











W nowoczesnych architekturach danych szybkość pobierania informacji często decyduje o użyteczności aplikacji. Choć ulepszenia sprzętu i strategie buforowania odgrywają istotną rolę, podstawą wydajności jest struktura danych sama w sobie. Dokładnie, projekt modeli relacji encji (ERMs) decyduje o tym, jak skutecznie silnik bazy danych może przeszukiwać, łączyć i agregować dane. Zoptymalizowana schemat nie tylko organizuje informacje; prowadzi optymalizator zapytań ku szybszym ścieżkom wykonania. 📉
Ten przewodnik bada mechanizmy techniczne stojące za projektowaniem schematów oraz ich bezpośredni związek z wydajnością zapytań. Przeanalizujemy, jak poziomy normalizacji, liczba elementów relacji i strategie indeksowania oddziałują na plan wykonania zapytania. Zrozumienie tych zjawisk pozwala programistom i architektom baz danych budować systemy, które skalują się bez utraty integralności ani szybkości.
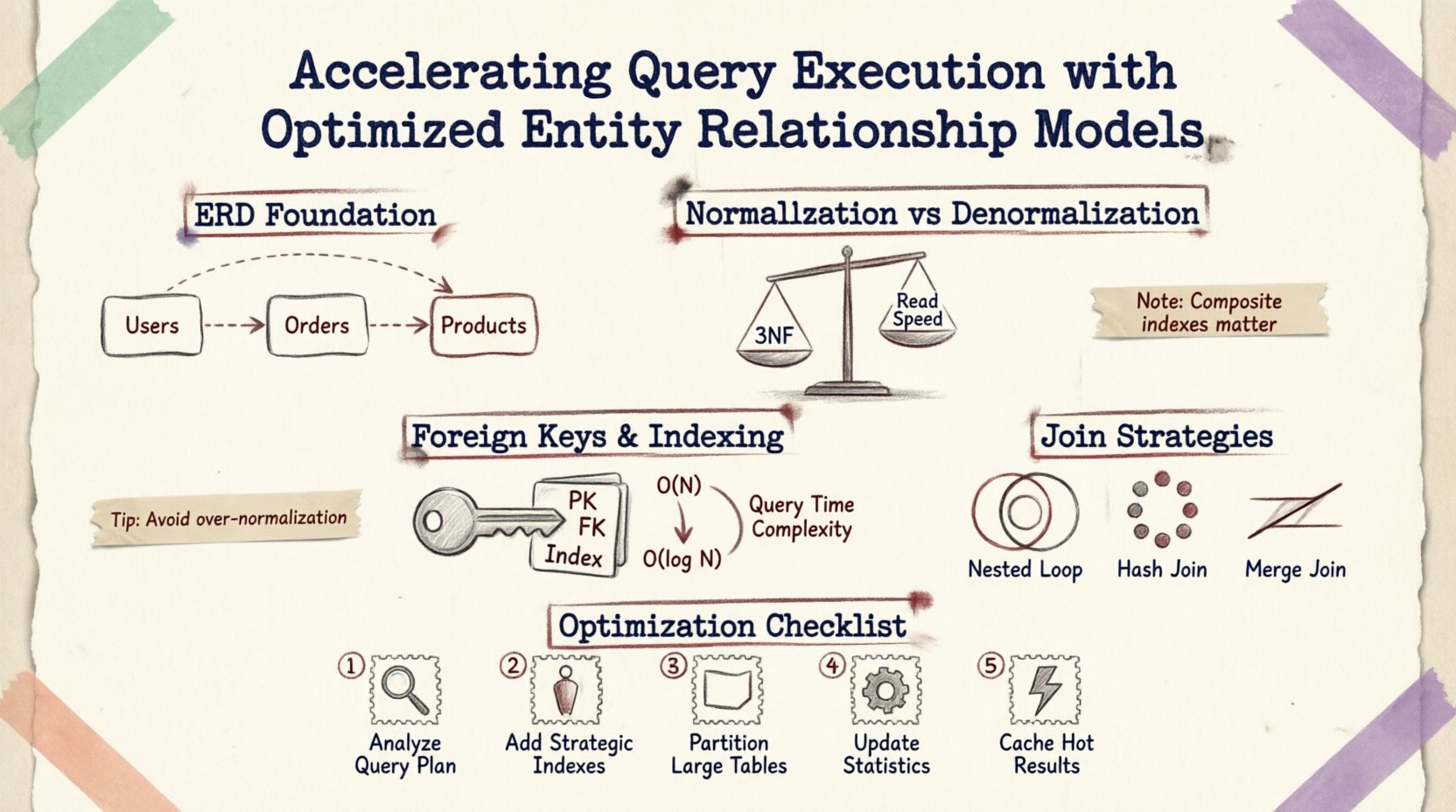
Zrozumienie podstaw: ERD i wydajność 🗃️
Diagram relacji encji to więcej niż pomoc wizualna do dokumentacji; jest to projekt logiki fizycznej przechowywania i pobierania danych. Każda linia narysowana między tabelami reprezentuje ograniczenie klucza obcego, operację łączenia lub regułę integralności danych. Gdy zapytanie jest przesyłane, silnik bazy danych interpretuje te relacje w celu stworzenia planu wykonania.
Zastanów się nad prostym zapytaniem żądającym zamówień użytkownika i szczegółów produktu. Silnik musi:
- Znaleźć tabelę
Użytkownicytabeli. - Śledzić klucz obcy do tabeli
Zamówieniatabeli. - Połączyć tabelę
ElementyZamówieńtabeli. - Dostąpić do tabeli
Produktytabeli poprzez inną relację.
Każdy krok wiąże się z operacjami wejścia/wyjścia i cyklami procesora. Jeśli relacje są źle zdefiniowane, silnik może się odwołać do pełnych skanowań tabel lub zagnieżdżonych pętli łączenia, co znacznie pogarsza wydajność. Optymalizacja ERD zmniejsza dystans, jaki dane muszą przebyć od dysku do pamięci.
Normalizacja vs. Denormalizacja: Znalezienie równowagi ⚖️
Normalizacja to proces organizowania danych w celu zmniejszenia nadmiarowości i poprawy integralności. Choć jest niezbędna dla spójności, nadmierna normalizacja może rozbić dane na wiele małych tabel, co wymaga skomplikowanych łączeń i spowalnia operacje odczytu.
Koszt głębokiej normalizacji
Gdy schemat jest normalizowany do Trzeciej Postaci Normalnej (3NF), dane są przechowywane w najbardziej atomowej formie. Zmniejsza to zużycie przestrzeni pamięci i anomalie aktualizacji. Jednak pobieranie powiązanych danych często wymaga przeszukiwania wielu kluczy obcych.
- Nadmiar łączeń: Każda dodatkowa tabela w łańcuchu łączeń zwiększa złożoność planu zapytania.
- Kontestacja blokad: Dostęp do wielu tabel zwiększa prawdopodobieństwo konfliktów blokad na poziomie wierszy.
- Użycie procesora: Silnik bazy danych musi połączyć zestawy wyników z różnych tabel.
Kiedy denormalizować
Denormalizacja wprowadza nadmiarowość w celu optymalizacji wydajności odczytu. Często jest to konieczne w przetwarzaniu analitycznym lub środowiskach raportowania o wysokim ruchu.
- Obciążenia zdominowane odczytami: Jeśli zapisy są rzadkie w porównaniu do odczytów, dodanie kolumny denormalizowanej pozwala zaoszczędzić operacje łączenia.
- Wstępnie obliczone agregaty: Przechowywanie sum (np.
total_order_value) w tabeli użytkownika pozwala uniknąć obliczania sum przy każdym żądaniu. - Partycjonowanie poziome: Przechowywanie często dostępnego danych razem poprawia lokalizację pamięci podręcznej.
Jednak denormalizacja wymaga starannego zarządzania, aby zapobiec niezgodności danych. Logika aplikacji musi zapewnić, że dane nadmiarowe są aktualizowane za każdym razem, gdy zmienia się dane źródłowe.
Klucze obce i strategia indeksowania 🔑
Ograniczenia kluczy obcych zapewniają integralność referencyjną, ale wiążą się z kosztem wydajności. Bazę danych musi zweryfikować, czy wartość w jednej tabeli istnieje w innej, zanim pozwoli na wstawienie lub aktualizację. Optymalizacja sposobu indeksowania tych kluczy jest kluczowa.
Indeksowanie kluczy obcych
Domyślnie klucze główne są automatycznie indeksowane. Klucze obce jednak często wymagają jawnych indeksów w celu przyspieszenia operacji łączenia. Bez indeksu na kolumnie klucza obcego:
- Baza danych musi wykonać pełne skanowanie tabeli potomnej, aby znaleźć pasujące wiersze.
- Operacje łączenia stają się znacznie wolniejsze, zwłaszcza gdy rozmiary tabel rosną do milionów wierszy.
- Sprawdzanie integralności referencyjnej podczas usuwania staje się kosztowne.
Poprawnie indeksowany klucz obcy pozwala bazie danych używać wyszukiwania po indeksie zamiast skanowania, zmniejszając złożoność z O(N) do O(log N).
Indeksy złożone dla relacji
Gdy wiele kolumn definiuje relację, indeks złożony może być bardziej skuteczny niż osobne indeksy. Na przykład, jeśli zapytanie filtrowane jest według user_id i created_at w tabeli zamówień, indeks złożony na obu kolumnach zapewnia, że silnik może znaleźć dane bez skanowania niepowiązanych rekordów.
Strategie łączenia i plany wykonania 🔍
Struktura ERD wpływa na to, które algorytmy łączenia wybiera optymalizator zapytań. Zrozumienie tych mechanizmów pomaga w projektowaniu schematów sprzyjających efektywnym typom łączeń.
| Typ łączenia | Najlepiej używać, gdy | Wpływ na wydajność |
|---|---|---|
| Łączenie pętli zagnieżdżonych | Małe zestawy wyników lub bardzo selektywne predykaty | Szybkie dla małych danych; powolne przy dużych skanowaniach |
| Połączenie typu Hash | Duże tabele bez indeksów | Wymagające pamięci; dobre dla danych nieposortowanych |
| Połączenie typu Merge | Posortowane dane wejściowe według kluczy połączeń | Bardzo szybkie, jeśli dane są już posortowane |
Projektowanie ERD w taki sposób, aby wspierać posortowane dane wejściowe lub wyszukiwania z indeksów, może zachęcić optymalizator do wyboru szybszych metod połączeń. Na przykład zapewnienie, że klucze połączeń są częścią indeksu skupionego, może ułatwić połączenia typu Merge.
Typowe pułapki w projektowaniu schematu 🚫
Nawet doświadczeni architekci popełniają błędy, które wpływają na szybkość zapytań. Wczesne wykrywanie tych wzorców zapobiega kosztownemu przepisaniu kodu w przyszłości.
- Łańcuchowe klucze obce: Tworzenie łańcucha relacji, w którym tabela A łączy się z B, B z C, a C z D. Zapytania łączące wszystkie cztery tabele stają się głęboko zagnieżdżone i powolne.
- Ciągi zmiennych długości: Używanie
VARCHARdo kluczy o stałej długości może marnować przestrzeń i spowalniać porównania wierszy. - Wiele do wielu bez tabel pośrednich: Próba przechowywania wielu identyfikatorów w jednym kolumnie (np. wartości rozdzielone przecinkami) uniemożliwia właściwe indeksowanie i normalizację.
- Niejawne konwersje: Definiowanie typów danych, które nie są zgodne między tabelami rodzicielskimi a potomkowymi, zmusza silnik do konwersji wartości w czasie wykonywania, uniemożliwiając używanie indeksów.
Prawdziwe kroki w optymalizacji 🛠️
Aby poprawić wykonywanie zapytań bez przepisywania całego systemu, wykonaj te zorganizowane kroki:
- Analiza wzorców zapytań: Przejrzyj najczęstsze operacje odczytu. Zidentyfikuj, które tabele są najczęściej łączone.
- Przejrzyj używanie indeksów: Sprawdź brakujące indeksy na kluczach obcych lub często filtrowanych kolumnach.
- Dokładnij liczność relacji: Upewnij się, że relacje są poprawnie zamodelowane (jeden do jednego vs. jeden do wielu). Niepoprawna liczność może prowadzić do niepotrzebnych połączeń.
- Podziel duże tabele: Jeśli tabela przekracza miliony wierszy, rozważ jej partycjonowanie według daty lub regionu, aby ograniczyć ilość danych skanowanych w jednym zapytaniu.
- Monitorowanie blokad: Używaj narzędzi monitoringu, aby identyfikować długotrwałe zapytania utrzymujące blokady, często spowodowane nieefektywnym przeszukiwaniem schematu.
Rozważania dotyczące przechowywania i pamięci 💾
Fizyczna struktura danych również ma znaczenie. Silniki baz danych przechowują dane w stronicach. Jeśli powiązane wiersze są fizycznie przechowywane blisko siebie, wymagane jest mniejsza liczba odczytów dysku do załadowania zestawu danych.
- Klastrowanie:Układanie danych według wspólnego klucza może poprawić wydajność skanowania zakresu.
- Magazyn kolumnowy w porównaniu z magazynem wierszy:W przypadku zapytań analitycznych magazyn kolumnowy może zapewniać lepszą kompresję i szybsze agregowanie niż tradycyjne modele oparte na wierszach.
- Buforowanie:Projektuj schematy, które umożliwiają skuteczne buforowanie całych zestawów wyników zamiast pojedynczych wierszy.
Ostateczne rozważania dotyczące ewolucji schematu 🔄
Projektowanie schematu to nie jednorazowa czynność. W miarę zmian wymagań aplikacji model danych musi ewoluować. Regularne audyty struktury bazy danych zapewniają, że wydajność pozostaje stała. Dokumentacja modelu relacji encji powinna być utrzymywana razem z kodem źródłowym, aby śledzić, jak zmiany wpływają na system.
Skupiając się na integralności strukturalnej i relacjach logicznych w danych, tworzysz fundament wspierający szybkie wykonywanie zapytań. Celem nie jest budowa statycznego systemu, ale elastycznej architektury, która dostosowuje się do obciążenia bez poświęcania szybkości oczekiwanej przez użytkowników. 📊
Optymalizacja modelu relacji encji to dyscyplina techniczna łącząca teorię baz danych z praktyczną inżynierią. Wymaga cierpliwości, analizy oraz jasnego zrozumienia, jak podłożony silnik przetwarza żądania. Poprawna strategia sprawia, że problemy wydajności stają się zarządzalne, a pobieranie danych staje się płynne.