











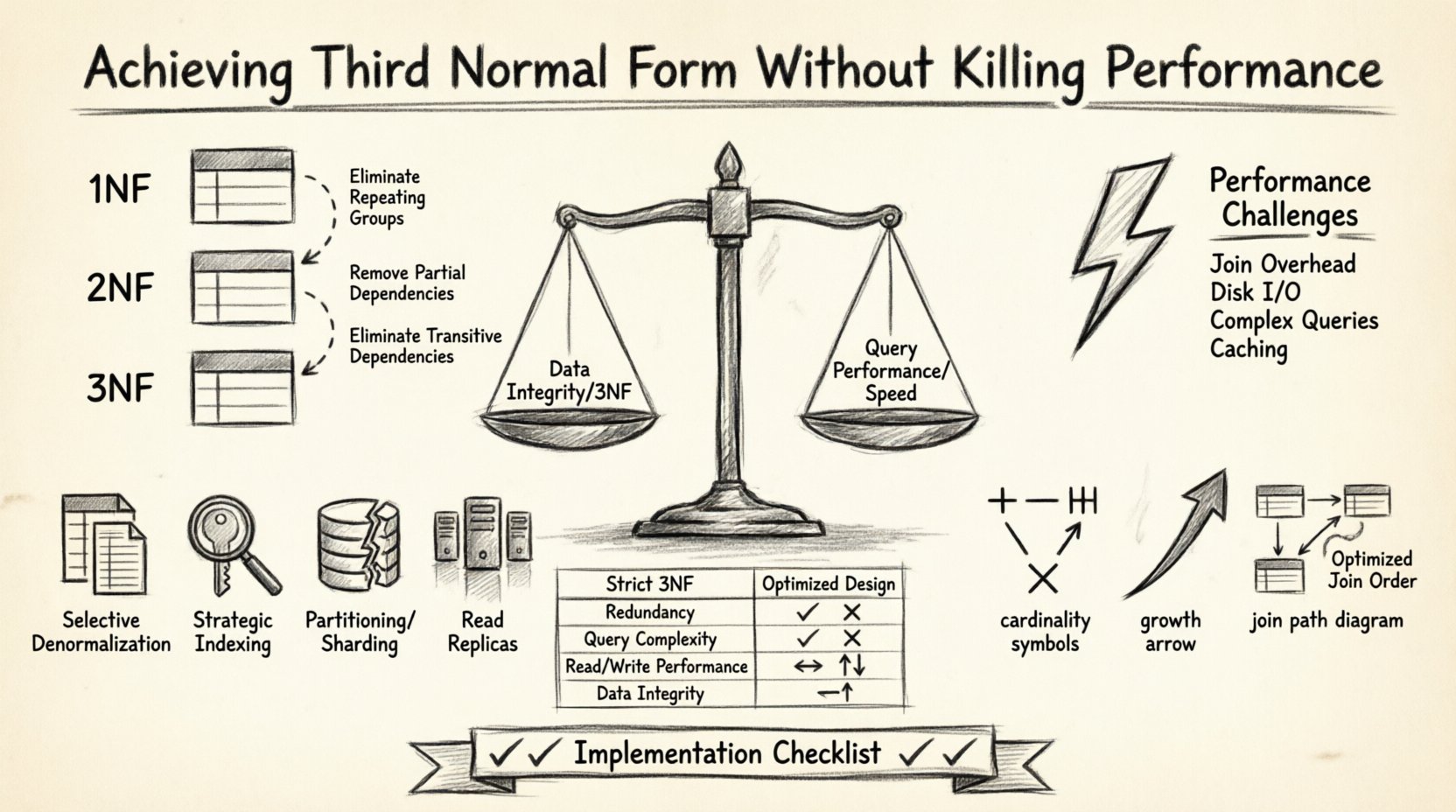
Projektowanie solidnej struktury bazy danych to balans. Z jednej strony mamy integralność danych i eliminację nadmiarowości poprzez normalizację. Z drugiej strony mamy szybkość zapytań i reaktywność systemu. Wiele architektów baz danych stoi przed trudnym wyborem: przestrzegać surowych zasad normalizacji i ryzykować powolne zapytania, albo agresywnie de-normalizować i ryzykować niezgodności danych. Celem jest znalezienie złotego środka, w którym baza danych spełnia trzecią postać normalną (3NF), jednocześnie utrzymując wysoką wydajność. Niniejszy artykuł omawia, jak projektować diagramy zależności encji (ERD), aby osiągnąć to równowaga bez kompromitowania ani integralności, ani szybkości.
Zrozumienie trzeciej postaci normalnej 🧩
Trzecia postać normalna to określony poziom normalizacji bazy danych. Przed osiągnięciem 3NF tabela musi najpierw spełniać pierwszą postać normalną (1NF) i drugą postać normalną (2NF). Głównym założeniem 3NF jest to, że wszystkie atrybuty muszą zależeć wyłącznie od klucza głównego. Nie powinno istnieć zależności przechodnich.
- Pierwsza postać normalna: Usuwa powtarzające się grupy i zapewnia wartości atomowe.
- Druga postać normalna: Usuwa częściowe zależności, w których atrybuty niekluczowe zależą tylko od części klucza złożonego.
- Trzecia postać normalna: Usuwa zależności przechodnie. Jeśli A decyduje o B, a B decyduje o C, to C nie powinno bezpośrednio zależeć od A w tej samej tabeli.
Gdy osiągniesz 3NF, minimalizujesz anomalie aktualizacji. Są to błędy, które występują, gdy dane są zmieniane w jednym miejscu, ale nie w innych, co prowadzi do niezgodności. Na przykład, jeśli adres klienta jest przechowywany zarówno w tabeli „Zamówienia”, jak i w tabeli „Klienci”, zmiana adresu w jednej tabeli, ale nie w drugiej, powoduje rozbieżność.Zamówienia tabela oraz w Klienci tabeli, zmiana adresu w jednej tabeli, ale nie w drugiej, powoduje rozbieżność. 3NF wymusza przechowywanie tego adresu tylko w jednym miejscu.
Zalety wydajnościowe ⚡
Choć 3NF jest doskonałe dla integralności danych, często wiąże się z kosztem wydajności. Bazy danych znormalizowane zwykle wymagają większej liczby tabel. Aby pobrać kompletny zestaw danych, silnik bazy danych musi wykonać wiele połączeń. Każde połączenie wymaga od systemu odczytania danych z dysku lub pamięci, dopasowania kluczy i połączenia wyników.
Wyobraź sobie zapytanie raportujące wymagające imion klientów, szczegółów zamówień, opisów produktów i adresów wysyłki. W pełni znormalizowanym projekcie 3NF może to wymagać połączenia pięciu lub więcej tabel. Jeśli objętość danych jest duża, takie połączenia mogą stać się węzłem zastojowym.
Oto konkretne wyzwania wydajnościowe związane z 3NF:
- Zwiększony koszt połączeń: Każda relacja wymaga operacji połączenia podczas zapytań odczytu.
- Wejście/wyjście dysku: Rozpraszanie danych na wielu tabelach zwiększa liczbę stron, które silnik bazy danych musi odwiedzić.
- Złożona logika zapytań:Aplikacje muszą tworzyć bardziej złożone instrukcje SQL, aby pobrać powiązane dane.
- Złożoność buforowania:Buforowanie pojedynczego wiersza de-normalizowanego jest prostsze niż buforowanie wielu powiązanych wierszy.
Strategie równowagi między integralnością a szybkością 🚀
Nie musisz rezygnować z normalizacji, aby poprawić wydajność. Istnieją konkretne techniki optymalizacji bazy danych 3NF bez zmiany struktury. Poniższe strategie pomagają utrzymać jakość danych bez poświęcania szybkości.
1. Wybierana de-normalizacja
Nie każda tabela musi być ściśle w 3NF. Zidentyfikuj tabele o dużym obciążeniu odczytu oraz kluczowe ścieżki danych. Możesz wprowadzić kontrolowaną nadmiarowość w tych konkretnych obszarach. Na przykład, przechowuj imię klienta bezpośrednio w tabeli Zamówienia tabela. Choć powoduje to powielanie danych, zysk wydajności przy wyszukiwaniu zamówień jest znaczny. Następnie musisz zaimplementować wyzwalacz lub logikę aplikacji, aby utrzymać tę kopię aktualną, gdy zmienia się rekord klienta.
2. Strategiczne indeksowanie
Indeksy są głównym narzędziem przyspieszania łączeń. Bez indeksów baza danych wykonuje pełne skanowanie tabeli dla każdego warunku łączenia. Poprawne indeksowanie sprawia, że wyszukiwania stają się niemal natychmiastowe.
- Indeksy kluczy obcych: Zawsze indeksuj kolumny używane w relacjach kluczy obcych. Zapewnia to szybkie łączenie tabel.
- Indeksy złożone: Twórz indeksy na wielu kolumnach, jeśli Twoje zapytania często filtrowane są według tej kombinacji.
- Indeksy przykrywające: Projektuj indeksy zawierające wszystkie kolumny potrzebne dla określonego zapytania. Pozwala to bazie danych spełnić zapytanie wyłącznie na podstawie indeksu, unikając wyszukiwania w danych głównej tabeli.
3. Partycjonowanie i sharding
Jeśli zestaw danych staje się zbyt duży, podział tabel może poprawić wydajność. Partycjonowanie dzieli dużą tabelę na mniejsze, łatwiejsze w zarządzaniu fragmenty fizyczne oparte na kluczu, takim jak data lub region. Sharding rozdziela dane na wiele instancji bazy danych. Oba podejścia zmniejszają ilość danych, które silnik musi przeszukać, aby odpowiedzieć na konkretne zapytanie.
4. Replikacja odczytu
Oddziel operacje zapisu od operacji odczytu. Użyj podstawowej instancji bazy danych do transakcji i aktualizacji. Replikuj dane do jednej lub więcej odczytowych replik. Złożone zapytania raportujące obciążające system mogą działać na replikach, utrzymując główny system szybkim dla interakcji użytkowników.
Rozważania dotyczące projektowania ERD 📐
Podczas rysowania diagramu relacji encji (ERD) jego wizualna prezentacja wpływa na sposób, w jaki deweloperzy piszą zapytania. Jasny ERD pomaga wczesnie zidentyfikować relacje. Jednak diagram, który wygląda idealnie na papierze, może źle działać w środowisku produkcyjnym. Oto jak podejść do projektowania ERD pod kątem wydajności.
- Jasno zidentyfikuj liczność: Upewnij się, że każda relacja ma zdefiniowaną liczebność (jeden do jednego, jeden do wielu, wiele do wielu). Niejasne relacje prowadzą do nieefektywnych łączeń.
- Planuj rozwój: Przewiduj przyszłą objętość danych. Projekt działający dla 10 000 wierszy może zawieść przy 10 milionach wierszy.
- Przejrzyj ścieżki łączeń: Prześledź ścieżki, które typowe zapytanie przejdzie przez diagram. Jeśli ścieżka jest zbyt długa, rozważ dodanie kolumny znormalizowanej.
- Dokumentuj ograniczenia: Jasno dokumentuj, które ograniczenia są realizowane przez bazę danych, a które przez warstwę aplikacji.
Porównanie: Projekt znormalizowany vs. optymalizowany 📊
Poniższa tabela ilustruje różnice między ściśle znormalizowanym podejściem 3NF a optymalizowanym podejściem w konkretnym scenariuszu.
| Cecha | Ściśle znormalizowany projekt 3NF | Optymalizowany projekt |
|---|---|---|
| Zmieszanie | Minimalne | Kontrolowane i ograniczone |
| Złożoność zapytań | Wysoka (wiele połączeń) | Umiarkowana (mniej połączeń) |
| Wydajność zapisu | Szybkie (mniej danych) | Zmienne (wyzwalacze aktualizacji) |
| Wydajność odczytu | Wolniejsze (wejście/wyjście dysku) | Szybsze (dane w pamięci podręcznej) |
| Integralność danych | Wysoka | Wysoka (z weryfikacją) |
Kiedy łamać zasady 🛑
Istnieją uzasadnione sytuacje, w których należy zrezygnować z ściślego 3NF. Zrozumienie, kiedy odchodzić od zasad, jest kluczowe dla architektów baz danych.
- Raportowanie i analiza:Magazyny danych często używają schematu gwiazdy zamiast 3NF. Celem jest szybkość odczytu do analizy, a nie integralność transakcyjna.
- Systemy transakcyjne o wysokiej przepustowości: Jeśli system obsługuje miliony zapisów na sekundę, złożone połączenia mogą powodować zawieszenie blokad. Uproszczenie schematu może zmniejszyć koszty blokowania.
- Stare systemy: Jeśli przenosisz się z starego systemu, może być szybciej tymczasowo zredukować normalizację podczas ponownego budowania warstwy aplikacji.
- Aplikacje z dużym obciążeniem odczytu: Jeśli Twoja aplikacja odczytuje dane 100 razy na każdy zapis, koszt utrzymania spójności 3NF przewyższa korzyści.
Lista kontrolna wdrożenia ✅
Zanim wdrożysz schemat bazy danych, przejdź przez tę listę kontrolną, aby upewnić się, że masz zrównoważoną wydajność i normalizację.
- Analizuj wzorce zapytań: Zidentyfikuj najczęściej wykonywane zapytania odczytu. Czy wymagają zbyt wielu połączeń?
- Zmierz obecną wydajność:Zdefiniuj基准 systemu. Znajdź obecną opóźnienie krytycznych zapytań.
- Przejrzyj użycie indeksów:Sprawdź, czy indeksy są wykorzystywane, czy powodują obciążenie podczas zapisu.
- Przetestuj obciążenie zapisu:Upewnij się, że żadna strategia denormalizacji nie spowalnia zapisu zbyt mocno.
- Zaplanuj synchronizację danych:Jeśli duplikujesz dane, jak je utrzymasz zsynchronizowane? Zdefiniuj mechanizm.
- Monitoruj anomalie:Skonfiguruj ostrzeżenia o niezgodności danych, jeśli używasz częściowej denormalizacji.
Ostateczne rozważania nad architekturą bazy danych 🏗️
Osiągnięcie trzeciej postaci normalnej bez pogorszenia wydajności wymaga subtelnej strategii. Nie jest to binarna decyzja między szybkością a integralnością. Zrozumienie kosztu łączeń, skuteczne wykorzystanie indeksów oraz stosowanie celowej denormalizacji tam, gdzie to odpowiednie, pozwala stworzyć systemy, które są zarówno niezawodne, jak i szybkie. Najlepsza architektura bazy danych to taka, która dopasowana jest do specyficznego obciążenia aplikacji. Regularnie przeglądarkuj swoją ERD i wydajność zapytań w miarę rozwoju systemu. Adaptacja to klucz do długoterminowego sukcesu w zarządzaniu danymi.