











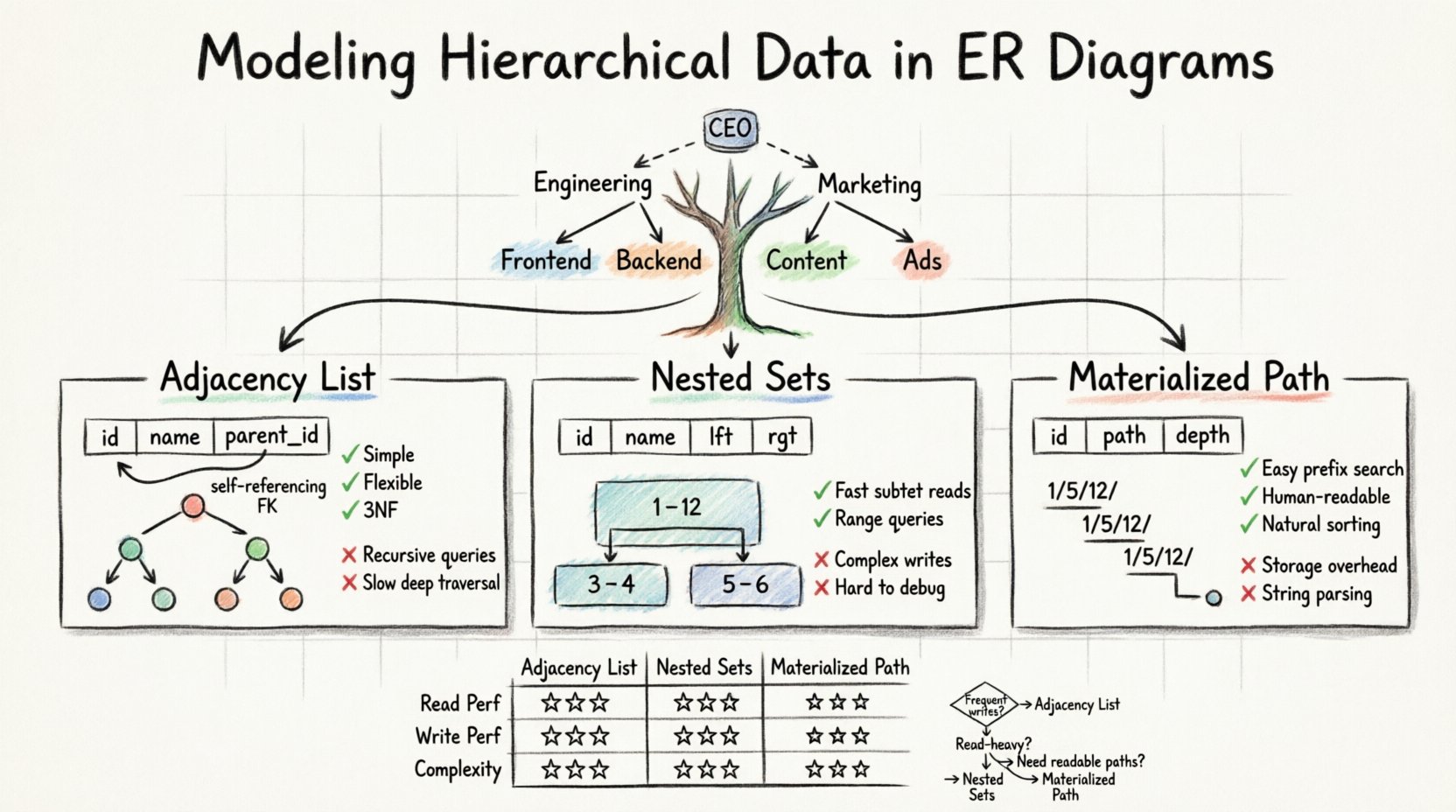
Bazy danych relacyjnych opierają się na strukturze tabel i wierszy, przeznaczonej dla danych płaskich. Jednak w świecie rzeczywistym rzadko spotyka się taką prostotę. Organizacje, systemy plików, wątki komentarzy i drzewa kategorii wszystkie istnieją w strukturach hierarchicznych. Przedstawienie tych relacji rodzic-dziecko w standardowym diagramie związków encji (ERD) wymaga określonych wzorców projektowych, które zapewniają integralność danych, jednocześnie umożliwiając skuteczne pobieranie.
Gdy próbujesz odwzorować strukturę drzewa na płaskiej schemacie, napotykasz klasyczny konflikt między normalizacją a wydajnością. Ten przewodnik bada podstawowe techniki modelowania danych hierarchicznych, oceniając zalety i wady każdej metody, aby pomóc Ci projektować wytrzymałe systemy.
🧩 Wyzwanie płaskich schematów
Diagram związków encji zwykle wizualizuje encje jako prostokąty, a relacje jako linie. W standardowej relacji jedna tabela łączy się z drugą za pomocą klucza obcego. Działa to idealnie w przypadku relacji wiele-do-wielu lub jedno-do-wielu, gdzie kierunek jest ustalony. Ale co się dzieje, gdy kategoria może mieć podkategorie, które z kolei mogą mieć podpodkategorie, potencjalnie nieskończenie?
Standardowe modele relacyjne mają trudności z zmienną głębokością. Płaska tabela nie może łatwo przechowywać ścieżki dowolnej długości. Aby rozwiązać ten problem, musimy dostosować schemat w taki sposób, aby hierarchia była przechowywana jawnie. Istnieją trzy główne wzorce wykorzystywane przez architektów danych, aby to osiągnąć:
- Lista sąsiedztwa: Przechowywanie identyfikatora rodzica w rekordzie dziecka.
- Zbiory zagnieżdżone: Przypisywanie wartości lewej i prawej, aby zdefiniować zakresy.
- Wypisywanie ścieżki: Przechowywanie pełnej ścieżki od korzenia do bieżącego węzła.
🔗 Model listy sąsiedztwa
Lista sąsiedztwa to najpowszechniejsza i najprostsza metoda przedstawiania hierarchii w standardowym diagramie ERD. Opiera się na relacji samodzielnej. Oznacza to, że jedna tabela zawiera kolumnę, która odwołuje się do własnego klucza podstawowego.
📐 Struktura schematu
W tym modelu tworzysz jedną tabelę do przechowywania danych. Każdy wiersz reprezentuje węzeł w drzewie. Kluczowym uzupełnieniem jest kolumna, często nazwanaparent_idlubancestor_id, która przechowuje unikalny identyfikator węzła rodzica. Jeśli węzeł znajduje się na szczycie hierarchii, ta kolumna zawiera wartość null.
Rozważ tabelę dlaDepartment:
- id: Unikalny klucz podstawowy dla departamentu.
- nazwa: Nazwa wyświetlana departamentu.
- parent_id: Identyfikator wyższej jednostki organizacyjnej (może być pusty dla najwyższego poziomu).
✅ Zalety
- Prostota: Schemat jest intuicyjny i łatwy do zrozumienia dla programistów i administratorów baz danych.
- Elastyczność: Przenoszenie poddrzewa jest proste; wystarczy zaktualizować
parent_idkorzenia tego poddrzewa. - Normalizacja: Dobre przestrzega Trzeciej Postaci Normalnej (3NF), ponieważ dane nie są powtarzane.
❌ Wady
- Złożoność zapytań: Pobieranie wszystkich potomków wymaga zapytań rekurencyjnych lub przetwarzania po stronie aplikacji.
- Wydajność: Głębokie przeszukiwania mogą być wolne bez specjalnych strategii indeksowania lub rekurencyjnych wyrażeń tabel wspólnych (CTEs).
- Integralność referencyjna: Choć klucze obce pomagają, cykliczne odwołania mogą nadal występować, jeśli ograniczenia nie są ściśle stosowane.
🌲 Model Zestawu Zagnieżdżonego
Model Zestawu Zagnieżdżonego przekształca strukturę drzewa w zbiór przedziałów. Zamiast śledzić wskaźniki rodzica, każdemu węzłowi przypisuje się dwie liczby: left i right. Te wartości reprezentują pozycję węzła w przejściu w porządku pre-order drzewa.
📐 Struktura schematu
Wyobraź sobie drzewo, w którym korzeń to całość zbioru. Podczas przeszukiwania drzewa zwiększaj licznik. Gdy wejdziesz do węzła, zapisz aktualną wartość licznika jako left. Gdy skończysz przetwarzać ten węzeł i wszystkie jego dzieci, zapisz liczbę jako right. The right wartość jest zawsze większa niż lewa wartość.
Pojedynczy Kategoria tabela wyglądałaby następująco:
- id: Unikalny identyfikator.
- nazwa: Nazwa kategorii.
- lft: Wartość lewej granicy.
- rgt: Wartość prawej granicy.
✅ Zalety
- Szybkie pobieranie: Pobieranie poddrzewa to proste zapytanie zakresowe używające
MIĘDZYlogiki. - Efektywność: Wydajność odczytu jest lepsza dla dużych, głębokich drzew w porównaniu do list sąsiedztwa.
❌ Wady
- Koszt zapisu: Wstawianie lub przemieszczanie węzła jest kosztowne. Musisz zaktualizować wartości
lftorazrgtwielu innych węzłów, aby zachować integralność przedziałów. - Złożoność: Logika jest trudna do zaimplementowania i zdebugowania bez wsparcia specjalistycznej biblioteki.
🛣️ Wypisywanie ścieżek i zmaterializowane ścieżki
Metody wypisywania ścieżek przechowują pochodzenie węzła jako ciąg znaków lub listę rozdzieloną znakami. Ten podejście często nazywa się wzorcem zmaterializowanej ścieżki. Łączy prostotę listy sąsiedztwa z czytelnością ścieżki.
📐 Struktura schematu
W tym modelu każdy rekord przechowuje pełną ścieżkę od korzenia. Na przykład, w modelu systemu plików plik może mieć ciąg ścieżki takiej jak/home/user/documents/report.txt. W bazie danych często przechowywane jest jako ciąg rozdzielony znakami w kolumnie, tak jak1/5/12/.
Tabela zawiera:
- id: Klucz podstawowy.
- ścieżka: Ciąg znaków reprezentujący pochodzenie.
- głębokość: Liczba całkowita wskazująca, na jakiej głębokości znajduje się węzeł.
✅ Zalety
- Łatwe przeszukiwanie: Możesz znaleźć wszystkie potomki, dopasowując prefiks ścieżki.
- Czytelność: Dane są czytelne dla człowieka i łatwe do debugowania.
- Sortowanie: Sortowanie według ciągu ścieżki często daje poprawną kolejność drzewa naturalnie.
❌ Wady
- Nadmiarowe zużycie pamięci: Długie ścieżki mogą zużywać znaczne miejsce w pamięci.
- Analiza ciągów: Zapytania często wymagają funkcji przetwarzania ciągów, które mogą być wolniejsze niż porównania liczb całkowitych.
📊 Analiza porównawcza
Wybór odpowiedniego modelu zależy w dużej mierze od stosunku odczytu do zapisu oraz głębi hierarchii. Poniższa tabela przedstawia cechy każdego z metod.
| Cecha | Lista sąsiedztwa | Zestawy zagnieżdżone | Ścieżka materializowana |
|---|---|---|---|
| Wydajność odczytu | Niska do średniej | Wysoka | Średnia do wysokiej |
| Wydajność zapisu | Wysoka | Niska | Średnia |
| Złożoność implementacji | Niska | Wysoka | Średnia |
| Obsługuje głębokie drzewa | Tak | Tak | Tak (z ograniczeniami) |
| Logika zapytań | Rekurencyjna | Skany zakresu | Dopasowanie prefiksu |
⚙️ Uwagi dotyczące wydajności
Podczas modelowania hierarchii należy wziąć pod uwagę, jak silnik bazy danych obsługuje dane. Strategie indeksowania odgrywają kluczową rolę niezależnie od wybranej modelu.
- Lista sąsiedztwa: Indeksuj
parent_idkolumnę intensywnie. Pozwala to bazie danych szybko znaleźć wszystkie dzieci określonego węzła bez przeszukiwania całej tabeli. - Zestawy zagnieżdżone: Indeksuj oba
lftirgt. Indeksy złożone mogą znacznie zoptymalizować zapytania zakresowe. - Ścieżka materializowana: Indeksuj kolumnę
pathkolumnę. W zależności od bazy danych, indeks prefiksowy może być korzystny do filtrowania poddrzew.
🛠️ Konserwacja i aktualizacje
Modele danych nie są statyczne. Wraz z rozwojem organizacji hierarchia będzie się zmieniać. Przenoszenie węzła z jednej gałęzi do drugiej to powszechna operacja, która różnie wpływa na każdy model.
🔄 Przenoszenie węzłów
W modelu Listy sąsiedztwa, przenoszenie węzła to pojedyncze zapytanie aktualizujące. Zmieniasz parent_id korzenia poddrzewa. Jednak musisz upewnić się, że nie powstają cykliczne odwołania.
W modelu Zestaw zagnieżdżony model, przenoszenie węzła jest skomplikowane. Wymaga ponownego obliczania wartości lft i rgt dla wszystkich węzłów w poddrzewie docelowym, aby stworzyć miejsce dla przenoszonego węzła. Jest to często operacja transakcyjna wymagająca wielu aktualizacji tabel.
W modelu Ścieżka materializowana model, aktualizujesz ciąg ścieżki przenoszonego węzła i wszystkich jego potomków. Wymaga to aktualizacji ścieżki dla każdego dziecka, co może być ciężką operacją zapisu dla dużych drzew.
🎯 Najlepsze praktyki modelowania danych
Aby zapewnić, że twój ERD pozostaje łatwy do utrzymania i wydajny, postępuj zgodnie z tymi zasadami podczas implementacji struktur hierarchicznych.
- Używaj jasnych konwencji nazewnictwa: Unikaj ogólnych nazw takich jak
col1. Użyjparent_id,ancestor_id,lft, lubrgtjawnie. - Wymuszaj ograniczenia: Użyj ograniczeń bazy danych, aby zapobiec cyklicznym odniesieniom. Węzeł nie może być swoim własnym przodkiem.
- Ogranicz głębokość: Choć technicznie możliwe, bardzo głębokie hierarchie (np. więcej niż 10 poziomów) często wskazują na błąd projektowy. Rozważ spłaszczenie struktury, jeśli to możliwe.
- Zadokumentuj wybór: Ponieważ te wzorce nie są standardowymi funkcjami SQL, zadokumentuj, który wzorzec jest używany w dokumentacji schematu.
- Rozważ podejścia hybrydowe: Niektóre systemy łączą listy sąsiedztwa z drogami materializowanymi, aby zrównoważyć wydajność odczytu i zapisu.
🧠 Wybieranie odpowiedniej strategii
Nie ma jednej „poprawnej” odpowiedzi dla każdego scenariusza. Decyzja zależy od konkretnych wymagań Twojej aplikacji.
- Wybierz listę sąsiedztwa, jeśli: Twoje dane często się zmieniają, a głębokość hierarchii jest umiarkowana. Jest to najbezpieczniejsza domyślna opcja dla większości ogólnych aplikacji.
- Wybierz zbiory zagnieżdżone, jeśli: Masz aplikację z dużym obciążeniem odczytu, gdzie dane rzadko się przemieszczają, a potrzebujesz szybko pobierać duże poddrzewa.
- Wybierz drogę materializowaną, jeśli: Potrzebujesz czytelnych dla ludzi ścieżek (np. adresów URL) i głębokość hierarchii jest stosunkowo mała.
Zrozumienie tych szczegółów strukturalnych pozwala projektować bazy danych, które skalują się. Wybierając odpowiedni wzorzec dla diagramu relacji encji, zapewnicasz, że Twoje dane pozostaną spójne, dostępne i wydajne przez cały cykl życia systemu.