In the architecture of robust data systems, the Entity Relationship Diagram (ERD) serves as the foundational blueprint. As systems grow in complexity and data volume increases, maintaining a clean schema becomes critical. Redundancy in a large-scale ERD is not merely a matter of wasted storage; it is a source of systemic instability. When identical data points are stored in multiple locations without a mechanism to synchronize them, the risk of data inconsistency rises sharply.
This guide explores the technical strategies required to minimize redundancy while preserving the flexibility needed for high-volume applications. We will examine normalization principles, structural patterns, and verification methods to ensure your data model remains stable over time.
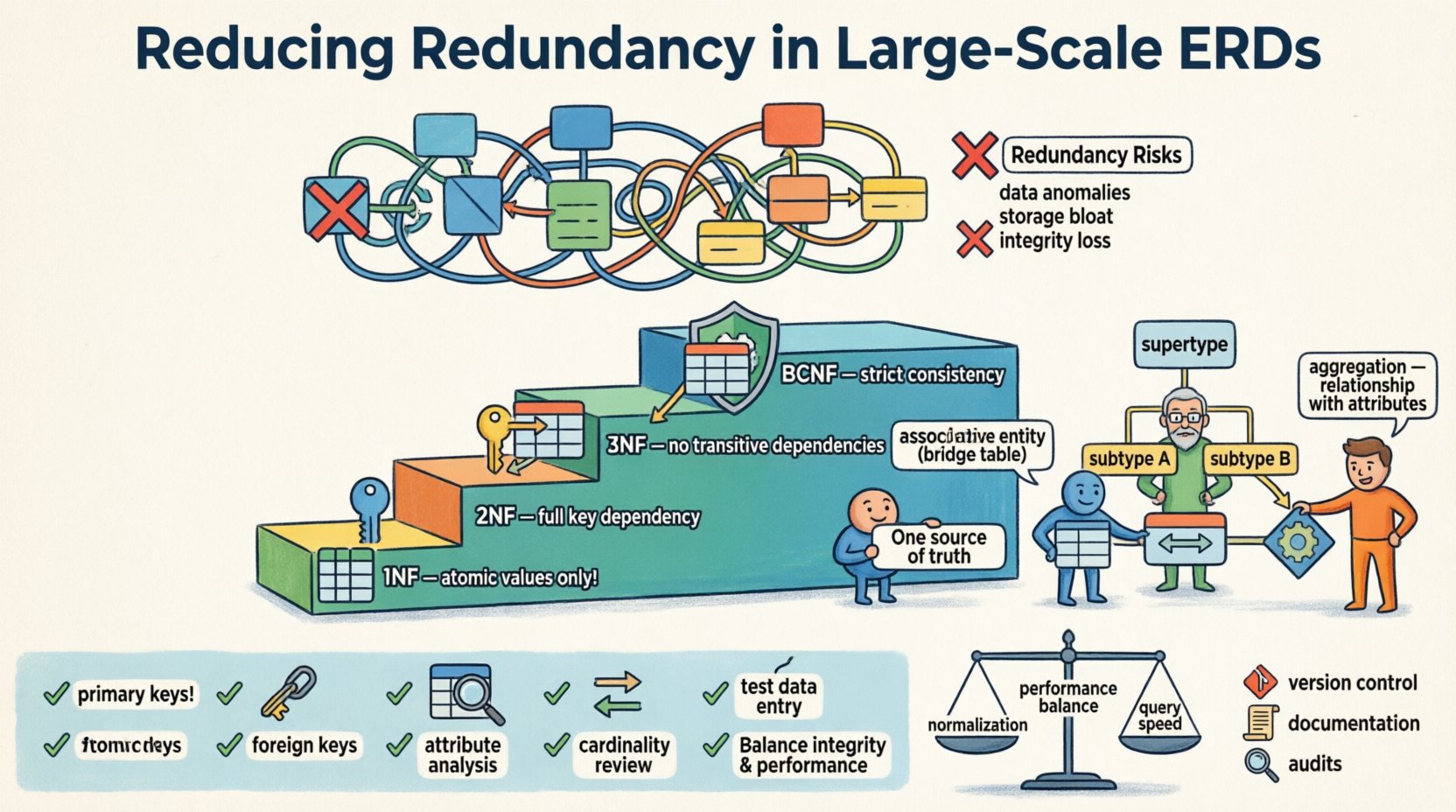
📉 The Cost of Duplication in Data Models
Redundancy occurs when the same piece of data is stored more than once within the database schema. While some denormalization is acceptable for performance optimization, uncontrolled duplication introduces several risks that become magnified in large-scale environments.
Data Anomalies: Updating information in one location but not another leads to conflicting records. This is known as an update anomaly.
Insertion Issues: Sometimes, you cannot add new data because related information is missing elsewhere. This is an insertion anomaly.
Deletion Risks: Removing a record might accidentally erase unique information that was stored redundantly within that row. This is a deletion anomaly.
Storage Bloat: Storing the same values repeatedly consumes disk space and memory unnecessarily.
Integrity Loss: Without constraints enforcing uniqueness across redundant fields, the single source of truth becomes fragmented.
In large-scale diagrams, these issues compound. A single table with duplicated foreign keys or descriptive attributes can cause cascading failures during maintenance operations. The goal is to achieve a balance where data integrity is preserved without sacrificing query efficiency.
🔄 Understanding Normalization Principles
Normalization is the process of organizing data to reduce redundancy and improve dependency management. It involves decomposing tables into smaller, well-structured entities. While the theory dates back to the 1970s, the principles remain the backbone of modern schema design.
First Normal Form (1NF)
The first step is ensuring atomicity. Each column must contain indivisible values. Lists within a single cell violate this principle. For example, storing multiple phone numbers in one field requires splitting them into separate rows or related tables.
Second Normal Form (2NF)
Once 1NF is satisfied, we address partial dependencies. A table is in 2NF if it is in 1NF and all non-key attributes are fully dependent on the primary key. In composite keys, attributes should not depend on just part of the key.
Third Normal Form (3NF)
This is the most common standard for general transactional systems. A table is in 3NF if it is in 2NF and has no transitive dependencies. In simpler terms, non-key attributes should not depend on other non-key attributes. If A determines B and B determines C, then A determines C, which is redundant unless B is a key.
Boyce-Codd Normal Form (BCNF)
BCNF is a stricter version of 3NF. It handles cases where there are multiple candidate keys and overlapping dependencies. While not always necessary, it ensures the highest level of logical consistency.
Form | Focus | Key Requirement | Impact on Redundancy |
|---|---|---|---|
1NF | Atomicity | No repeating groups | Basic structure |
2NF | Partial Dependencies | Full dependency on primary key | Reduces split-key redundancy |
3NF | Transitive Dependencies | Non-keys depend only on key | Eliminates attribute duplication |
BCNF | Strict Dependencies | Every determinant is a candidate key | Minimizes complex overlaps |
🏛️ Advanced Structural Patterns for Scale
Standard normalization works well for transactional databases, but large-scale systems often require specific patterns to manage complexity without creating excessive joins.
Associative Entities
Many-to-many relationships are a primary source of redundancy if handled poorly. Instead of adding foreign keys to both related tables, create an associative table. This table contains only the foreign keys and any attributes specific to the relationship itself.
Benefit: Changes to the relationship attributes do not require altering the parent entities.
Benefit: Prevents the duplication of relationship metadata across multiple rows.
Subtyping and Supertypes
When entities share common attributes but have specific variations, using a supertype/subtype pattern reduces attribute duplication. Instead of adding optional columns to a main table that only apply to specific instances, create separate tables for the subtypes linked by a shared primary key.
Benefit: Keeps the main entity table clean.
Benefit: Allows for specific constraints on subtypes without affecting the parent.
Aggregation
Aggregation is used when a relationship has attributes that belong to the relationship rather than the participating entities. In a large-scale ERD, this often appears as a summary or transactional link between two major domains.
🧩 Managing Complexity in Large Models
As the number of entities grows, the diagram itself becomes a liability if not managed correctly. Large-scale ERDs require modularization strategies.
Logical vs. Physical Models
Separate the logical design from the physical implementation. The logical model focuses on entities and relationships without concern for specific storage mechanisms. The physical model handles indexing, partitioning, and data types. Keeping these distinct prevents physical constraints from forcing logical redundancy.
Modular Design
Break the system into functional domains. For example, separate the User Domain from the Billing Domain. Each domain maintains its own internal consistency. Interactions between domains happen through defined interfaces or keys, rather than shared tables.
Handling Historical Data
Storing historical versions of data can create redundancy. Instead of duplicating entire rows, use versioning columns or separate audit tables. This preserves the current state without cluttering the main entity with past iterations.
🛠️ Common Pitfalls in Schema Design
Avoiding redundancy requires vigilance. Common mistakes include:
Over-Normalization: Splitting tables so finely that queries require excessive joins, degrading performance. Sometimes, a controlled amount of redundancy is justified for read-heavy workloads.
Ignoring Functional Dependencies: Failing to identify which attributes depend on which keys leads to hidden duplication.
Mixing Concerns: Placing business logic attributes into the data model. Attributes should describe the data, not the process.
Hardcoded Values: Storing specific status codes or categories as strings instead of referencing a lookup table.
✅ Verification and Validation Checklist
Before finalizing a large-scale ERD, perform a rigorous review. Use this checklist to validate your design.
Identify Primary Keys: Ensure every table has a unique identifier.
Check Foreign Keys: Verify that all relationships are enforced via keys, not by repeating data.
Analyze Attributes: Ask if every non-key attribute depends on the key, the whole key, and nothing but the key.
Review Cardinality: Ensure one-to-many relationships are represented by a single foreign key, not multiple.
Test Data Entry: Simulate inserting, updating, and deleting records to check for anomalies.
🔍 The Role of Constraints
Constraints are the technical enforcement of the design. Unique constraints prevent duplicate values in specific columns. Foreign key constraints ensure referential integrity, preventing orphaned records. In large systems, constraint definitions should be part of the schema definition, not an afterthought.
Additionally, consider check constraints to limit the range of values. This prevents invalid data from entering the system, which reduces the need for error handling code later.
📈 Performance Considerations
There is a trade-off between normalization and performance. Highly normalized schemas require joins to reconstruct data. In read-heavy environments, this can slow down response times. However, adding redundancy to speed up reads can slow down writes due to the need to update multiple locations.
Modern database engines handle joins efficiently. Therefore, the default approach should favor normalization unless profiling data indicates a specific bottleneck. If performance is critical, consider materialized views or read replicas rather than altering the core schema structure.
🔄 Maintaining the Schema Over Time
Database schemas evolve. Requirements change, and new entities emerge. To maintain low redundancy over time:
Version Control: Treat schema definitions as code. Track changes in a repository.
Documentation: Maintain up-to-date documentation describing relationships and dependencies.
Regular Audits: Schedule periodic reviews of the ERD to identify new patterns of redundancy.
By adhering to these principles, you ensure that the data architecture remains scalable. A clean ERD is not just about aesthetics; it is about creating a system that is easier to understand, maintain, and extend as the business grows.
🎯 Final Thoughts on Data Integrity
Reducing redundancy is a continuous process. It requires a deep understanding of how data flows through the system and how relationships interact. By applying normalization rules, utilizing advanced structural patterns, and maintaining strict validation protocols, you build a foundation that supports long-term stability. The effort invested in a clean design pays dividends in reduced maintenance costs and higher data quality.
Focus on the logical relationships first. Let the physical implementation be a reflection of that logic, not a compromise of it. With a disciplined approach to ERD design, redundancy becomes a manageable variable rather than a persistent obstacle.