











Производительность базы данных часто зависит от факторов, незаметных для случайного наблюдателя. Одним из таких критически важных факторов является конкуренция за блокировки. Когда несколько пользователей или процессов одновременно пытаются получить доступ к одним и тем же данным, система должна применять правила для поддержания целостности данных. Эти правила приводят к блокировкам. Избыточные блокировки вызывают узкие места, замедляют время отклика и раздражают конечных пользователей. Корень проблемы часто не в аппаратных средствах, а в диаграмме сущность-связь (ERD), определяющей структуру данных.
Хорошо спроектированная схема служит основой для высокой конкуренции. Прогнозируя, как будут обращаться к данным и изменять их, архитекторы могут структурировать таблицы для минимизации конфликтов. Такой подход требует глубокого понимания изоляции транзакций, стратегий индексации и физических механизмов блокировок. В следующем руководстве описано, как оптимизировать модель данных для лучшей производительности без использования внешних инструментов.
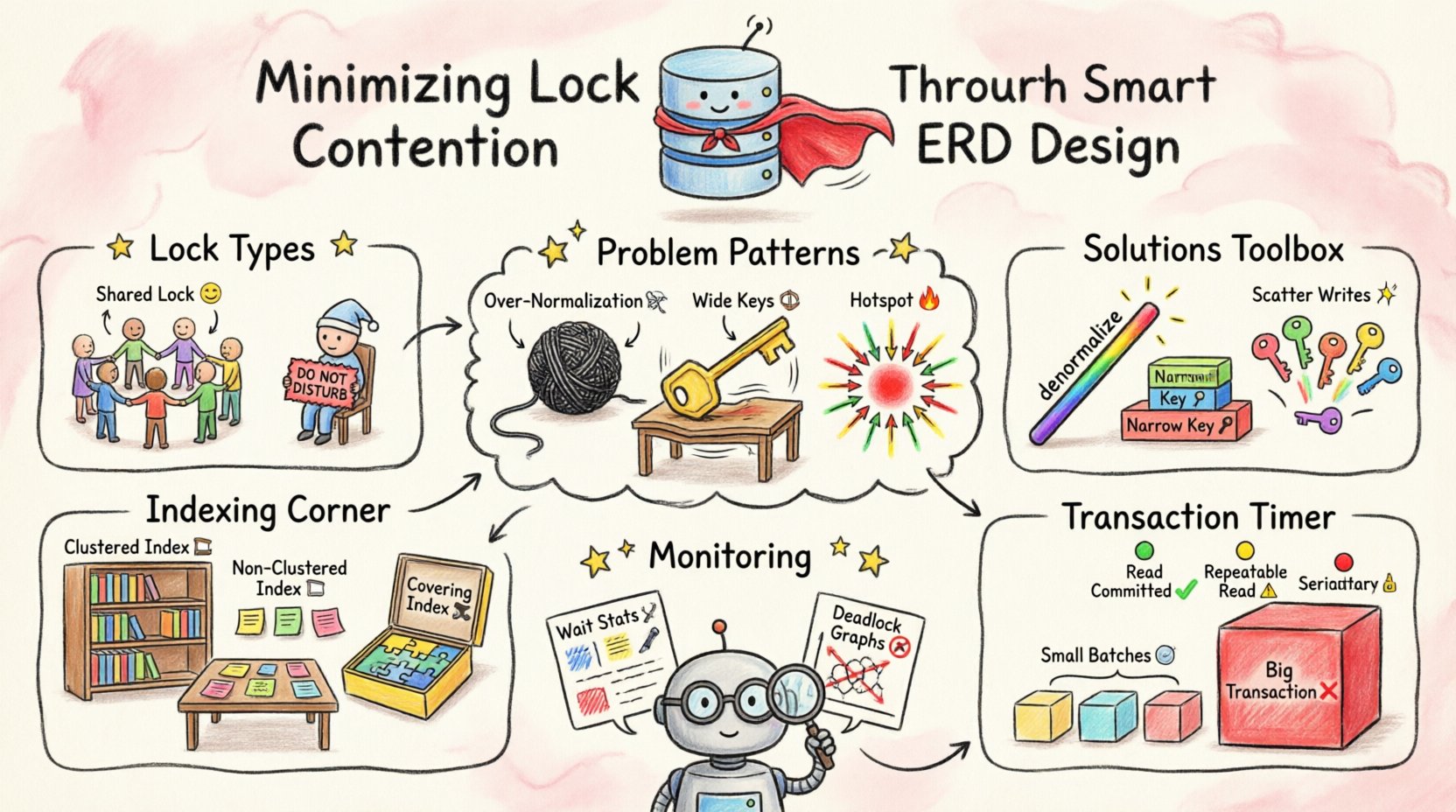
Понимание механизмов блокировки 🛡️
Прежде чем оптимизировать дизайн, необходимо понимать, что на самом деле делают блокировки. Базы данных используют блокировки для предотвращения несогласованности. Если две транзакции пытаются обновить одну и ту же строку в точный момент времени, возникает конфликт. Система должна решить, кто будет первым.
- Общие блокировки (S): Используются для чтения данных. Несколько транзакций могут одновременно удерживать общие блокировки на одном и том же ресурсе.
- Исключительные блокировки (X): Используются для записи или изменения данных. В любой момент времени только одна транзакция может удерживать исключительную блокировку на ресурсе.
- Блокировки намерений: Указывают на то, что транзакция намерена установить блокировку на более низком уровне иерархии, например, на таблицу или страницу.
Конкуренция за блокировки возникает, когда спрос на исключительные блокировки превышает возможности для общего доступа. Если ваша ERD заставляет базу данных сканировать большие участки таблицы для поиска данных, это увеличивает масштаб удерживаемых блокировок. Это усиливает вероятность столкновений между параллельными процессами.
Шаблоны схемы, вызывающие конкуренцию 📉
Определённые решения в проектировании неизбежно увеличивают площадь поверхности для блокировок. Признание этих паттернов позволяет провести рефакторинг на ранних этапах жизненного цикла разработки.
1. Избыточная нормализация
Хотя нормализация уменьшает избыточность, чрезмерная нормализация может негативно сказаться на производительности. Объединение многих таблиц для получения одного записей требует блокировки нескольких строк в нескольких таблицах. Если транзакции нужно прочитать данные из пяти нормализованных таблиц, она приобретает блокировки на всех из них.
- Риск: Если другая транзакция изменит одну из этих таблиц, первая транзакция может ожидать.
- Решение: Рассмотрите возможность денормализации часто объединяемых столбцов. Уменьшение количества соединений снижает количество блокировок, необходимых на каждый запрос.
2. Широкие первичные ключи
Первичные ключи используются для уникальной идентификации строк. Если первичный ключ является составным ключом, охватывающим несколько столбцов, это влияет на способ построения индексов. Широкие ключи увеличивают размер индекса.
- Риск: Более крупные индексы означают больше страниц для чтения и блокировки при поиске. Обновление первичного ключа может вызвать каскадные изменения в связанных таблицах.
- Решение: Где возможно, используйте простые, узкие заменяющие ключи (например, целые числа). Держите составные ключи минимальными и только тогда, когда это логически необходимо.
3. Зоны перегрузки в последовательных ключах
Использование автоинкрементных целых чисел в качестве первичных ключей — распространённая практика. Однако если приложение вставляет данные последовательно, все новые записи направляются в конец индекса. Это создаёт «узкое место», где многие транзакции конкурируют за одну и ту же листовую страницу.
- Риск: Движок базы данных должен блокировать последнюю страницу индекса при каждой новой вставке.
- Исправление: Используйте случайные ключи или распределение на основе хэширования для сценариев с высокой записью, чтобы равномерно распределить нагрузку по разным страницам.
Стратегии оптимизации схемы 🛠️
Оптимизация ERD включает в себя конкретные решения по столбцам, отношениям и ограничениям. В таблице ниже перечислены распространенные решения при проектировании и их влияние на поведение блокировок.
| Решение при проектировании | Влияние на блокировки | Рекомендуемый подход |
|---|---|---|
| Ограничения внешнего ключа | Может вызвать каскадные блокировки в родительских таблицах. | Используйте отложенные ограничения или проверку на уровне приложения для систем с высокой записью. |
| Большие столбцы BLOB/текст | Увеличивает размер строки, требуя больше страниц на строку. | Храните большие данные отдельно, чтобы основная таблица оставалась узкой. |
| Столбцы с высокой кардинальностью | Может привести к неэффективному использованию индексов. | Обеспечьте индексирование выборочных столбцов, чтобы избежать полного сканирования таблицы. |
| Значения по умолчанию | Обновляет строки без необходимости, если применяются значения по умолчанию. | Разрешайте NULL там, где это уместно, чтобы избежать триггеров записи. |
Разделение моделей записи и чтения
Разделение схемы, используемой для записи, от схемы, используемой для чтения, может значительно снизить конкуренцию. Модели записи ориентированы на целостность и нормализацию. Модели чтения ориентированы на скорость и денормализацию.
- Храните данные в сильно нормализованной структуре для обработки транзакций.
- Реплицируйте данные в структуру, оптимизированную для чтения, для отчетов или отображения.
- Это гарантирует, что тяжелые запросы на чтение не блокируют операции записи.
Индексация и выбор ключей 📊
Индексы жизненно важны для производительности, но они не бесплатны. Каждый индекс должен поддерживаться при обновлении. Если в таблице слишком много индексов, каждая вставка или обновление требует блокировки нескольких структур индексов.
Кластеризованные и некластеризованные
- Кластеризованный индекс: Определяет физический порядок данных. Обычно один на таблицу. Выбирайте его внимательно, так как это влияет на способ хранения данных.
- Некластеризованный индекс: Отдельная структура, указывающая на данные. Полезно для покрытия запросов без обращения к основной таблице.
Избегайте создания индексов для столбцов, которые часто обновляются. Когда значение столбца изменяется, индекс необходимо перестроить. Этот процесс создает блокировки записи на структуру индекса.
Покрывающие индексы
Покрывающий индекс включает все столбцы, необходимые для запроса. Это позволяет базе данных удовлетворить запрос без обращения к фактическим данным таблицы. Это уменьшает объем блокировок, поскольку движку не нужно блокировать строки базовой таблицы.
- Определите часто выполняемые запросы на чтение.
- Создайте индексы, которые включают столбцы
SELECTстолбцы. - Мониторьте планы выполнения запросов, чтобы убедиться, что эти индексы используются.
Область действия транзакций и изоляция ⏱️
ERD влияет на поведение транзакций. Долгие транзакции удерживают блокировки в течение более длительного времени. Хорошо структурированная схема помогает сократить время транзакций.
Пакетная обработка
Вместо обработки тысяч строк в одной транзакции разбейте работу на более мелкие пакеты. Это освобождает блокировки раньше, позволяя другим процессам продолжать работу.
- Ограничьте количество строк, изменяемых за один коммит.
- Используйте курсоры или циклы для обработки данных порциями.
- Сбалансируйте накладные расходы от нескольких коммитов с выгодой от сокращения времени блокировки.
Уровни изоляции
Системы баз данных предлагают различные уровни изоляции. Более высокие уровни изоляции (например, Serializable) предотвращают больше аномалий, но увеличивают блокировки. Более низкие уровни изоляции (например, Read Committed) позволяют большую конкуренцию.
- Избегайте уровня Serializable, если это не строго необходимо для финансовой точности.
- Для большинства операционных задач используйте Read Committed или Repeatable Read.
- Согласуйте уровень изоляции с бизнес-требованиями к согласованности данных.
Мониторинг и итерации 🔄
Проектирование — это не одноразовая задача. По мере изменения паттернов использования изменяются и проблемы конкуренции блокировок. Для поддержания производительности требуется непрерывный мониторинг.
- Статистика ожидания: Отслеживайте, как долго транзакции ждут блокировок.
- Графики взаимоблокировок: Анализируйте диаграммы, показывающие, какие запросы вызвали взаимоблокировки.
- Производительность запросов: Определите медленные запросы, которые могут удерживать блокировки дольше, чем ожидалось.
Регулярно анализируйте ERD по текущим метрикам производительности. Если конкретная таблица постоянно показывает высокие времена ожидания, рассмотрите возможность разделения данных или изменения схемы для снижения нагрузки.
Заключительные мысли о архитектуре данных 🧩
Минимизация конкуренции за блокировки — это баланс между целостностью данных и пропускной способностью системы. Проектируя схемы с учетом параллелизма, вы снижаете необходимость в разрешении конфликтов движком базы данных. Это приводит к более быстрым временам отклика и более стабильной системе.
Начните с аудита текущих связей и ключей. Ищите возможности упростить соединения и уменьшить избыточность индексов. Протестируйте свои изменения в среде тестирования, чтобы проверить влияние на поведение блокировок. При тщательном планировании и внимании к деталям вы сможете создать надежный слой данных, который эффективно масштабируется.