











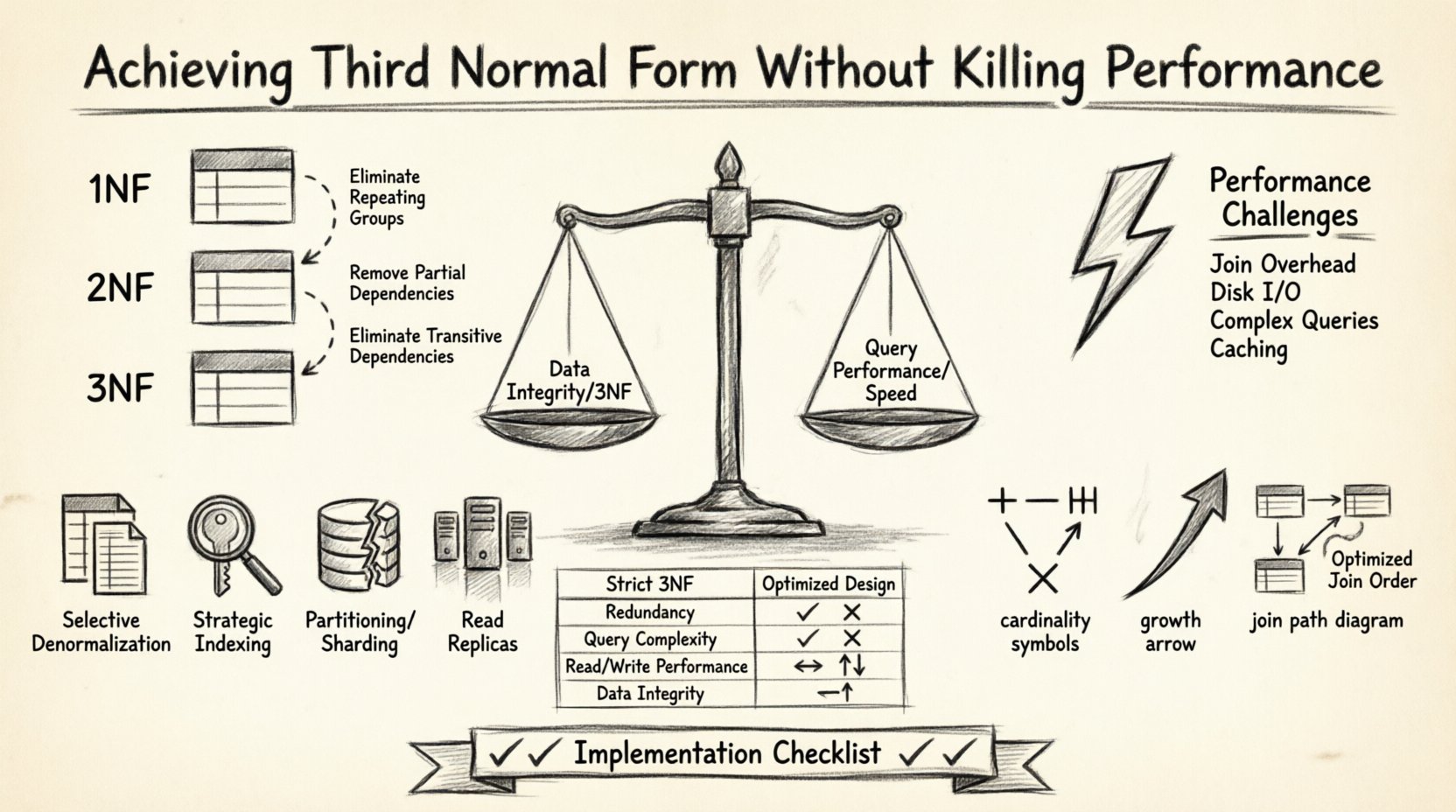
Проектирование надежной структуры базы данных — это баланс. С одной стороны, вы имеете целостность данных и устранение избыточности за счет нормализации. С другой — скорость запросов и отзывчивость системы. Многие архитекторы баз данных сталкиваются с трудным выбором: придерживаться строгих правил нормализации и рисковать медленными запросами, или агрессивно денормализовать и рисковать несогласованностью данных. Цель — найти золотую середину, при которой база данных соответствует третьей нормальной форме (3НФ), сохраняя при этом высокую производительность. В этой статье рассматривается, как структурировать диаграммы сущность-связь (ERD), чтобы достичь этого равновесия, не жертвуя ни целостностью, ни скоростью.
Понимание третьей нормальной формы 🧩
Третья нормальная форма — это определенный уровень нормализации базы данных. Перед достижением 3НФ таблица должна сначала соответствовать первой нормальной форме (1НФ) и второй нормальной форме (2НФ). Основной принцип 3НФ заключается в том, что все атрибуты должны зависеть только от первичного ключа. Должны отсутствовать транзитивные зависимости.
- Первая нормальная форма: Устраняет повторяющиеся группы и обеспечивает атомарные значения.
- Вторая нормальная форма: Устраняет частичные зависимости, при которых не ключевые атрибуты зависят только от части составного ключа.
- Третья нормальная форма: Устраняет транзитивные зависимости. Если A определяет B, а B определяет C, то C не должен напрямую зависеть от A в одной и той же таблице.
Когда вы достигаете 3НФ, вы минимизируете аномалии обновления. Это ошибки, возникающие при изменении данных в одном месте, но не в других, что приводит к несогласованности. Например, если адрес клиента хранится как в таблице «Заказы», так и в таблице «Клиенты», изменение адреса в одной таблице, но не в другой, создает расхождение. 3НФ заставляет хранить этот адрес только в одном месте.Заказы таблице, так и в таблице Клиенты таблице, изменение адреса в одной таблице, но не в другой, создает расхождение. 3НФ заставляет хранить этот адрес только в одном месте.
Компромисс производительности ⚡
Хотя 3НФ отлично подходит для целостности данных, она часто сопряжена с потерей производительности. Нормализованные базы данных обычно требуют большего количества таблиц. Чтобы получить полный набор данных, базе данных необходимо выполнить несколько соединений. Каждая операция соединения требует от системы чтения данных с диска или из памяти, сопоставления ключей и объединения результатов.
Рассмотрим запрос отчетности, который требует имен клиентов, деталей заказов, описаний продуктов и адресов доставки. В полностью нормализованной структуре 3НФ это может потребовать соединения пяти или более таблиц. Если объем данных велик, такие соединения могут стать узким местом.
Вот конкретные проблемы производительности, связанные с 3НФ:
- Увеличение накладных расходов на соединение: Каждое отношение требует операции соединения при выполнении запросов на чтение.
- Ввод-вывод на диск: Распространение данных по многим таблицам увеличивает количество страниц, которые должна прочитать база данных.
- Сложная логика запросов: Приложения должны строить более сложные SQL-запросы для получения связанных данных.
- Сложность кэширования: Кэширование одной денормализованной строки проще, чем кэширование нескольких связанных строк.
Стратегии баланса целостности и скорости 🚀
Вам не нужно отказываться от нормализации, чтобы улучшить производительность. Существуют конкретные методы оптимизации базы данных 3НФ, сохраняя при этом структуру. Ниже приведены стратегии, которые помогают сохранить качество данных без потери скорости.
1. Выборочная денормализация
Не каждая таблица должна строго соответствовать 3НФ. Определите таблицы с высокой нагрузкой на чтение и критические пути данных. В этих конкретных областях можно ввести контролируемую избыточность. Например, храните имя клиента непосредственно в таблице Заказы таблице. Хотя это приводит к дублированию данных, выигрыш в производительности при поиске заказов значителен. Затем необходимо реализовать триггер или логику приложения для поддержания актуальности этой копии при изменении записи клиента.
2. Стратегическое индексирование
Индексы — основной инструмент для ускорения соединений. Без индексов база данных выполняет полное сканирование таблицы для каждого условия соединения. При правильном индексировании поиски становятся практически мгновенными.
- Индексы внешних ключей: Всегда индексируйте столбцы, используемые в отношениях внешних ключей. Это обеспечивает быстрое соединение таблиц.
- Составные индексы: Создавайте индексы на нескольких столбцах, если ваши запросы часто фильтруют по этой комбинации.
- Покрывающие индексы: Проектируйте индексы, включающие все столбцы, необходимые для конкретного запроса. Это позволяет базе данных удовлетворить запрос, используя только индекс, избегая поиска в основных данных таблицы.
3. Разделение и шардинг
Если объем данных становится слишком большим, разделение таблиц может улучшить производительность. Разделение делит большую таблицу на более мелкие, удобные для управления физические части на основе ключа, например, даты или региона. Шардинг распределяет данные по нескольким экземплярам базы данных. Оба метода уменьшают объем данных, которые необходимо сканировать для ответа на конкретный запрос.
4. Реплики для чтения
Разделите операции записи и чтения. Используйте основной экземпляр базы данных для транзакций и обновлений. Реплицируйте эти данные на одну или несколько реплик для чтения. Сложные запросы отчетности, нагружающие систему, можно выполнять на репликах, сохраняя основную систему быстрой для взаимодействия с пользователями.
Рассмотрение при проектировании диаграмм сущность-связь 📐
При построении диаграммы сущность-связь визуальное представление влияет на то, как разработчики пишут запросы. Четкая ERD помогает выявить отношения на ранних этапах. Однако диаграмма, выглядящая идеально на бумаге, может плохо работать в производственной среде. Вот как следует подходить к проектированию ERD с точки зрения производительности.
- Четко определите кардинальность: Убедитесь, что каждое отношение имеет определенную кардинальность (один к одному, один ко многим, многие ко многим). Неоднозначные отношения приводят к неэффективным соединениям.
- Планируйте рост: Учитывайте будущий объем данных. Проектирование, работающее для 10 000 строк, может не справиться с 10 миллионами строк.
- Проверьте пути соединений: Проделайте путь, который будет проходить типичный запрос через диаграмму. Если путь слишком длинный, рассмотрите возможность добавления денормализованного столбца.
- Документируйте ограничения: Явно документируйте, какие ограничения реализуются базой данных, а какие — на уровне приложения.
Сравнение: нормализованная и оптимизированная архитектура 📊
В таблице ниже показаны различия между строгим подходом 3НФ и оптимизированным подходом для конкретной ситуации.
| Функция | Строгая архитектура 3НФ | Оптимизированная архитектура |
|---|---|---|
| Избыточность | Минимальная | Контролируемая и ограниченная |
| Сложность запроса | Высокая (множественные соединения) | Средняя (меньше соединений) |
| Производительность записи | Быстрая (меньше данных) | Переменная (триггеры обновления) |
| Производительность чтения | Медленнее (ввод-вывод на диске) | Быстрее (данные в кэше) |
| Целостность данных | Высокая | Высокая (с проверкой) |
Когда можно нарушить правила 🛑
Существуют обоснованные сценарии, когда строгий 3НФ можно игнорировать. Понимание того, когда нужно отклоняться от правил, критически важно для архитекторов баз данных.
- Отчетность и аналитика:Хранилища данных часто используют звездообразную схему вместо 3НФ. Цель здесь — скорость чтения для анализа, а не целостность транзакций.
- Системы с высокой пропускной способностью для транзакций: Если система обрабатывает миллионы записей в секунду, сложные соединения могут вызвать конкуренцию за блокировки. Упрощение схемы может снизить накладные расходы на блокировки.
- Устаревшие системы: При миграции с устаревшей системы может быть быстрее временно денормализовать данные во время перестройки слоя приложения.
- Приложения с высокой нагрузкой на чтение: Если ваше приложение читает данные в 100 раз чаще, чем записывает, затраты на поддержание согласованности 3НФ превышают выгоды.
Чек-лист реализации ✅
Перед развертыванием схемы базы данных пройдитесь по этому чек-листу, чтобы убедиться, что вы достигли баланса между производительностью и нормализацией.
- Анализируйте шаблоны запросов: Определите наиболее часто используемые запросы на чтение. Требуют ли они слишком много соединений?
- Измерьте текущую производительность: Задайте базовые показатели для вашей системы. Знайте текущую задержку критических запросов.
- Проверьте использование индексов: Проверьте, используются ли индексы, или они создают избыточную нагрузку при записи данных.
- Проверьте нагрузку при записи: Убедитесь, что любая стратегия денормализации не замедляет операции записи слишком сильно.
- Планируйте синхронизацию данных: Если вы дублируете данные, как вы будете поддерживать их синхронизацию? Определите механизм.
- Мониторьте аномалии: Настройте оповещения об несогласованности данных, если вы используете частичную денормализацию.
Заключительные мысли о архитектуре базы данных 🏗️
Достижение третьей нормальной формы без ущерба для производительности требует тонкого подхода. Это не двоичный выбор между скоростью и целостностью. Понимая стоимость соединений, эффективно используя индексы и применяя выборочную денормализацию в подходящих случаях, вы можете создавать системы, которые одновременно надежны и быстры. Лучшая архитектура базы данных — это та, которая соответствует конкретной нагрузке приложения. Регулярно пересматривайте свою ERD и производительность запросов по мере роста системы. Адаптация — ключ к долгосрочному успеху в управлении данными.