










Wydajność bazy danych często zależy od czynników niewidocznych dla przypadkowego obserwatora. Jednym z takich kluczowych czynników jest konkurencja blokad. Gdy wiele użytkowników lub procesów próbuje uzyskać dostęp do tych samych danych jednocześnie, system musi stosować zasady zapobiegające naruszeniu integralności danych. Te zasady prowadzą do blokad. Nadmierna liczba blokad powoduje węzły zatyczki, spowalnia reakcje systemu i frustruje końcowych użytkowników. Prawdopodobną przyczyną jest często nie sprzęt, lecz diagram relacji encji (ERD), który definiuje strukturę danych.
Dobrze zaprojektowana schematika stanowi fundament wysokiej współbieżności. Przewidując sposób dostępu do danych i ich modyfikacji, architekci mogą strukturyzować tabele w taki sposób, aby minimalizować konflikty. Ten podejście wymaga głębokiego zrozumienia izolacji transakcji, strategii indeksowania oraz fizycznych mechanizmów blokowania. Poniższy przewodnik szczegółowo opisuje, jak zoptymalizować model danych pod kątem lepszej wydajności bez korzystania z narzędzi zewnętrznych.
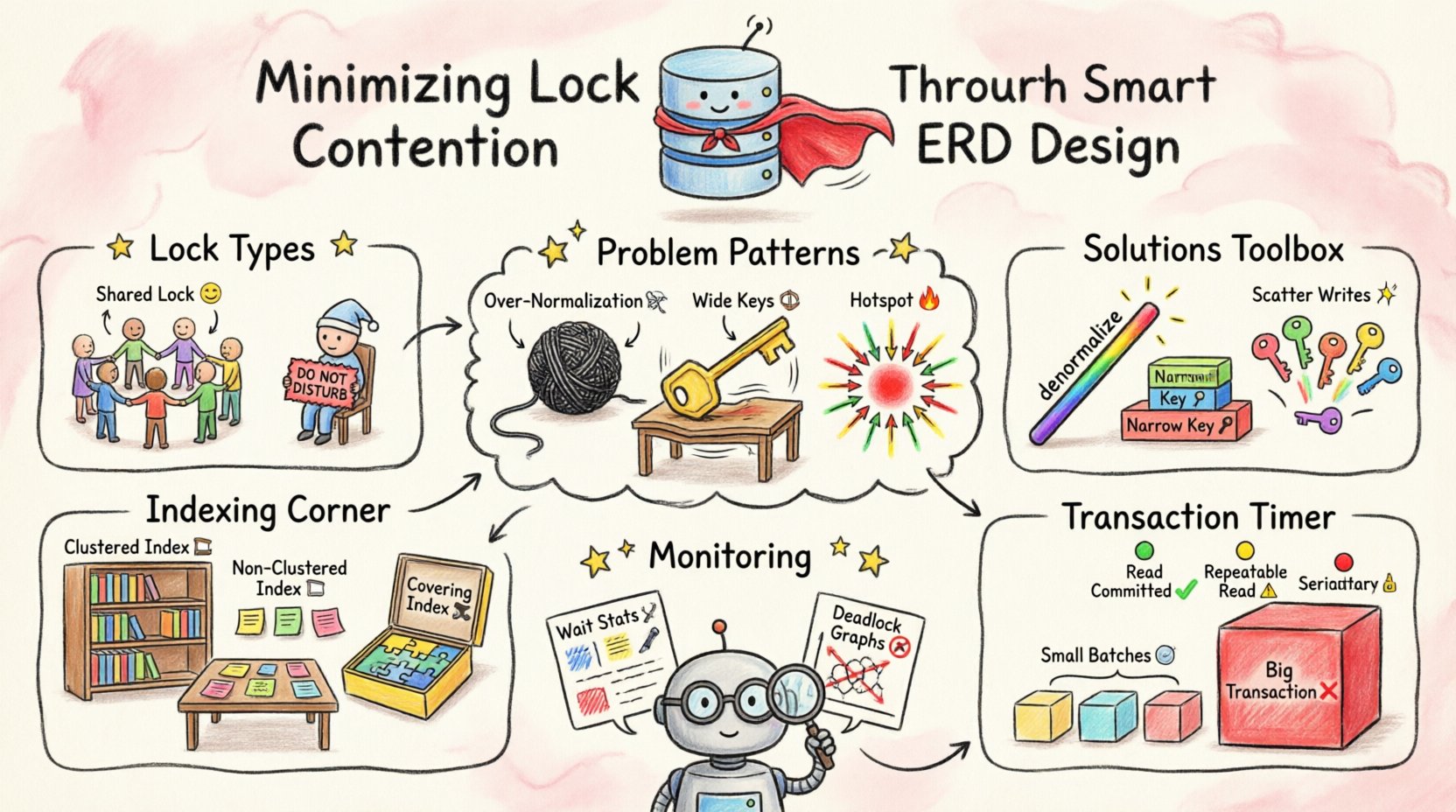
Zrozumienie mechanizmów blokowania 🛡️
Zanim zoptymalizujesz projekt, konieczne jest zrozumienie, co dokładnie robią blokady. Bazy danych używają blokad, aby zapobiegać niezgodnościom. Jeśli dwie transakcje próbują aktualizować tę samą wiersz w dokładnie tym samym momencie, występuje konflikt. System musi zdecydować, kto ma pierwszeństwo.
- Blokady współdzielone (S):Używane do odczytu danych. Wiele transakcji może jednocześnie posiadać blokady współdzielone na tym samym zasobie.
- Blokady wyłączne (X):Używane do zapisu lub modyfikacji danych. W każdym momencie tylko jedna transakcja może posiadać blokadę wyłączną na zasobie.
- Blokady intencji:Wskazują, że transakcja zamierza ustawić blokadę na niższym poziomie hierarchii, na przykład na tabeli lub stronie.
Konkurencja blokad pojawia się, gdy zapotrzebowanie na blokady wyłączne przekracza pojemność dostępu współdzielonego. Jeśli Twój ERD zmusza bazę danych do przeszukiwania dużych fragmentów tabeli w celu znalezienia danych, zwiększa się zakres blokad utrzymywanych. To zwiększa prawdopodobieństwo kolizji między równoległymi procesami.
Wzorce schematu wywołujące konkurencję 📉
Niektóre wybory projektowe w sposób naturalny zwiększają obszar blokowania. Rozpoznawanie tych wzorców pozwala na przeprojektowanie już na wczesnym etapie cyklu rozwoju.
1. Nadmierna normalizacja
Choć normalizacja zmniejsza nadmiarowość, nadmierna normalizacja może pogorszyć wydajność. Łączenie wielu tabel w celu pobrania pojedynczego rekordu wymaga blokowania wielu wierszy w wielu tabelach. Jeśli transakcja musi odczytać dane z pięciu znormalizowanych tabel, uzyskuje blokady na wszystkich z nich.
- Ryzyko:Jeśli inna transakcja modyfikuje jedną z tych tabel, pierwsza transakcja może czekać.
- Rozwiązanie: Rozważ zdenormalizowanie często łączyjących się kolumn. Zmniejszenie liczby połączeń zmniejsza liczbę blokad wymaganych na każde zapytanie.
2. Szerokie klucze podstawowe
Klucze podstawowe służą do jednoznacznego identyfikowania wierszy. Jeśli klucz podstawowy jest kluczem złożonym obejmującym wiele kolumn, wpływa to na sposób budowy indeksów. Szerokie klucze zwiększają rozmiar indeksu.
- Ryzyko:Większe indeksy oznaczają więcej stron do odczytania i zablokowania podczas wyszukiwania. Modyfikacje klucza podstawowego mogą wywołać zmiany kaskadowe w powiązanych tabelach.
- Rozwiązanie: Używaj prostych, wąskich kluczy zastępczych (np. liczb całkowitych), gdy to możliwe. Zachowuj klucze złożone minimalne i tylko wtedy, gdy są logicznie konieczne.
3. Obszary nadmiernego obciążenia w kluczach sekwencyjnych
Używanie liczb całkowitych zwiększanych automatycznie jako kluczy podstawowych jest powszechne. Jednak jeśli aplikacja wstawia dane sekwencyjnie, wszystkie nowe zapisy skierowane są na koniec indeksu. Powoduje to powstanie „zakładek”, gdzie wiele transakcji konkuruje o tę samą stronę liściową.
- Ryzyko: Silnik bazy danych musi zablokować ostatnią stronę indeksu przy każdej nowej wstawce.
- Naprawa:Użyj losowych kluczy lub dystrybucji opartych na skrótach w scenariuszach o wysokim obciążeniu zapisu, aby rozprowadzić obciążenie na różnych stronach.
Strategie optymalizacji schematu 🛠️
Optymalizacja ERD polega na podejmowaniu konkretnych decyzji dotyczących kolumn, relacji i ograniczeń. Poniższa tabela przedstawia typowe decyzje projektowe i ich wpływ na zachowanie blokad.
| Decyzja projektowa | Wpływ na blokady | Zalecana metoda |
|---|---|---|
| Ograniczenia kluczy obcych | Może powodować kaskadowe blokady w tabelach nadrzędnych. | Używaj opóźnionych ograniczeń lub weryfikacji na poziomie aplikacji w systemach o wysokim obciążeniu zapisu. |
| Duże kolumny BLOB/tekstowe | Zwiększa rozmiar wiersza, co wymaga większej liczby stron na wiersz. | Przechowuj duże dane osobno, aby utrzymać główną tabelę wąską. |
| Kolumny o wysokiej liczbie unikalnych wartości | Może prowadzić do nieefektywnego wykorzystania indeksów. | Upewnij się, że selektywne kolumny są indeksowane, aby uniknąć skanowania całej tabeli. |
| Wartości domyślne | Aktualizuje wiersze niepotrzebnie, jeśli stosowane są wartości domyślne. | Zezwalaj na wartości NULL tam, gdzie jest to odpowiednie, aby uniknąć wyzwalaczy zapisu. |
Odseparowanie modeli zapisu i odczytu
Oddzielenie schematu używanego do zapisu od schematu używanego do odczytu może znacznie zmniejszyć zawieszenie. Modele zapisu skupiają się na integralności i normalizacji. Modele odczytu skupiają się na szybkości i denormalizacji.
- Przechowuj dane w bardzo normalizowanej strukturze dla przetwarzania transakcji.
- Replicuj dane do struktury zoptymalizowanej pod odczyt do celów raportowania lub wyświetlania.
- Zapewnia, że ciężkie zapytania odczytowe nie blokują operacji zapisu.
Indeksowanie i wybór kluczy 📊
Indeksy są kluczowe dla wydajności, ale nie są darmowe. Każdy indeks musi być utrzymywany podczas aktualizacji. Jeśli tabela ma zbyt wiele indeksów, każdy insert lub update wymaga blokowania wielu struktur indeksów.
Zgrupowane vs. Niezgrupowane
- Indeks zgrupowany: Określa fizyczną kolejność danych. Zazwyczaj jest tylko jeden na tabelę. Wybieraj go ostrożnie, ponieważ wpływa na sposób przechowywania danych.
- Indeks niezgrupowany: Oddzielna struktura wskazująca na dane. Użyteczna do pokrywania zapytań bez dotykania głównej tabeli.
Unikaj tworzenia indeksów na kolumnach, które często są aktualizowane. Gdy wartość kolumny się zmienia, indeks musi zostać ponownie utworzony. Ten proces generuje blokady zapisu na strukturze indeksu.
Indeksy pokrywające
Indeks pokrywający zawiera wszystkie kolumny potrzebne do zapytania. Pozwala on bazie danych spełnić żądanie bez wyszukiwania rzeczywzych danych tabeli. Zmniejsza to zakres blokad utrzymywanych, ponieważ silnik nie musi blokować wierszy podstawowej tabeli.
- Zidentyfikuj częste zapytania odczytowe.
- Twórz indeksy zawierające
SELECTkolumny. - Monitoruj plany wykonania zapytań, aby upewnić się, że te indeksy są wykorzystywane.
Zakres transakcji i izolacja ⏱️
ERD wpływa na sposób działania transakcji. Długotrwałe transakcje utrzymują blokady przez dłuższy czas. Dobrze zaprojektowana schemat pomaga utrzymać transakcje krótkie.
Przetwarzanie partii
Zamiast przetwarzać tysiące wierszy w jednej transakcji, podziel pracę na mniejsze partie. Pozwala to wcześniej zwolnić blokady, umożliwiając innym procesom kontynuację pracy.
- Ogranicz liczbę wierszy modyfikowanych w jednym zatwierdzeniu.
- Używaj kursorów lub pętli do przetwarzania danych porcjami.
- Zrównowaguj koszt wielu zatwierdzeń z korzyścią z krótszego czasu trwania blokad.
Poziomy izolacji
Systemy baz danych oferują różne poziomy izolacji. Wyższe poziomy izolacji (takie jak Serializable) zapobiegają więcej anomalii, ale zwiększają blokady. Niższe poziomy izolacji (takie jak Read Committed) pozwalają na większą współbieżność.
- Unikaj Serializable, chyba że jest to absolutnie konieczne dla dokładności finansowej.
- Używaj Read Committed lub Repeatable Read dla większości zadań operacyjnych.
- Dostosuj poziom izolacji do wymagań biznesowych dotyczących spójności danych.
Monitorowanie i iteracja 🔄
Projektowanie nie jest jednorazową czynnością. Wraz z zmianą wzorców użytkowania zmieniają się również problemy z zawieszeniem blokad. Wymagane jest ciągłe monitorowanie w celu utrzymania wydajności.
- Statystyki oczekiwania: Śledź, jak długo transakcje czekają na blokady.
- Wykresy zakleszczeń: Analizuj diagramy pokazujące, które zapytania spowodowały zakleszczenia.
- Wydajność zapytań: Zidentyfikuj powolne zapytania, które mogą trzymać blokady dłużej niż przewidziano.
Regularnie przeglądarkuj ERD w świetle aktualnych metryk wydajności. Jeśli określona tabela ciągle pokazuje wysokie czasy oczekiwania, rozważ podział danych lub dostosowanie schematu w celu zmniejszenia obciążenia.
Ostateczne rozważania na temat architektury danych 🧩
Minimalizacja konkurencji na blokady to równowaga między integralnością danych a przepustowością systemu. Projektując schematy z myślą o współbieżności, zmniejszasz potrzebę rozwiązywania konfliktów przez silnik bazy danych. To prowadzi do szybszych czasów odpowiedzi i bardziej stabilnego systemu.
Zacznij od audytu obecnych relacji i kluczy. Poszukaj możliwości uproszczenia połączeń i zmniejszenia nadmiaru indeksów. Przetestuj swoje zmiany w środowisku testowym, aby zweryfikować wpływ na zachowanie blokad. Przy starannym planowaniu i dokładności, możesz stworzyć solidny warstwę danych, która skutecznie skaluje się.