










Projektowanie solidnej architektury danych wymaga więcej niż tylko łączenia tabel; wymaga ono rygorystycznego podejścia do struktury i integralności. Dla architektów danych normalizacja to nie tylko teoretyczna ćwiczenie z podręczników — to fundament utrzymywalnych, skalowalnych i niezawodnych systemów baz danych. Podczas tworzenia diagramów zależności encji (ERD) decyzje podjęte w fazie projektowania schematu determinują zdrowie aplikacji na długie lata. Poprawna normalizacja minimalizuje nadmiarowość danych i zapewnia spójność logiczną, zapobiegając błędom rozprzestrzeniającym się w dalszej kolejności.
Ten przewodnik przedstawia kluczowe zasady normalizacji, które każdy architekt danych musi stosować. Przeanalizujemy postępowanie od podstawowej atomowości do złożonych zależności, badając, jak każda zasada wpływa na przechowywanie danych, wydajność zapytań i jakość danych. Przestrzegając tych zasad, budujesz systemy, które wytrzymają próbę czasu.
Dlaczego struktura ma znaczenie w projektowaniu schematu 📐
Zanim przejdziemy do konkretnych form, kluczowe jest zrozumienie celu normalizacji. Głównym celem jest izolacja danych, aby modyfikacje, usuwanie i wstawianie nie powodowały anomalii. Bez strukturalnego podejścia bazy danych stają się podatne na trzy konkretne typy anomalii:
-
Anomalie wstawiania: Niezdolność dodania danych o jednym obiekcie bez dodania danych o innym, niepowiązanym obiekcie.
-
Anomalie aktualizacji: Konieczność aktualizacji tej samej wartości w wielu wierszach, co stwarza ryzyko niezgodności, jeśli jeden wiersz zostanie pominięty.
-
Anomalie usuwania: Strata danych o jednym obiekcie podczas usuwania danych o innym.
Normalizacja rozwiązuje te problemy poprzez organizację atrybutów w tabelach opartych na zasadach zależności. Ta separacja pozwala bazie danych działać jako jedyny źródło prawdy. Choć proces może wydawać się monotony, zmniejszenie obciążenia utrzymania i ryzyka uszkodzenia danych czyni go istotnym inwestycją.
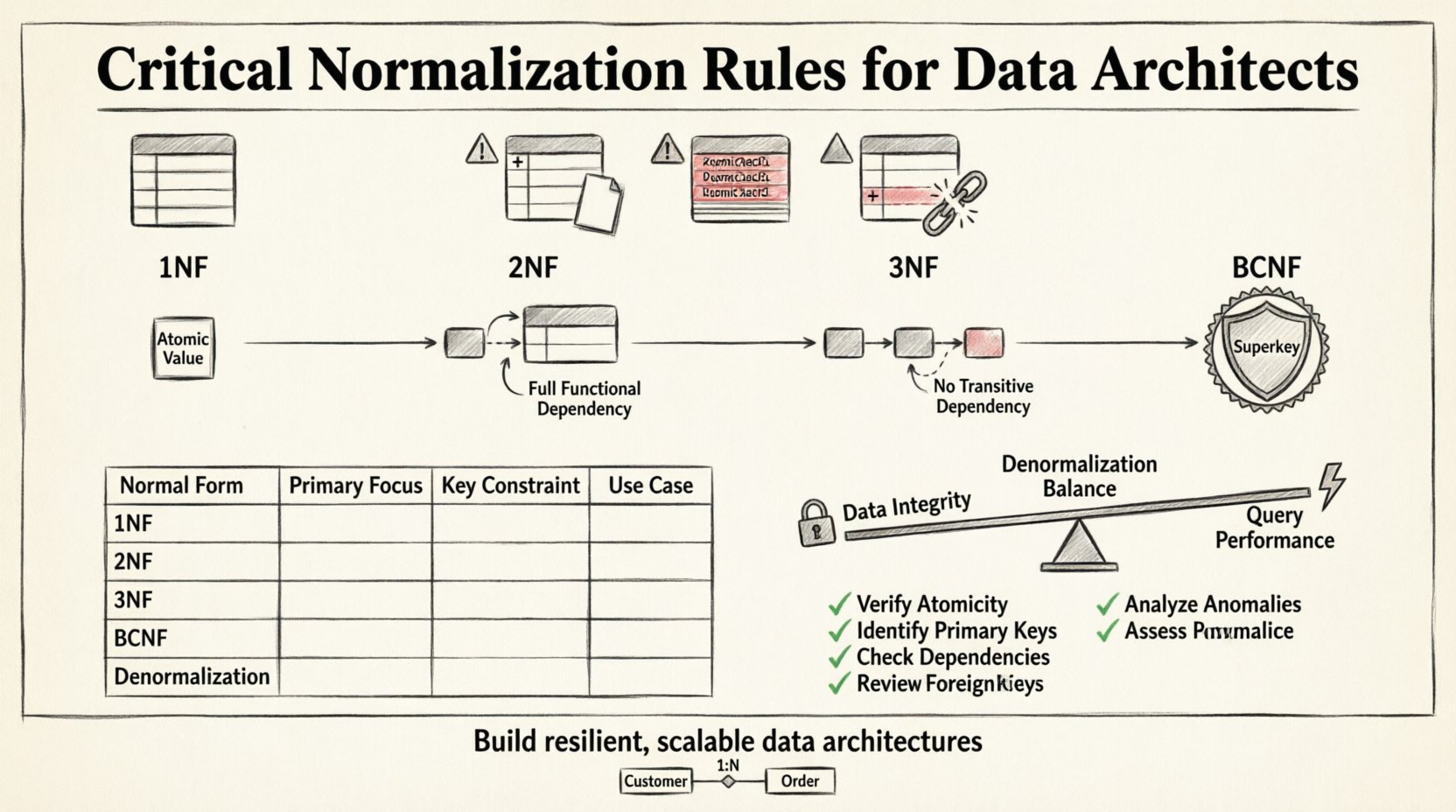
Podstawa: Pierwsza postać normalna (1NF) 🧱
Pierwszym krokiem w normalizacji jest osiągnięcie Pierwszej Postaci Normalnej. Jest to podstawowy wymóg dla każdej bazy danych relacyjnej. Tabela znajduje się w 1NF, jeśli spełnia dwa warunki: zawiera wyłącznie wartości atomowe oraz każda kolumna zawiera tylko jedną wartość w każdym wierszu. W jednym polu nie powinny występować powtarzające się grupy lub tablice.
Naruszenia 1NF często występują, gdy programiści próbują przechowywać listy w jednej kolumnie, np. przechowując wiele numerów telefonów w jednym polu oddzielonych przecinkami. Ten sposób utrudnia zapytania i indeksowanie. Zamiast tego każda część danych powinna istnieć w osobnym wierszu.
-
Atomowość: Upewnij się, że każda kolumna zawiera pojedynczą, niepodzielną wartość.
-
Unikalne wiersze: Każdy wiersz musi być unikalny, często zapewniony przez klucz główny.
-
Kolejność kolumn: Kolejność kolumn nie powinna wpływać na znaczenie danych.
Rozważ tabelę klientów. Jeśli klient ma trzy adresy e-mail, nie twórz trzech kolumn e-mail. Utwórz osobną tabelę „E-mail” powiązaną kluczem obcym. Ta struktura zapewnia, że dodanie czwartego adresu e-mail nie wymaga zmiany schematu tabeli.
Usunięcie częściowych zależności (2NF) ⚖️
Po osiągnięciu 1NF następnym krokiem jest sprawdzenie częściowych zależności. Tabela znajduje się w Drugiej Postaci Normalnej, jeśli jest już w 1NF oraz każdy atrybut niekluczowy jest całkowicie zależny od klucza głównego. Ta zasada staje się szczególnie istotna podczas pracy z złożonymi kluczami głównymi.
Złożony klucz główny składa się z dwóch lub więcej kolumn. W tym przypadku występuje częściowa zależność, gdy atrybut niekluczowy zależy tylko od części złożonego klucza. Na przykład w tabeli śledzącej pozycje zamówień, gdzie klucz główny to (IDZamówienia, IDProduktu), kolumna „NazwaProduktu” może zależeć tylko od „IDProduktu”, a nie od ich kombinacji.
-
Pełna zależność: Upewnij się, że każdy atrybut niekluczowy zależy od całego klucza głównego.
-
Oddzielenie odpowiedzialności: Przenieś atrybuty zależne od podzbioru klucza do nowej tabeli.
-
Sprawdzanie integralności: Upewnij się, że żaden atrybut nie może zostać wyprowadzony bez pełnego klucza.
Przenosząc „ProductName” do osobnej tabeli powiązanej za pomocą „ProductID”, eliminujesz ryzyko zmiany nazwy w jednym zamówieniu, a nie w drugim. Zmniejsza to wymagane miejsce na dysku i zapewnia spójność we wszystkich rekordach zamówień.
Usuwanie zależności przechodnich (3NF) 🔗
Trzecia postać normalna rozszerza strukturę o kolejny krok, rozwiązując zależności przechodnie. Tabela znajduje się w 3NF, jeśli jest w 2NF i wszystkie atrybuty niekluczowe nie są zależne przechodnio od klucza głównego. W praktyce oznacza to, że kolumny niekluczowe nie powinny zależeć od innych kolumn niekluczowych.
Wyobraź sobie tabelę z EmployeeID, EmployeeName, DepartmentID i DepartmentName. Jeśli EmployeeName określa DepartmentName, występuje zależność przechodnia. Jeśli pracownik zmienia dział, DepartmentName w tabeli pracowników może się wygasnąć, jeśli nie zostanie poprawnie zaktualizowane. Aby to naprawić, tabela Department powinna zostać rozdzielona.
-
Tylko zależności bezpośrednie:Atrybuty powinny zależeć bezpośrednio od klucza, a nie od innych atrybutów.
-
Grupowanie logiczne: Grupuj powiązane atrybuty, które mają wspólny czynnik determinujący, w osobne encje.
-
Klucze obce: Użyj kluczy obcych, aby połączyć rozdzielone tabele.
To rozdzielenie zapewnia, że informacje o działach są przechowywane tylko raz. Jeśli zmieni się nazwa działu, zostanie zaktualizowana tylko w jednym miejscu, a wszystkie rekordy pracowników automatycznie odzwierciedlą zmianę dzięki relacji.
Kiedy 3NF nie wystarcza: BCNF i dalej 🚀
Choć 3NF obejmuje większość typowych scenariuszy projektowania, istnieją przypadki graniczne, w których ściśle zastosowana 3NF jest niewystarczająca. Postać normalna Boyce’a-Codda (BCNF) to bardziej rygorystyczna wersja 3NF, która obsługuje sytuacje z wieloma kluczami kandydującymi. BCNF wymaga, aby dla każdej zależności funkcyjnej X → Y, X było nadkluczem.
Wyobraź sobie sytuację, w której uczeń może mieć wielu nauczycieli, a nauczyciel może prowadzić wiele przedmiotów. Jeśli kluczem głównym jest (Student, Subject), a nauczyciel jest przypisywany na podstawie przedmiotu, możesz napotkać sytuacje, w których logika zależności nakłada się na siebie w skomplikowany sposób. BCNF zapewnia, że żadna kolumna nie jest określana przez zbiór kolumn, który nie jest kluczem kandydującym.
-
Wymóg nadklucza: Wyznacznik w każdej zależności musi być nadkluczem.
-
Złożone relacje: Obsługuj relacje wiele do wielu za pomocą tabel pośrednich.
-
Rozważenie nadmiarowości:Wyższe postacie normalne mogą zwiększać złożoność połączeń.
Czwarta postać normalna (4NF) i piąta postać normalna (5NF) zajmują się zależnościami wielowartościowymi i zależnościami połączeń. Są one rzadkie w ogólnych zastosowaniach biznesowych, ale mają kluczowe znaczenie w specjalistycznym magazynowaniu danych lub modelowaniu danych naukowych.
Sztuka strategicznego zdenormalizowania ⚡
Normalizacja nie zawsze jest końcowym celem. W niektórych środowiskach o wysokiej wydajności ściśle zastosowana normalizacja może prowadzić do nadmiernych połączeń, które pogarszają szybkość zapytań. W takich przypadkach pojawia się strategiczne zdenormalizowanie. Zdenormalizacja polega na dodawaniu danych redundantnych do bazy danych w celu optymalizacji wydajności odczytu.
Jednak nie powinno się tego robić dowolnie. Wymaga to jasnego zrozumienia kompromisów między szybkością odczytu a złożonością zapisu. Gdy operacje odczytu znacznie przewyższają operacje zapisu, redundancja może być uzasadniona.
-
Obciążenia zdominowane odczytami: Jeśli raportowanie jest główną funkcją, zdenormalizowanie może zmniejszyć czas zapytania.
-
Warstwy buforowania: Użyj buforowania na poziomie aplikacji przed modyfikacją schematu.
-
Ryzyko spójności danych: Uwaga, dane nadmiarowe mogą wyjść poza synchronizację.
-
Kary za zapis: Każda operacja zapisu musi aktualizować wszystkie kopie nadmiarowe danych.
Powszechnym wzorcem jest usunięcie normalizacji tabel podsumowujących dla pulpitów raportujących, podczas gdy dane transakcyjne główne pozostają w 3NF. Ten hybrydowy podejście równoważy integralność z wydajnością.
Porównanie form normalnych
|
Forma normalna |
Główny nacisk |
Ograniczenie klucza |
Typowy przypadek użycia |
|---|---|---|---|
|
1NF |
Wartości atomowe |
Brak powtarzających się grup |
Początkowy projekt schematu |
|
2NF |
Pełna zależność |
Brak częściowych zależności od kluczy złożonych |
Złożone klucze |
|
3NF |
Zależność przechodnia |
Atrybuty niekluczowe zależą wyłącznie od klucza |
Ogólna logika biznesowa |
|
BCNF |
Superklucze |
Wyznacznik musi być superkluczem |
Złożone klucze kandydujące |
Prawdziwy checklist dla architektów danych ✅
Aby upewnić się, że Twój ERD spełnia standardy branżowe, przejdź przez ten checklist podczas fazy projektowania. Ten proces pomaga wykryć potencjalne problemy przed napisaniem kodu.
-
Weryfikuj atomowość: Upewnij się, że żadna kolumna nie zawiera wielu różnych wartości.
-
Zidentyfikuj klucze główne: Potwierdź, że każda tabela ma unikalny identyfikator.
-
Sprawdź zależności: Zaprojektuj, jak każdy kolumna jest powiązana z kluczem głównym.
-
Przejrzyj klucze obce: Upewnij się, że relacje są jawnie zdefiniowane.
-
Analizuj anomalie: Przeprowadź w myślach symulację operacji wstawiania, aktualizacji i usuwania.
-
Oceń wydajność: Określ, czy 3NF jest wystarczające, czy potrzebna jest denormalizacja.
-
Zdokumentuj ograniczenia: Jasną zdefiniuj zasady wprowadzania i weryfikacji danych.
-
Zaplanuj rozwój: Rozważ, jak schemat będzie radził sobie z rosnącą objętością danych.
Śledząc te kroki, tworzysz schemat odporny na zmiany. Architektura danych nie jest stała; ewoluuje wraz z potrzebami biznesowymi. Dobrze znormalizowana podstawa ułatwia tę ewolucję, ponieważ zmiany w jednej części systemu nie powodują nieprzewidywalnych skutków w pozostałych jego częściach.
Pamiętaj, że normalizacja to narzędzie, a nie prawo. Choć 3NF jest standardem dla systemów transakcyjnych, konkretne potrzeby Twojej aplikacji mogą wymagać odstępstw. Zawsze należy dążyć do integralności danych i wydajności systemu. Zrównowaguj te dwa czynniki ostrożnie, a Twój ERD stanie się solidną podstawą dla całego ekosystemu aplikacji.
Przyjęcie tych kluczowych zasad normalizacji pozwala Ci budować systemy, które są nie tylko funkcjonalne dziś, ale też elastyczne w przyszłości. Skup się na relacjach między punktami danych, a struktura samorzutnie się uformuje.