










Projektowanie wytrzymały struktur danych wymaga równowagi między teoretyczną czystością a praktyczną wydajnością. Przy pracy z złożonymi modelami relacji encji (ERD) ścisłe przestrzeganie zasad normalizacji często powoduje problemy w środowiskach o wysokiej prędkości działania. Ten artykuł omawia strategie denormalizacji skierowane na poprawę wydajności zapytań przy jednoczesnym zachowaniu integralności danych. Przeanalizujemy, kiedy odchodzić od standardowych form i jak bezpiecznie wprowadzać nadmiarowość.
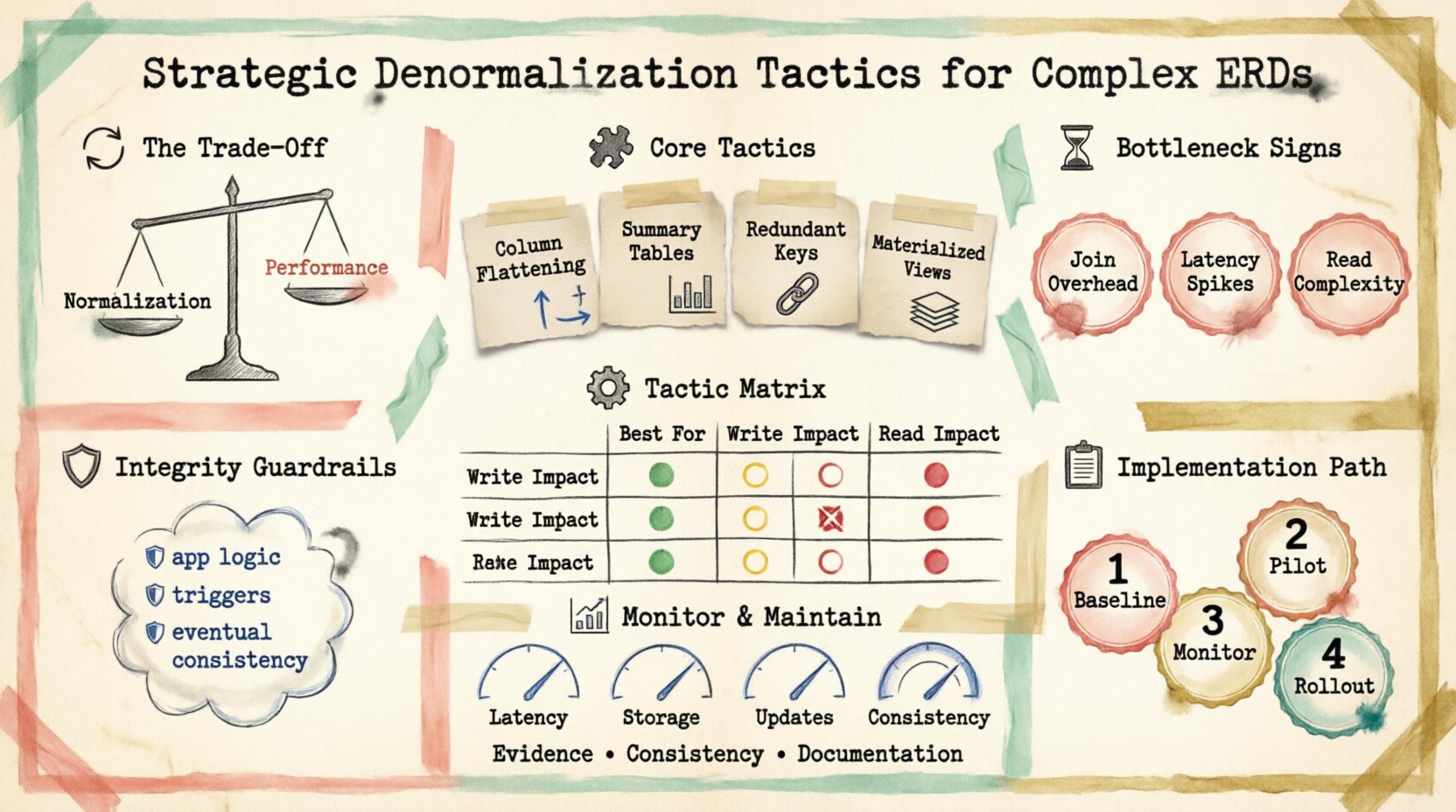
Architekci baz danych często stają przed wyborem między optymalizacją operacji zapisu a operacji odczytu. Normalizacja zmniejsza nadmiarowość, zapewniając spójność danych. Jednak może zwiększać liczbę połączeń wymaganych do pobrania danych, co wpływa na opóźnienia. Denormalizacja ponownie wprowadza nadmiarowość, aby uprościć wzorce dostępu. Ta metoda nie oznacza porzucenia najlepszych praktyk, ale stosowania ich tam, gdzie wymaga tego logika biznesowa.
Koszt ścisłej normalizacji 🔄
W stanie normalizowanym dane są organizowane w oddzielnych tabelach w celu minimalizacji powtórzeń. Ta struktura jest idealna pod kątem wydajności przechowywania i spójności zapisu. Jednak wraz ze wzrostem liczby relacji zwiększa się złożoność pobierania pojedynczego rekordu.
- Nadmiarowe koszty połączeń: Każda operacja połączenia zużywa zasoby CPU i pamięci. Złożone zapytania obejmujące pięć lub więcej tabel mogą stać się węzłami zawieszenia.
- Opóźnienie: Liczba przejść sieciowych rośnie wraz z liczbą zaangażowanych tabel. W systemach rozproszonych to opóźnienie jest nasilone.
- Złożoność odczytu: Logika aplikacji staje się bardziej skomplikowana, ponieważ musi koordynować wiele kroków pobierania danych.
Dla paneli raportujących, analiz czasu rzeczywistego lub interfejsów użytkownika, gdzie szybkość odczytu jest kluczowa, koszt normalizacji może przewyższać jej korzyści. Zrozumienie tej kompromisu jest pierwszym krokiem w strategicznej optymalizacji.
Identyfikacja węzłów zawieszenia wydajności ⏱️
Zanim zmienisz schemat, musisz zidentyfikować konkretne punkty problemowe. Nie każde wolne zapytanie wymaga denormalizacji. Użyj narzędzi profilowania do analizy planów wykonania.
- Wysokie opóźnienie I/O: Wskazuje na nadmierny odczyt dysku, często spowodowany skanowaniem dużych tabel.
- Konflikty blokad: Częste blokady podczas odczytu mogą wskazywać na nadmiernie fragmentowane struktury danych.
- Wolne zapytania agregujące: Obliczenia na wielu tabelach często cierpią z powodu nadmiaru kosztów normalizacji.
Gdy te metryki pojawiają się regularnie, oznacza to możliwość przebudowy struktury danych. Celem jest zmniejszenie obciążenia obliczeniowego silnika bez naruszania źródła prawdy.
Kluczowe podejścia taktyczne 🧩
Istnieje kilka metod wprowadzania nadmiarowości w sposób strategiczny. Wybór zależy od stosunku odczytu do zapisu w Twoim konkretnym obciążeniu.
1. Spłaszczanie kolumn
Obejmuje przeniesienie danych z powiązanych tabel bezpośrednio do głównej tabeli. Na przykład przechowywanie adresu e-mail użytkownika w tabeli zamówienia, zamiast łączenia z tabelą użytkownika za każdym razem, gdy pobierane jest zamówienie.
- Zalety: Usuwa wymóg połączenia dla szczegółów użytkownika.
- Ograniczenia: Dane muszą być aktualizowane za każdym razem, gdy zmienia się profil użytkownika.
2. Tabele podsumowujące
Wstępnie obliczone agregaty mogą znajdować się obok szczegółowych danych transakcyjnych. Jest to powszechne w raportowaniu finansowym lub zarządzaniu zapasami.
- Zalety:Natychmiastowy dostęp do sum, średnich i liczb.
- Ograniczenia:Wymaga mechanizmu utrzymania zgodności agregatów z danymi pierwotnymi.
3. Nadmiarowe klucze obce
Często klucz rodzica jest potrzebny w tabeli potomnej do szybkich wyszukiwań. Dodanie nadmiarowego klucza obcego pozwala na bezpośredni odniesienie bez przeszukiwania hierarchii.
- Zalety:Szybsze przeszukiwanie głębokich hierarchii.
- Ograniczenia: Nieco zwiększa zużycie pamięci i wymaga sprawdzania spójności.
Macierz porównawcza strategii
| Strategia | Najlepsze dla | Wpływ na zapis | Wpływ na odczyt |
|---|---|---|---|
| Spłaszczenie kolumn | Zapytania z dużą ilością wyszukiwań | Średnio | Niski |
| Tabele podsumowujące | Raportowanie i analizy | Wysoki | Bardzo niski |
| Nadmiarowe klucze | Głębokie hierarchie | Niski | Niski |
| Widoki materializowane | Złożone łączenia | Średni | Niski |
Zarządzanie integralnością danych 🛡️
Wprowadzanie nadmiarowości stwarza ryzyko rozbieżności danych. Jeśli dane źródłowe ulegną zmianie, a kopie nadmiarowe nie, system staje się niepewny. Jest to główne wyzwanie denormalizacji.
- Logika na poziomie aplikacji: Upewnij się, że kod aktualizuje wszystkie kopie danych w ramach jednej transakcji.
- Wyzwalacze:Wyzwalacze bazy danych mogą automatyzować aktualizacje pól nadmiarowych, gdy zmieniają się tabele źródłowe.
- Końcowa spójność: W niektórych systemach niewielkie opóźnienia między aktualizacjami są akceptowalne. Zmniejsza to obciążenie, ale wymaga od aplikacji obsługiwania przestarzałych danych zgodnie z zasadami.
Zasady walidacji są kluczowe. Okresowe audyty powinny porównywać dane źródłowe z kopiami nadmiarowymi w celu wykrycia rozbieżności. Jeśli zostanie wykryta różnica, powinien uruchomić się skrypt korekcyjny w celu przywrócenia spójności.
Strategia wdrożenia 📋
Nie przekształcaj całej bazy danych naraz. Zastosuj podejście etapowe, aby zmniejszyć ryzyko.
- Pomiar podstawowy: Zapisz bieżące czasy zapytań i zużycie zasobów.
- Pilot denormalizacji: Wybierz jedno zapytanie o dużym wpływie i je zoptymalizuj.
- Monitorowanie: Śledź poprawy wydajności oraz błędy spójności danych.
- Wdrożenie: Rozszerz ten wzorzec na inne obszary o dużym obciążeniu.
Dokumentacja jest kluczowa. Jasno oznacz, które tabele są denormalizowane i dlaczego. Przyszli programiści muszą zrozumieć kompromisy dokonane w projektowaniu schematu.
Monitorowanie metryk wydajności 📊
Po aktywacji denormalizacji ciągłe monitorowanie zapewnia, że strategia pozostaje skuteczna.
- Opóźnienie zapytania: Monitoruj wzrosty, które mogą wskazywać na zawieranie blokad na aktualizowanych tabelach.
- Wzrost zużycia pamięci: Dane nadmiarowe zużywają więcej miejsca. Planuj pojemność odpowiednio.
- Częstotliwość aktualizacji:Wysokie obciążenie zapisu na tabelach denormalizowanych może pogorszyć wydajność.
- Błędy spójności:Zapisz wszelkie błędy w procesie synchronizacji.
Powinny być skonfigurowane alerty dla anomalii. Jeśli określona tabela rośnie szybciej niż przewidziano, może to wskazywać na błąd logiki podczas replikacji danych.
Protokoły konserwacji 🔧
Utrzymanie schematu znormalizowanego wymaga dyscypliny. Nie jest to konfiguracja typu „ustaw i zapomnij”.
- Wersjonowanie schematu:Traktuj zmiany schematu jak kod. Regularnie przeglądaj skrypty migracji.
- Procedury czyszczenia:Usuń nadmiarowe dane, które już nie są potrzebne, aby oszczędzić miejsce.
- Częstotliwość przeglądu:Przeprowadzaj ponowną ocenę potrzeby znormalizowania, gdy zmieniają się wymagania biznesowe.
Czasem początkowa optymalizacja nie jest już potrzebna, jeśli objętość danych spadnie lub zmienią się wzorce dostępu. Regularne przeglądy zapobiegają gromadzeniu długu technicznego.
Strategiczna częstotliwość przeglądu 🔄
Projekt bazy danych nie jest statyczny. To, co działa dziś, może nie działać jutro. Zaprojektuj kwartalne przeglądy modelu relacji encji.
- Analiza obciążenia:Czy zmieniła się proporcja odczytów do zapisów?
- Aktualizacje sprzętu:Nowa technologia przechowywania może zmienić koszt łączeń.
- Cele biznesowe:Nowe funkcje mogą wymagać innych struktur danych.
Elastyczność jest kluczowa. Przygotuj się na ponowne znormalizowanie, jeśli koszt utrzymania nadmiarowości przekracza zyski w zakresie wydajności. Celem jest zawsze optymalne zachowanie systemu, a nie ślepe przestrzeganie konkretnego dogmatu projektowego.
Ostateczne rozważania nad ewolucją schematu 📝
Znormalizowanie to potężny narzędzie w arsenale architekta bazy danych. Rozwiązuje rzeczywiste problemy wydajności, które modele teoretyczne czasem pomijają. Stosując te metody systematycznie, możesz budować systemy, które są zarówno szybkie, jak i niezawodne.
- Skup się na dowodach:Podstaw decyzje na metrykach, a nie założeniach.
- Priorytetem jest spójność:Upewnij się, że dane pozostają dokładne na wszystkich poziomach.
- Dokumentuj decyzje:Zachowaj zapis, dlaczego konkretne tabele zostały zmienione.
Przy starannym planowaniu i ciągłym utrzymaniu złożone modele relacji encji mogą zapewnić wydajność wymaganą przez nowoczesne aplikacje. Droga do efektywności jest iteracyjna i wymaga nieustannego uwagi na równowagę między strukturą a prędkością.