











В современных архитектурах данных скорость извлечения информации часто определяет пригодность приложения. Хотя обновление оборудования и стратегии кэширования играют важную роль, основа производительности заключается в структуре данных. В частности, дизайн моделей сущностей и отношений (ERD) определяет, насколько эффективно движок базы данных может обходить, объединять и агрегировать данные. Оптимизированная схема не просто организует информацию; она направляет оптимизатор запросов к более быстрым путям выполнения. 📉
В этом руководстве рассматриваются технические аспекты проектирования схемы и их прямая связь с производительностью запросов. Мы изучим, как уровни нормализации, кардинальность отношений и стратегии индексации взаимодействуют в плане выполнения запросов. Понимая эти динамики, разработчики и архитекторы баз данных могут создавать системы, которые масштабируются без ущерба для целостности или скорости.
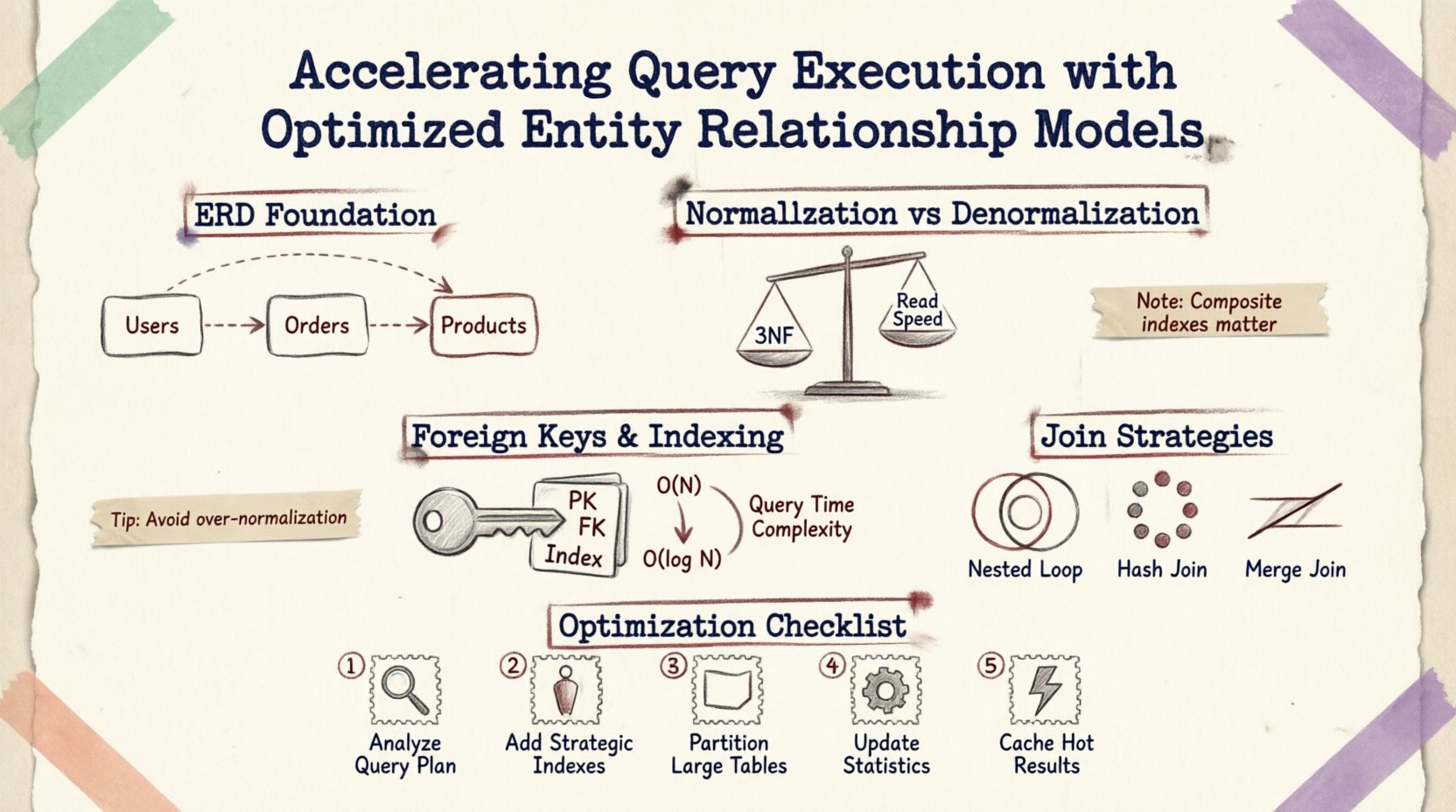
Понимание основ: ERD и производительность 🗃️
Диаграмма сущностей и отношений — это не просто визуальная поддержка для документации; это чертеж логики физического хранения и извлечения данных. Каждая линия, соединяющая таблицы, представляет собой ограничение внешнего ключа, операцию объединения или правило целостности данных. При отправке запроса движок базы данных интерпретирует эти отношения для построения плана выполнения.
Рассмотрим простой запрос, запрашивающий заказы пользователя и сведения о продуктах. Движок должен:
- Найти таблицу
Пользователитаблицу. - Следовать внешнему ключу к таблице
Заказытаблицу. - Объединить таблицу
Позиции заказовтаблицу. - Достичь таблицы
Продуктытаблицы через другое отношение.
Каждый шаг включает операции ввода-вывода и циклы процессора. Если отношения плохо определены, движок может прибегнуть к полным сканированиям таблиц или вложенным циклам объединения, что экспоненциально снижает производительность. Оптимизация ERD уменьшает расстояние, которое данные должны пройти от диска до памяти.
Нормализация против денормализации: Поиск баланса ⚖️
Нормализация — это процесс организации данных для уменьшения избыточности и повышения целостности. Хотя она необходима для согласованности, чрезмерная нормализация может фрагментировать данные по множеству малых таблиц, что требует сложных объединений и замедляет операции, ориентированные на чтение.
Стоимость глубокой нормализации
Когда схема нормализована до третьей нормальной формы (3NF), данные хранятся в наиболее атомарном виде. Это минимизирует объем хранимого пространства и аномалии обновления. Однако извлечение связанных данных часто требует перехода по нескольким внешним ключам.
- Накладные расходы на объединение: Каждая дополнительная таблица в цепочке объединений увеличивает сложность плана запроса.
- Конфликты блокировок: Доступ к нескольким таблицам увеличивает вероятность конфликтов блокировок на уровне строк.
- Использование ЦП: Движку базы данных необходимо объединить результаты из разных таблиц.
Когда следует денормализовать
Денормализация вводит избыточность для оптимизации производительности чтения. Это часто необходимо при аналитической обработке или в средах с высокой нагрузкой на отчетность.
- Нагрузки с преобладанием чтения: Если операции записи редки по сравнению с операциями чтения, добавление денормализованного столбца позволяет сэкономить операции объединения.
- Предварительно вычисленные агрегаты: Хранение итогов (например,
total_order_value) в таблице пользователей позволяет избежать вычисления сумм при каждом запросе. - Горизонтальное партиционирование: Сохранение часто используемых данных вместе улучшает локальность кэша.
Однако денормализация требует тщательного управления для предотвращения несогласованности данных. Логика приложения должна обеспечивать, чтобы избыточные данные обновлялись каждый раз, когда изменяются исходные данные.
Внешние ключи и стратегия индексации 🔑
Ограничения внешних ключей обеспечивают целостность ссылок, но сопряжены с издержками производительности. База данных должна проверять, существует ли значение в одной таблице в другой, прежде чем разрешить вставку или обновление. Оптимизация индексирования этих ключей имеет критическое значение.
Индексация внешних ключей
По умолчанию первичные ключи автоматически индексируются. Внешние ключи, однако, часто требуют явного индексирования для ускорения операций объединения. Без индекса на столбце внешнего ключа:
- Базе данных необходимо выполнить полный сканирование дочерней таблицы для поиска соответствующих строк.
- Операции объединения становятся значительно медленнее, особенно когда размеры таблиц достигают миллионов строк.
- Проверки целостности ссылок во время удаления становятся дорогостоящими.
Правильно проиндексированный внешний ключ позволяет базе данных использовать поиск по индексу вместо сканирования, снижая сложность с O(N) до O(log N).
Составные индексы для связей
Когда несколько столбцов определяют связь, составной индекс может быть более эффективным, чем отдельные индексы. Например, если запрос фильтрует по user_id и created_at в таблице заказов, составной индекс на обоих столбцах обеспечивает, что движок может найти данные без сканирования нерелевантных записей.
Стратегии объединения и планы выполнения 🔍
Структура ERD влияет на выбор алгоритмов объединения, которые выбирает оптимизатор запросов. Понимание этих механизмов помогает проектировать схемы, которые способствуют эффективным типам объединения.
| Тип объединения | Наилучшее использование при | Влияние на производительность |
|---|---|---|
| Вложенный цикл объединения | Небольшие наборы результатов или высокоселективные предикаты | Быстро для небольших данных; медленно при больших сканированиях |
| Хеш-соединение | Большие таблицы без индексов | Высокая нагрузка на память; хорошо подходит для неотсортированных данных |
| Слияние соединений | Отсортированные входные данные по ключам соединения | Очень быстро, если данные уже отсортированы |
Проектирование ERD для поддержки отсортированных входных данных или индексированных поисков может побудить оптимизатор выбирать более быстрые методы соединения. Например, обеспечение того, что ключи соединения определены как часть кластеризованного индекса, может способствовать использованию слияния соединений.
Распространённые ошибки при проектировании схемы 🚫
Даже опытные архитекторы допускают ошибки, влияющие на скорость запросов. Выявление этих паттернов на ранних этапах предотвращает дорогостоящую рефакторизацию позже.
- Цепочка внешних ключей: Создание цепочки связей, где Таблица A ссылается на B, B — на C, а C — на D. Запросы, соединяющие все четыре таблицы, становятся глубоко вложенными и медленными.
- Строки переменной длины: Использование
VARCHARдля ключей, которые всегда имеют фиксированную длину, может привести к потере памяти и замедлению сравнения строк. - Многие-ко-многим без промежуточных таблиц: Попытка хранить несколько идентификаторов в одном столбце (например, разделённых запятыми) препятствует правильному индексированию и нормализации.
- Неявные преобразования: Определение несовпадающих типов данных между родительской и дочерней таблицами вынуждает движок преобразовывать значения во время выполнения, что препятствует использованию индексов.
Практические шаги по оптимизации 🛠️
Чтобы улучшить выполнение запросов без переписывания всей системы, следуйте этим структурированным шагам:
- Анализируйте шаблоны запросов: Просмотрите наиболее частые операции чтения. Определите, какие таблицы чаще всего соединяются.
- Проверьте использование индексов: Проверьте наличие отсутствующих индексов по внешним ключам или часто фильтруемым столбцам.
- Уточните кардинальность: Убедитесь, что отношения точно моделируются (один к одному против один ко многим). Неправильная кардинальность может привести к избыточным соединениям.
- Разделение больших таблиц:Если таблица содержит более миллиона строк, рассмотрите возможность разделения по дате или региону, чтобы ограничить объем данных, сканируемых за один запрос.
- Мониторинг блокировок:Используйте инструменты мониторинга для выявления длительных запросов, удерживающих блокировки, часто вызванных неэффективным обходом схемы.
Рассмотрение вопросов хранения и памяти 💾
Физическое расположение данных также играет роль. Двигатели баз данных хранят данные на страницах. Если связанные строки хранятся физически близко друг к другу, для загрузки набора данных требуется меньше операций чтения с диска.
- Кластеризация:Организация данных по общему ключу может улучшить сканирование диапазонов.
- Хранение по столбцам против хранения по строкам:Для аналитических запросов хранение по столбцам может обеспечить лучшую компрессию и более быструю агрегацию по сравнению с традиционными моделями хранения по строкам.
- Кэширование:Проектируйте схемы, которые позволяют эффективно кэшировать полные наборы результатов, а не отдельные строки.
Заключительные мысли о развитии схемы 🔄
Проектирование схемы — это не разовое задание. По мере изменения требований приложения модель данных должна эволюционировать. Регулярная проверка структуры базы данных гарантирует, что производительность остается стабильной. Документация модели взаимоотношений сущностей должна поддерживаться вместе с кодовой базой, чтобы отслеживать, как изменения влияют на систему.
Фокусируясь на структурной целостности и логических связях внутри данных, вы создаете основу, поддерживающую высокоскоростное выполнение запросов. Цель — не создавать статическую систему, а гибкую архитектуру, способную адаптироваться к нагрузке без ущерба для скорости, которую ожидают пользователи. 📊
Оптимизация модели взаимоотношений сущностей — это техническая дисциплина, сочетающая теорию баз данных с практическим инженерным подходом. Для этого требуются терпение, анализ и четкое понимание того, как базовый движок обрабатывает запросы. При правильном подходе проблемы производительности становятся управляемыми, а извлечение данных — бесшовным.