











Архитектура данных формирует основу любого надежного цифрового систем. Когда приложение масштабируется, лежащая в основе структура должна эволюционировать, чтобы справиться с увеличивающейся нагрузкой, сложностью и объемом данных. Диаграмма сущностей и отношений (ERD) — это не просто статическая карта; это стратегический чертеж, определяющий, как информация течет, взаимосвязана и сохраняется в базе данных. Проектирование с учетом роста требует прозорливости, чтобы убедиться, что схема сможет вместить будущие требования без необходимости полной перестройки.
Плохо спроектированная модель приводит к узким местам, медленной производительности запросов и жестким ограничениям, которые тормозят скорость разработки. Напротив, хорошо спроектированная ERD поддерживает гибкость, целостность и эффективность. В этом руководстве рассматриваются основные принципы создания моделей данных, способных выдержать испытание временем и расширением.
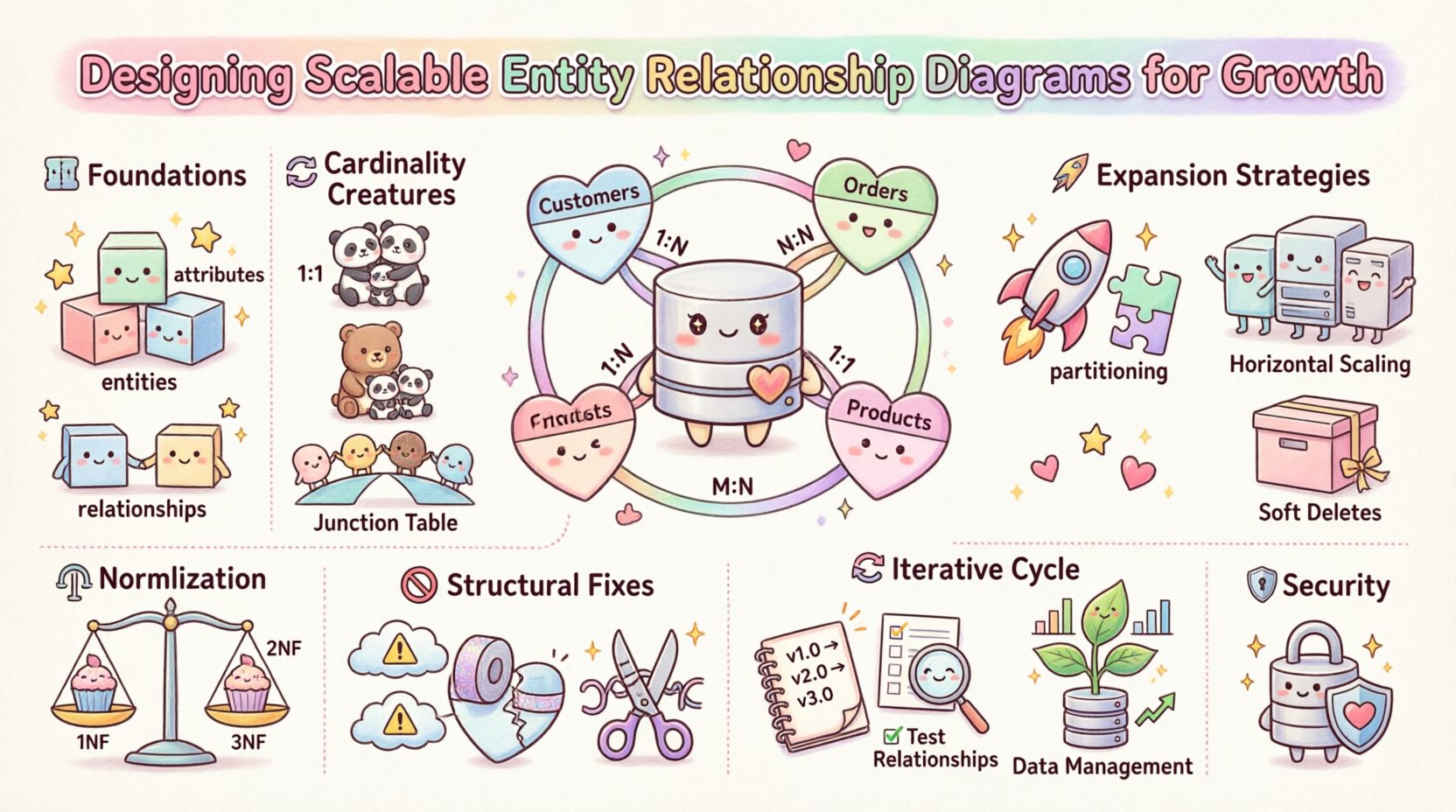
Основы моделирования сущностей 🏗️
Прежде чем решать вопрос масштабируемости, необходимо понимать основные компоненты. Диаграмма сущностей и отношений визуализирует структуру данных через три основных элемента: сущности, атрибуты и отношения.
-
Сущности: Они представляют объекты или концепции в системе, например, Пользователь, Продукт, или Заказ. В физической базе данных сущности транслируются в таблицы.
-
Атрибуты: Это конкретные свойства, описывающие сущность, например, имя пользователя, цена, или дата создания. Атрибуты определяют степень детализации хранения данных.
-
Отношения: Они определяют, как сущности взаимодействуют между собой. Отношение устанавливает логику, связывающую одну сущность с другой, часто с помощью внешних ключей.
Четкость в этих определениях предотвращает неоднозначность на этапе разработки. Каждое поле должно иметь четкую цель, а каждое отношение должно соответствовать логическому бизнес-правилу. Неоднозначность на этапе проектирования часто приводит к дорогостоящей рефакторинге в будущем.
Мощность и множественность 🔄
Понимание мощности отношений критически важно для масштабируемости. Мощность определяет количество экземпляров одной сущности, которые могут или должны быть связаны с каждым экземпляром другой сущности. Неправильное толкование этого приводит к неэффективному хранению данных и сложным запросам.
-
Один к одному (1:1): Запись в таблице A связана с точно одной записью в таблице B. Это редкость в системах с высокой нагрузкой, но полезно для разделения конфиденциальных данных или необязательных атрибутов, чтобы уменьшить ширину таблицы.
-
Один ко многим (1:N): Одна запись в таблице A связана с несколькими записями в таблице B. Это наиболее распространённое отношение, например, одна Клиент имеющий много Заказы.
-
Многие ко многим (M:N): Записи в таблице А связаны с несколькими записями в таблице Б, и наоборот. Для реализации этого требуется промежуточная таблица, которая преобразует связь в две связи «один ко многим».
По мере роста объема данных связи «многие ко многим» могут стать узкими местами производительности. Промежуточная таблица должна быть тщательно проиндексирована, чтобы обеспечить, что поиск не снижает скорость системы. Дизайнеры должны оценить возможность упрощения связи «многие ко многим» до структуры «один ко многим» за счет введения промежуточного понятия.
Стратегии нормализации для производительности ⚖️
Нормализация — это процесс организации данных для уменьшения избыточности и повышения целостности. Хотя ее часто рассматривают как статическое правило, степень нормализации напрямую влияет на масштабируемость.
-
Первое нормальное состояние (1NF): Обеспечивает атомарные значения. Каждый столбец содержит только одно значение, устраняя повторяющиеся группы.
-
Второе нормальное состояние (2NF): Основывается на 1NF за счет устранения частичных зависимостей. Неключевые атрибуты должны зависеть от всего первичного ключа.
-
Третье нормальное состояние (3NF): Устраняет транзитивные зависимости. Неключевые атрибуты должны зависеть только от первичного ключа, а не от других неключевых атрибутов.
Хотя строгая нормализация обеспечивает целостность данных, она может привести к накладным расходам производительности из-за большого количества соединений. Для операций чтения с высокой нагрузкой может потребоваться частичная денормализация. Это включает дублирование данных для уменьшения необходимости сложных соединений, обменивая место на диске на скорость запросов.
Решение о нормализации или денормализации должно определяться соотношением чтения и записи в приложении. Системы с высокой нагрузкой на запись выигрывают от более высокой нормализации для поддержания согласованности. Системы с высокой нагрузкой на чтение могут выиграть от денормализации, чтобы минимизировать операции соединения.
Планирование расширения 🚀
Масштабируемость — это не после мысль; она должна быть интегрирована в начальный дизайн. Несколько архитектурных решений, принятых на этапе ERD, влияют на то, как система справляется с ростом.
-
Разделение: Большие таблицы должны проектироваться с учетом разделения. Столбцы, используемые для разделения (например, регион или дата) должны быть проиндексированы и доступны без необходимости полного сканирования таблицы.
-
Горизонтальное масштабирование: Если данные распределены по нескольким узлам, схема должна поддерживать ключи шардирования. Избегайте использования глобальных уникальных идентификаторов в качестве единственного ключа разделения, если распределение не является равномерным.
-
Мягкое удаление: Вместо физического удаления записей помечайте их как неактивные. Это сохраняет целостность исторических данных и позволяет вести журналы аудита без блокировки строк во время процесса удаления.
Кроме того, учитывайте влияние метаданных. По мере расширения функциональности новые атрибуты добавляются часто. Избегайте жесткого кодирования логики в схеме базы данных. Используйте гибкие типы данных или столбцы JSON для атрибутов, которые могут различаться по типу сущности, при условии, что это не скажется на производительности запросов.
Общие структурные недостатки 🚫
Даже опытные дизайнеры сталкиваются с ловушками. Выявление общих структурных недостатков на ранних этапах может существенно сократить технический долг. В следующей таблице перечислены частые проблемы и их последствия.
|
Недостаток |
Влияние на рост |
Стратегия смягчения |
|---|---|---|
|
Жесткая связанность |
Изменения в одном объекте неожиданно нарушают работу других. |
Используйте слабую связанность через промежуточные таблицы или слои API. |
|
Отсутствующие индексы |
Задержка выполнения запросов экспоненциально возрастает с увеличением объема данных. |
Определите столбцы, часто используемые в запросах, и проиндексируйте их. |
|
Жесткие ограничения |
Изменения бизнес-логики требуют миграций схемы. |
Перенесите логику проверки в слой приложения, где это возможно. |
|
Чрезмерная нормализация |
Слишком много соединений замедляет операции чтения. |
Денормализуйте конкретные таблицы для рабочих нагрузок с интенсивным чтением. |
|
Неясные отношения |
Разработчики делают неверные предположения о потоке данных. |
Четко документируйте кардинальность и бизнес-правила. |
Итеративный процесс улучшения 🔄
Проектирование масштабируемой ERD редко является одноразовым событием. Это итеративный процесс, который развивается вместе с продуктом. Документация является критически важным компонентом этого цикла.
-
Контроль версий:Рассматривайте изменения схемы как код. Используйте скрипты миграции для отслеживания изменений во времени. Это позволяет выполнять откат изменений и проводить исторический анализ.
-
Циклы обзора:Проводите регулярные обзоры с заинтересованными сторонами. Убедитесь, что модель данных соответствует текущим бизнес-целям и предполагаемым будущим потребностям.
-
Тестирование:Моделируйте сценарии роста. Проведите нагрузочное тестирование базы данных с объемами данных, отражающими будущие прогнозы. Наблюдайте за поведением связей под нагрузкой.
Петли обратной связи являются обязательными. Если конкретный запрос постоянно работает медленно, вернитесь к ERD. Иногда небольшая корректировка связи или стратегии индексации решает проблему без крупных архитектурных изменений.
Управление ростом данных 📈
По мере зрелости системы объем данных увеличивается. ERD должен учитывать это, не жертвуя доступностью. При проектировании следует учитывать стратегии архивирования.
-
Исторические данные:Определите данные, к которым обращаются реже. Создайте разделы или таблицы специально для хранения исторических записей, чтобы активные таблицы оставались легкими.
-
Политики хранения:Определите правила хранения данных. Схема должна поддерживать поля, автоматически отслеживающие возраст данных или даты окончания срока действия.
-
Репликация:Планируйте использование реплик для чтения. Схема должна поддерживать операции только для чтения на вторичных узлах без конфликтов целостности данных.
Учитывайте стоимость хранения. Хранение ненужных данных увеличивает затраты и замедляет резервное копирование. Регулярные аудиты модели данных помогают выявить неиспользуемые таблицы или неиспользуемые атрибуты, которые можно удалить.
Безопасность и контроль доступа 🔒
Безопасность часто игнорируется при проектировании ERD. Однако отношения между данными определяют границы доступа. Контроль доступа на основе ролей (RBAC) должен отражаться в структуре данных.
-
Безопасность на уровне строк:Проектируйте таблицы с поддержкой безопасности на уровне строк. Это гарантирует, что пользователи получают доступ только к данным, относящимся к их роли, без сложной логики приложения.
-
Журналы аудита:Включите поля для отслеживания, кто создал или изменил запись. Это критически важно для соблюдения требований и отладки проблем в сложных системах.
-
Классификация данных:Метки чувствительных данных в схеме. Это позволяет автоматизированным инструментам применять политики шифрования или маскировки к определенным столбцам.
Включая соображения безопасности в диаграмму, вы снижаете риск утечек данных и упрощаете аудит соответствия. Отношения не должны предоставлять доступ к чувствительным данным неавторизованным сущностям, даже через косвенные соединения.
Заключение по устойчивой архитектуре 🛡️
Создание масштабируемой диаграммы сущность-связь требует баланса между теоретической целостностью и практической производительностью. Требуется глубокое понимание того, как данные взаимодействуют под нагрузкой. Сосредоточившись на четких отношениях, стратегической нормализации и перспективных паттернах проектирования, системы могут адаптироваться к росту без проблем.
Регулярное обслуживание и документирование обеспечивают актуальность модели по мере изменения бизнес-потребностей. Избегание распространенных ошибок и приоритет безопасности с самого начала создают основу для долгосрочного успеха. Цель заключается не просто в хранении данных, а в их структурировании таким образом, чтобы обеспечить эффективное движение всей организации вперед.