









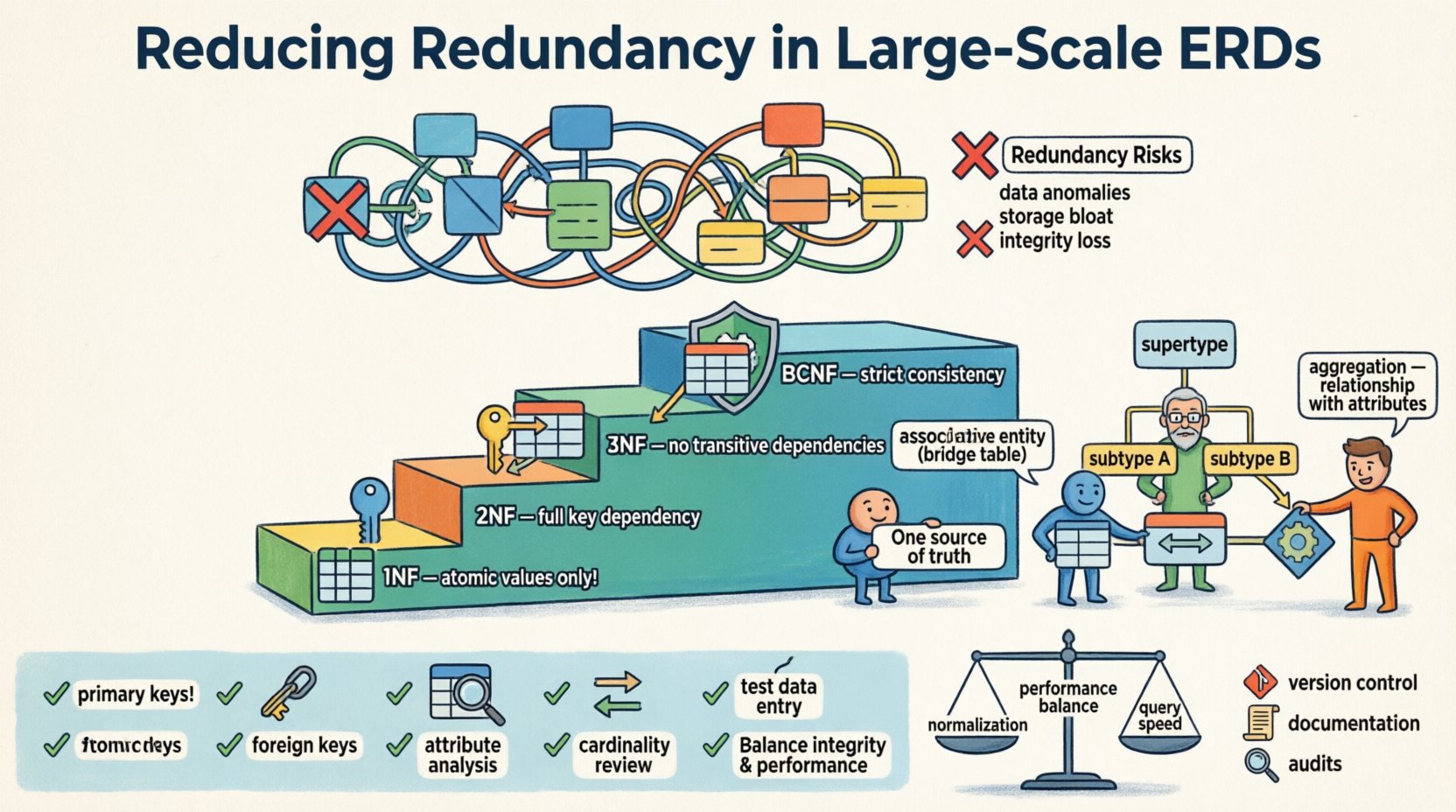
W architekturze odpornych systemów danych diagram relacji encji (ERD) pełni rolę podstawowego projektu. Wraz z rosnącą złożonością systemów i wzrostem objętości danych utrzymanie czystego schematu staje się kluczowe. Nadmiarowość w dużym diagramie ERD to nie tylko marnotrawstwo pamięci; jest źródłem niestabilności systemowej. Gdy identyczne punkty danych są przechowywane w wielu miejscach bez mechanizmu synchronizacji, ryzyko niezgodności danych znacznie wzrasta.
Ten przewodnik omawia strategie techniczne wymagane do minimalizacji nadmiarowości przy jednoczesnym zachowaniu elastyczności potrzebnej dla aplikacji o dużym obciążeniu. Przeanalizujemy zasady normalizacji, wzorce strukturalne oraz metody weryfikacji, aby zapewnić, że Twój model danych pozostanie stabilny w czasie.
📉 Koszt duplikacji w modelach danych
Nadmiarowość występuje, gdy ta sama część danych jest przechowywana więcej niż raz w schemacie bazy danych. Choć pewna denormalizacja jest dopuszczalna w celu optymalizacji wydajności, niekontrolowana duplikacja wprowadza kilka ryzyk, które w środowiskach o dużym zasięgu znacznie się nasilają.
-
Anomalie danych: Aktualizacja informacji w jednym miejscu, ale nie w drugim, prowadzi do sprzecznych rekordów. Nazywa się to anomaliami aktualizacji.
-
Problemy z wstawianiem: Czasem nie możesz dodać nowych danych, ponieważ informacje powiązane są niepełne w innych miejscach. Jest to anomalia wstawiania.
-
Ryzyko usunięcia: Usunięcie rekordu może przypadkowo usunąć unikalne informacje, które były przechowywane nadmiarowo w tym wierszu. Jest to anomalia usuwania.
-
Zaburzenia pamięci: Powtarzane przechowywanie tych samych wartości zużywa niepotrzebnie miejsce na dysku i pamięć operacyjną.
-
Strata integralności: Bez ograniczeń zapewniających unikalność w nadmiarowych polach, pojedynczy źródło prawdy staje się rozdrobnione.
W dużych diagramach te problemy się nasilają. Jedna tabela z powielonymi kluczami obcymi lub atrybutami opisowymi może powodować kaskadowe awarie podczas operacji konserwacyjnych. Celem jest osiągnięcie równowagi, w której zachowana jest integralność danych bez utraty wydajności zapytań.
🔄 Zrozumienie zasad normalizacji
Normalizacja to proces organizacji danych w celu zmniejszenia nadmiarowości i poprawy zarządzania zależnościami. Polega na rozkładaniu tabel na mniejsze, dobrze zorganizowane jednostki. Choć teoria sięga lat 70., zasady te nadal stanowią fundament projektowania nowoczesnych schematów.
Pierwsza postać normalna (1NF)
Pierwszym krokiem jest zapewnienie atomowości. Każda kolumna musi zawierać niepodzielne wartości. Listy w jednym polu narusza tę zasadę. Na przykład przechowywanie wielu numerów telefonu w jednym polu wymaga ich podziału na osobne wiersze lub powiązane tabele.
Druga postać normalna (2NF)
Po spełnieniu 1NF zajmujemy się zależnościami częściowymi. Tabela znajduje się w 2NF, jeśli jest w 1NF i wszystkie atrybuty niekluczowe są całkowicie zależne od klucza głównego. W kluczach złożonych atrybuty nie powinny zależeć tylko od części klucza.
Trzecia postać normalna (3NF)
Jest to najpowszechniejszy standard dla ogólnych systemów transakcyjnych. Tabela znajduje się w 3NF, jeśli jest w 2NF i nie ma zależności przechodnich. Innymi słowy, atrybuty niekluczowe nie powinny zależeć od innych atrybutów niekluczowych. Jeśli A decyduje o B i B decyduje o C, to A decyduje o C, co jest nadmiarowe, chyba że B to klucz.
Postać normalna Boyce’a-Codda (BCNF)
BCNF to bardziej rygorystyczna wersja 3NF. Obsługuje przypadki, gdy istnieje wiele kluczy kandydujących i zachodzące zależności. Choć nie zawsze jest konieczna, zapewnia najwyższy poziom spójności logicznej.
|
Forma |
Skupienie |
Kluczowe wymagania |
Wpływ na nadmiarowość |
|---|---|---|---|
|
1NF |
Atomowość |
Brak powtarzających się grup |
Podstawowa struktura |
|
2NF |
Zależności częściowe |
Pełna zależność od klucza podstawowego |
Zmniejsza nadmiarowość spowodowaną rozdzielonymi kluczami |
|
3NF |
Zależności przechodnie |
Niekluczowe atrybuty zależą wyłącznie od klucza |
Usunie powtarzanie atrybutów |
|
BCNF |
Ścisłe zależności |
Każdy wyznacznik jest kluczem kandydującym |
Minimalizuje złożone nakładania się |
🏛️ Zaawansowane wzorce strukturalne do skalowania
Standardowa normalizacja działa dobrze w bazach danych transakcyjnych, ale systemy o dużym zasięgu często wymagają określonych wzorców, aby zarządzać złożonością bez nadmiernego tworzenia połączeń.
Encje pośredniczące
Relacje wiele do wielu są głównym źródłem nadmiarowości, jeśli są źle obsługiwane. Zamiast dodawać klucze obce do obu powiązanych tabel, utwórz tabelę pośrednią. Ta tabela zawiera wyłącznie klucze obce oraz atrybuty specyficzne dla samej relacji.
-
Zalety:Zmiany w atrybutach relacji nie wymagają modyfikacji encji nadrzędnych.
-
Zalety:Zapobiega powielaniu metadanych relacji w wielu wierszach.
Podtypy i nadtypy
Gdy encje współdzielą wspólne atrybuty, ale mają konkretne różnice, stosowanie wzorca nadtypu/podtypu zmniejsza powielanie atrybutów. Zamiast dodawać opcjonalne kolumny do głównej tabeli, które mają zastosowanie tylko do konkretnych przypadków, utwórz osobne tabele dla podtypów połączone wspólnym kluczem głównym.
-
Zalety:Utrzymuje główną tabelę encji w porządku.
-
Zalety:Umożliwia określone ograniczenia dla podtypów bez wpływu na rodzica.
Agregacja
Agregacja stosowana jest wtedy, gdy relacja ma atrybuty należące do samej relacji, a nie do uczestniczących encji. W dużych modelach ERD często pojawia się jako podsumowanie lub łącze transakcyjne między dwoma głównymi domenami.
🧩 Zarządzanie złożonością w dużych modelach
Wraz ze wzrostem liczby encji, sama diagram staje się obciążeniem, jeśli nie jest odpowiednio zarządzana. Duże modele ERD wymagają strategii modularizacji.
Modele logiczne vs. fizyczne
Oddziel projektowanie logiczne od implementacji fizycznej. Model logiczny skupia się na encjach i relacjach, nie dbając o konkretne mechanizmy przechowywania danych. Model fizyczny zajmuje się indeksowaniem, partycjonowaniem i typami danych. Oddzielenie ich zapobiega sytuacji, gdy ograniczenia fizyczne wymuszają nadmiarowość logiczną.
Projektowanie modułowe
Podziel system na domeny funkcjonalne. Na przykład oddziel domenę Użytkownika od domeny Fakturacji. Każda domena utrzymuje własną spójność wewnętrzna. Wzajemne interakcje między domenami zachodzą poprzez zdefiniowane interfejsy lub klucze, a nie wspólne tabele.
Obsługa danych historycznych
Przechowywanie wersji historycznych danych może powodować nadmiarowość. Zamiast powielać całe wiersze, użyj kolumn wersjonowania lub osobnych tabel audytu. Pozwala to zachować stan aktualny bez zanieczyszczenia głównej encji poprzednimi wersjami.
🛠️ Powszechne pułapki w projektowaniu schematu
Unikanie nadmiarowości wymaga ostrożności. Powszechne błędy obejmują:
-
Zbyt duża normalizacja:Dzielenie tabel na zbyt małe fragmenty, co powoduje konieczność nadmiernych połączeń w zapytaniach i pogarsza wydajność. Czasem niewielka, kontrolowana ilość nadmiarowości jest uzasadniona dla obciążeń o wysokim obciążeniu odczytu.
-
Ignorowanie zależności funkcyjnych:Niezdolność do identyfikacji, które atrybuty zależą od których kluczy, prowadzi do ukrytej nadmiarowości.
-
Mieszanie zagadnień:Umieszczanie atrybutów logiki biznesowej w modelu danych. Atrybuty powinny opisywać dane, a nie proces.
-
Wartości zakodowane w kodzie:Przechowywanie konkretnych kodów stanu lub kategorii jako ciągów znaków zamiast odwoływania się do tabeli słownikowej.
✅ Lista kontrolna weryfikacji i walidacji
Zanim zakończysz projektowanie dużego modelu ERD, wykonaj szczegółową analizę. Użyj tej listy kontrolnej do weryfikacji swojego projektu.
-
Zidentyfikuj klucze podstawowe: Upewnij się, że każda tabela ma unikalny identyfikator.
-
Sprawdź klucze obce: Upewnij się, że wszystkie relacje są wymuszane za pomocą kluczy, a nie poprzez powtarzanie danych.
-
Analizuj atrybuty: Zapytaj, czy każdy atrybut niekluczowy zależy od klucza, całego klucza i niczego innego poza kluczem.
-
Przejrzyj liczność: Upewnij się, że relacje jeden do wielu są reprezentowane przez pojedynczy klucz obcy, a nie przez wiele.
-
Przetestuj wprowadzanie danych: Symuluj wstawianie, aktualizację i usuwanie rekordów w celu sprawdzenia obecności anomalii.
🔍 Rola ograniczeń
Ograniczenia to techniczne zapewnienie poprawności projektu. Ograniczenia unikalności zapobiegają powtarzaniu się wartości w określonych kolumnach. Ograniczenia kluczy obcych zapewniają integralność referencyjną, uniemożliwiając istnienie zaniedbanych rekordów. W dużych systemach definicje ograniczeń powinny być częścią definicji schematu, a nie postrzegane jako pochodne.
Dodatkowo rozważ ograniczenia sprawdzające, aby ograniczyć zakres wartości. Zapobiega to wprowadzaniu nieprawidłowych danych do systemu, co zmniejsza potrzebę kodu obsługującego błędy w przyszłości.
📈 Względy dotyczące wydajności
Istnieje kompromis między normalizacją a wydajnością. Wysoko znormalizowane schematy wymagają łączeń w celu odtworzenia danych. W środowiskach o dużym obciążeniu odczytu może to spowolnić czas odpowiedzi. Jednak dodanie nadmiarowości w celu przyspieszenia odczytów może spowolnić zapisy ze względu na konieczność aktualizacji wielu lokalizacji.
Nowoczesne silniki baz danych efektywnie obsługują łączenia. Dlatego domyślna strategia powinna sprzyjać normalizacji, chyba że profilowanie danych wskazuje na konkretny węzeł zatyczki. Jeśli wydajność jest krytyczna, rozważ użycie widoków materializowanych lub replik odczytu zamiast modyfikowania struktury jądra schematu.
🔄 Utrzymanie schematu w czasie
Schematy baz danych ewoluują. Wymagania się zmieniają, a nowe encje pojawiają się. Aby utrzymać niską nadmiarowość w czasie:
-
Kontrola wersji:Traktuj definicje schematu jak kod. Śledź zmiany w repozytorium.
-
Dokumentacja:Utrzymuj aktualną dokumentację opisującą relacje i zależności.
-
Regularne audyty:Zaplanuj okresowe przeglądy diagramu ERD w celu wykrycia nowych wzorców nadmiarowości.
Przestrzegając tych zasad, zapewnisz, że architektura danych pozostaje skalowalna. Czysty diagram ERD nie dotyczy tylko estetyki; dotyczy tworzenia systemu, który jest łatwiejszy do zrozumienia, utrzymania i rozszerzania wraz z rozwojem firmy.
🎯 Ostateczne rozważania na temat integralności danych
Zmniejszanie nadmiarowości to ciągły proces. Wymaga głębokiego zrozumienia, jak dane przepływają przez system oraz jak wzajemnie się oddziałują relacje. Przykładając zasady normalizacji, wykorzystując zaawansowane wzorce strukturalne i utrzymując surowe protokoły weryfikacji, budujesz fundament wspierający długoterminową stabilność. Wkład w czysty projekt przynosi korzyści w postaci zmniejszonych kosztów utrzymania i wyższej jakości danych.
Skup się najpierw na relacjach logicznych. Niech fizyczna realizacja będzie odbiciem tej logiki, a nie jej kompromisem. Przy dyscyplinowanym podejściu do projektowania diagramu ERD nadmiarowość staje się zmienną, którą można zarządzać, a nie stałą przeszkodą.