











Projektowanie schematu bazy danych rzadko jest binarnym wyborem między szybkością a strukturą. Jest to ćwiczenie w kompromisie. Gdy architekci tworzą diagramy encji-związków (ERD), często napotykają napięcie między ścisłą integralnością danych a surową szybkością wymaganą przez aplikacje o dużym obciążeniu. Normalizacja minimalizuje nadmiarowość, zapewniając spójność danych. Jednak koszt utrzymania tej spójności często opłacany jest kosztem wydajności odczytu.
Ten artykuł omawia techniczne subtelności tego równowagi. Przeanalizujemy, jak normalizacja wpływa na połączenia, jak obciążenia odczytu wymuszają zmiany w schemacie oraz gdzie granica między dobrze zbudowaną bazą danych a wydajną przechodzi.
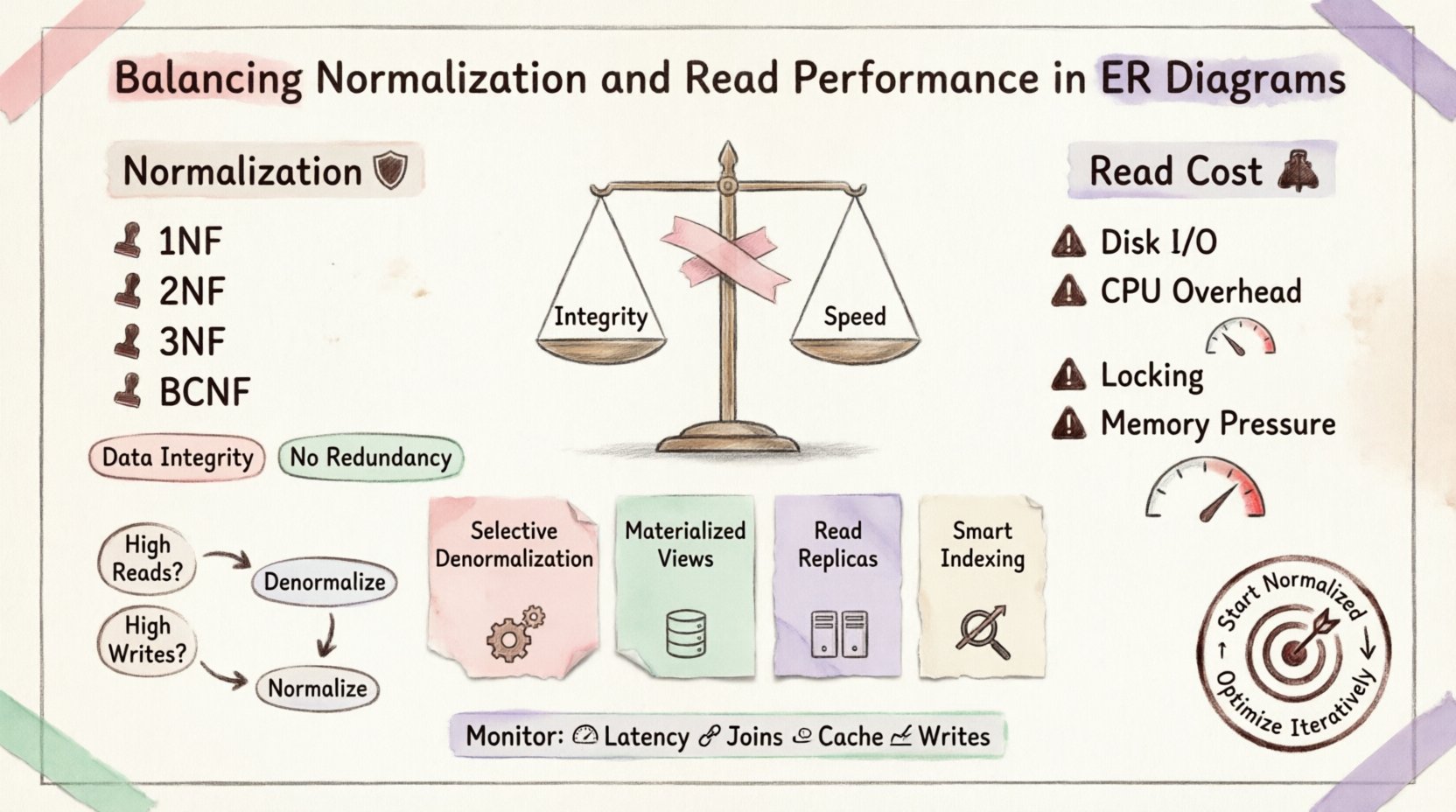
Zrozumienie normalizacji: Podstawa 🛡️
Normalizacja to proces organizowania danych w celu zmniejszenia nadmiarowości i poprawy integralności danych. Polega na dzieleniu dużych tabel na mniejsze, logiczne jednostki oraz definiowaniu między nimi relacji. Celem jest eliminacja anomalii podczas wstawiania, aktualizacji i usuwania danych.
Kluczowe formy normalne
-
Pierwsza forma normalna (1NF): Zapewnia atomowość. Każda kolumna zawiera tylko jedną wartość. Brak powtarzających się grup.
-
Druga forma normalna (2NF): Buduje się na 1NF. Wszystkie atrybuty niekluczowe muszą być całkowicie zależne od klucza głównego. Usuwa zależności częściowe.
-
Trzecia forma normalna (3NF): Buduje się na 2NF. Usuwa zależności przechodnie. Atrybuty niekluczowe zależą wyłącznie od klucza, całego klucza i niczego innego.
-
Forma normalna Boyce’a-Codda (BCNF): Straszyjsza wersja 3NF przeznaczona do obsługi określonych anomalii zależności.
Choć przestrzeganie tych form gwarantuje czystą bazę danych, wprowadza złożoność w zapytaniach. Każda relacja zdefiniowana w diagramie ER staje się potencjalną operacją połączenia.
Koszt odczytu 💸
Gdy normalizujesz dane, często dzielisz informacje na kilka tabel. Aby pobrać pełny rekord, silnik bazy danych musi wykonać operacje połączeń. Połączenia są kosztowne obliczeniowo.
Dlaczego połączenia spowalniają zapytania
-
Wejście/wyjście dysku: Jeśli tabele nie są idealnie indeksowane lub buforowane, silnik musi wyszukiwać dane w różnych fizycznych lokalizacjach na dysku.
-
Nadmiar obciążenia CPU: Baza danych musi dopasować klucze z jednej tabeli do drugiej. Wymaga to znacznej mocy przetwarzania.
-
Kontestacja blokad: Złożone połączenia mogą dłużej trzymać blokady, blokując inne transakcje przed dostępem do powiązanych danych.
-
Nacisk pamięci: Duże operacje połączeń wymagają znacznych buforów pamięci do sortowania i haszowania danych.
W środowisku o dużym obciążeniu odczytu, takim jak pulpity raportujące lub publiczne interfejsy API, ta opóźnienie jest nieakceptowalne. Użytkownicy oczekują natychmiastowej odpowiedzi. Zapytanie, które zajmuje 100 milisekund na zwrócenie danych normalizowanych, może zająć tylko 10 milisekund, jeśli dane są denormalizowane.
Strategie optymalizacji 🚀
Aby zrównoważyć integralność i szybkość, architekci wykorzystują konkretne wzorce. Te strategie pozwalają zachować normalizację bazy danych tam, gdzie najbardziej się liczy, jednocześnie optymalizując odczyt tam, gdzie ma znaczenie.
1. Wybierana denormalizacja
Nie wszystkie tabele muszą być w pełni znormalizowane. Zidentyfikuj najczęściej dostępną daną i przechowuj ją redundantnie. Na przykład, jeśli często pobierasz imiona użytkowników wraz z ich historią zamówień, przechowywanie imienia użytkownika bezpośrednio w tabeli zamówień oszczędza operację połączenia.
2. Widoki materializowane
Widok materializowany przechowuje wynik zapytania fizycznie na dysku. Jest to zasadniczo tabelę z wcześniej obliczonymi danymi. Gdy dane się zmieniają, widok musi zostać odświeżony. Jest to idealne rozwiązanie dla złożonych agregacji, które nie wymagają dokładności w czasie rzeczywistym.
3. Replikacja odczytu
Oddziel obciążenie odczytu od obciążenia zapisu. Wszystkie operacje zapisu kieruj do podstawowej bazy danych, która pozostaje znormalizowana. Wszystkie operacje odczytu kieruj do repliki. Pozwala to optymalizować replikę inaczej, np. z większą liczbą indeksów lub strukturami nieznormalizowanymi, nie wpływając przy tym na integralność transakcji.
4. Strategia indeksowania
Nawet znormalizowane bazy danych mogą dobrze działać przy odpowiednich indeksach. Indeksy pokrywające pozwalają bazie danych spełnić zapytanie wyłącznie na podstawie indeksu, unikając poszukiwań w tabeli. Indeksy złożone mogą przyspieszyć połączenia na wspólnych kluczach obcych.
Kiedy zastosować nieznormalizowanie 📉
Nieznormalizowanie to celowe decyzje, a nie stan domyślny. Powinno być podejmowane na podstawie dowodów z monitorowania wydajności, a nie założeń.
|
Scenariusz |
Podchody |
Uzasadnienie |
|---|---|---|
|
Wysoka częstotliwość zapisu |
Zachowaj znormalizowanie |
Aktualizacje są szybsze. Mniej redundancji do utrzymania. |
|
Wysoka częstotliwość odczytu |
Rozważ nieznormalizowanie |
Zmniejsza połączenia. Szybsze czasy pobierania. |
|
Krytyczna spójność danych |
Zachowaj znormalizowanie |
Jedno źródło prawdy zapobiega rozpraszaniu danych. |
|
Raportowanie i analizy |
Zastosuj nieznormalizowanie |
Agregacje są złożone; wczesne obliczanie pomaga. |
|
Potrzeby skalowalności |
Hybrydowy podejście |
Podziel usługi lub użyj warstw buforowania. |
Zalety i wady: integralność danych vs szybkość ⚙️
Zawsze, gdy wprowadzasz redundancję, ryzykujesz niezgodność danych. Jeśli użytkownik zmienia swój adres e-mail, ale e-mail jest przechowywany w obuUżytkownicy stół i Powiadomienia tabela, jedno aktualizowanie może się nie powieść lub zostać pominięte. Jest to znane jako anomalie aktualizacji.
Aby temu zapobiec, logika aplikacji musi być odporna. Wyzwalacze mogą zapewnić spójność, ale dodają złożoność. Alternatywnie, zaprojektuj schemat w taki sposób, aby dane nienormalizowane były wyprowadzane i niezmienne, co zmniejsza ryzyko rozbieżności.
Obsługa spójności
-
Logika na poziomie aplikacji: Napisz kod, który aktualizuje wszystkie nadmiarowe kopie atomowo.
-
Wyzwalacze bazy danych: Pozwól bazie danych automatycznie stosować zasady. Zachowuje to logikę blisko danych.
-
Spójność ostateczna: Przyjmij, że dane mogą być przestarzałe przez krótki czas. Używaj zadań w tle do synchronizacji nadmiarowych danych.
Monitorowanie i utrzymanie 🔧
Stały projekt nie uwzględnia zmieniających się wzorców użytkowania. To, co działa dziś, może być przeszkodą w przyszłości. Ciągłe monitorowanie jest niezbędne.
Kluczowe metryki do śledzenia
-
Opóźnienie zapytania: Monitoruj czas potrzebny na krytyczne zapytania odczytu.
-
Liczba połączeń: Śledź liczbę połączeń na każde złożone zapytanie.
-
Stosunek trafień w pamięci podręcznej: Jeśli używasz pamięci podręcznej, sprawdź, czy skutecznie zmniejsza obciążenie bazy danych.
-
Opóźnienie zapisu: Upewnij się, że nienormalizacja nie spowolniła zapisów zbyt mocno.
Wnioski: decyzja kontekstowa 🎯
Nie ma uniwersalnego standardu projektowania baz danych. Najlepszy diagram ER to ten, który pasuje do Twojego konkretnego obciążenia. Normalizacja zapewnia bezpieczeństwo; nienormalizacja zapewnia szybkość. Celem jest znalezienie punktu równowagi.
Zacznij od projektu normalizowanego, aby zapewnić integralność danych. Gdy pojawiają się przeszkody wydajnościowe, zidentyfikuj konkretne zapytania powodujące opóźnienia. Stosuj nienormalizację lub pamięć podręczną tylko w tych obszarach. Ta iteracyjna metoda zapobiega przedwczesnej optymalizacji i zapewnia, że system pozostanie łatwy do utrzymania w czasie.
Pamiętaj, że technologia się rozwija. Nowe silniki przechowywania i optymalizatory zapytań ciągle zmniejszają koszt połączeń. Regularnie przeglądarkuj swój schemat pod kątem obecnych możliwości. Równowaga się zmienia, a Twój projekt musi się zmieniać razem z nią.
Zrozumienie mechanizmów normalizacji i rzeczywistości wydajności odczytu pozwala budować systemy, które są zarówno odporne, jak i reaktywne. Skup się na danych, a nie tylko na kodzie.