько обновлений таблиц.
В модели Материализованный путь модель вы обновляете строку пути перемещаемого узла и всех его потомков. Это требует обновления пути для каждого потомка, что может быть тяжелой операцией записи для больших деревьев.
🎯 Лучшие практики моделирования данных
Чтобы обеспечить, что ваша ERD останется поддерживаемой и производительной, при реализации иерархических структур соблюдайте эти рекомендации.
- Используйте четкие соглашения об именовании: Избегайте общих имен, таких как
col1. Используйтеparent_id,ancestor_id,lft, илиrgtявно. - Применяйте ограничения: Используйте ограничения базы данных, чтобы предотвратить циклические ссылки. Узел не может быть собственным предком.
- Ограничьте глубину: Хотя технически возможно, чрезвычайно глубокие иерархии (например, более 10 уровней) часто указывают на ошибку проектирования. Рассмотрите возможность упрощения структуры, если это возможно.
- Документируйте выбор: Поскольку эти паттерны не являются стандартными функциями SQL, документируйте, какой паттерн используется в документации схемы.
- Рассмотрите гибридные подходы: Некоторые системы комбинируют списки смежности с материализованными путями, чтобы сбалансировать производительность чтения и записи.
🧠 Выбор правильной стратегии
Нет единственно правильного ответа для каждого сценария. Решение зависит от конкретных требований вашего приложения.
- Выберите список смежности, если: Ваши данные часто изменяются, а глубина иерархии умеренная. Это самый безопасный вариант по умолчанию для большинства приложений общего назначения.
- Выберите вложенные множества, если: У вас приложение с высокой нагрузкой на чтение, где данные редко перемещаются, и вам нужно быстро извлекать большие поддеревья.
- Выберите материализованный путь, если: Вам нужны читаемые человеком пути (например, URL-адреса), а глубина иерархии относительно небольшая.
Понимание этих структурных нюансов позволяет вам проектировать масштабируемые базы данных. Выбирая подходящий паттерн для диаграммы сущность-связь, вы обеспечиваете, что ваша информация останется согласованной, доступной и эффективной на протяжении всего жизненного цикла системы.