











Projektowanie wytrzymałyjch schematów baz danych wymaga głębokiego zrozumienia, jak wzajemnie oddziałują ze sobą encje danych. Jednymi z najbardziej złożonych struktur do zarządzania są relacje wiele do wielu. Zdarzają się one wtedy, gdy pojedynczy egzemplarz jednej encji jest powiązany z wieloma egzemplarzami innej encji i odwrotnie. Bez odpowiedniego planowania takie połączenia mogą prowadzić do nadmiarowości danych, problemów z integralnością i poważnych wąskich gardłów wydajnościowych. Niniejszy przewodnik omawia mechanizmy optymalizacji tych relacji w modelach relacji encji (ERMs), aby zapewnić skalowalne i utrzymywalne systemy.
Zrozumienie podstawowego wyzwania 🔍
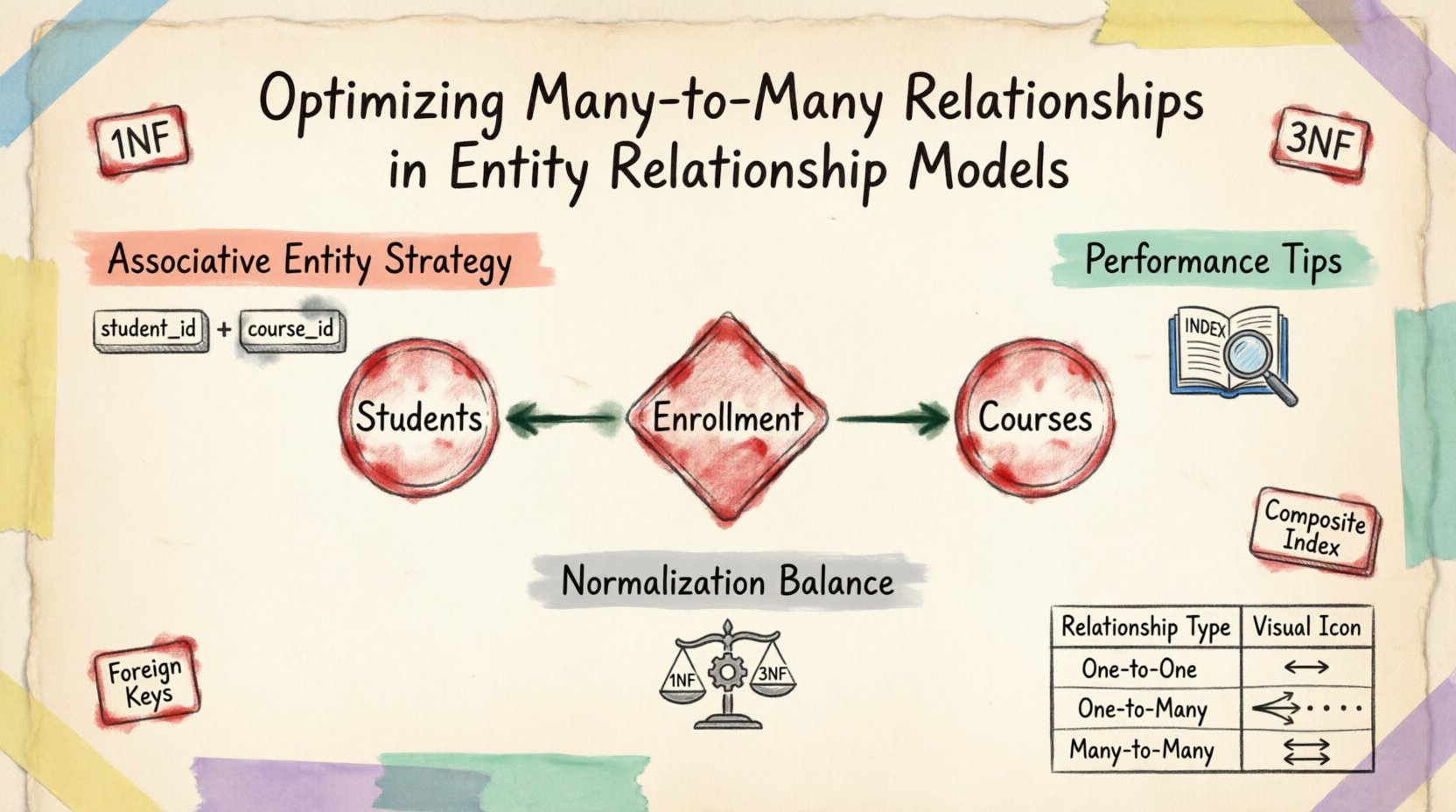
W modelu koncepcyjnym relacja wiele do wielu jest intuicyjna. Pomyśl o studentach i przedmiotach. Student zapisuje się na wiele przedmiotów, a każdy przedmiot ma wielu studentów. Przedstawienie tego bezpośrednio w fizycznym strukturze bazy danych jest problematyczne. Standardowe tabele relacyjne domyślnie obsługują relacje jeden do wielu i jeden do jednego za pomocą kluczy obcych. Relacja wiele do wielu wymaga struktury pośredniej, aby działała poprawnie.
Próba przechowywania wielu identyfikatorów w jednym kolumnie (np. jako lista rozdzielona przecinkami) narusza pierwszą postać normalną (1NF). Ten podejście sprawia, że zapytania, indeksowanie i utrzymanie integralności danych są prawie niemożliwe. Rozwiązaniem jest rozbicie relacji na dwie relacje jeden do wielu za pomocą encji pośredniej, często nazywanej tabelą połączeniową lub mostową.
Strategia encji pośredniej 🧩
Podstawową techniką rozwiązywania relacji wiele do wielu jest wprowadzenie encji pośredniej. Ta encja działa jako most między dwiema tabelami rodzicielskimi. Zawiera klucze główne obu encji rodzicielskich jako klucze obce, tworząc klucz główny złożony, który zapewnia unikalność dla każdego egzemplarza relacji.
- Struktura: Tabela zawiera klucze obce odnoszące się do kluczy głównych powiązanych encji.
- Unikalność: Klucz złożony zapobiega powtarzaniu się relacji między tymi samymi dwoma rekordami.
- Atrybuty: Tabela może przechowywać konkretne dane dotyczące samej relacji, a nie tylko encji.
Pomyśl o scenariuszu łączącym Pracowników i Projekty. Pracownik pracuje nad wieloma projektami, a każdy projekt ma wielu pracowników. Tabela relacji może przechowywać datę przypisania, stanowisko pracownika w danym projekcie lub zaliczone godziny. Te atrybuty należą do relacji, a nie do pracownika ani projektu indywidualnie.
Kroki wdrożenia
- Zidentyfikuj encje: Zdefiniuj dwie różne encje uczestniczące w relacji.
- Utwórz tabelę połączeniową: Utwórz nową tabelę z opisową nazwą, np.
Przypisania_Pracownik_Projekt. - Dodaj klucze obce: Wstaw kolumny dla kluczy głównych obu encji rodzicielskich.
- Zdefiniuj ograniczenia: Ustaw ograniczenia kluczy obcych w celu zapewnienia integralności referencyjnej.
- Indeksowanie: Zastosuj indeksy do kolumn kluczy obcych, aby przyspieszyć operacje łączenia.
Normalizacja i integralność danych 🛡️
Optymalizacja często wiąże się z kompromisem między normalizacją a wydajnością. Choć normalizacja zmniejsza nadmiarowość, nadmiernie znormalizowane struktury mogą wymagać skomplikowanych połączeń, które spowalniają zapytania. Podczas optymalizacji relacji wiele do wielu kluczowe jest zrównoważenie tych czynników.
Trzecia postać normalna (3NF) jest zazwyczaj celem dla baz danych operacyjnych. W tym stanie tabela połączeniowa nie powinna zawierać zależności przechodnich. Każdy atrybut niekluczowy musi zależeć od klucza głównego. Jeśli tabela połączeniowa zawiera dane zależne tylko od jednego z kluczy obcych, powinny one zostać przeniesione do odpowiedniej tabeli rodzicielskiej.
Typowe pułapki normalizacji
- Zbyteczne klucze obce: Włączanie tego samego klucza obcego w wielu tabelach pośrednich bez jasnej hierarchii.
- Brakujące ograniczenia: Nie stosowanie ograniczeń unikalności dla kombinacji kluczy obcych.
- Miękkie usuwanie: Nie uwzględnianie usuniętych rekordów w tabeli relacji, co prowadzi do danych osieroconych.
Strategie optymalizacji wydajności ⚡
Wraz ze wzrostem objętości danych liczba wierszy w tabeli pośredniej może rosnąć wykładniczo. Ma to bezpośredni wpływ na czas wykonywania zapytań. Niektóre strategie mogą zmniejszyć degradację wydajności.
1. Strategiczne indeksowanie
Indeksy są kluczowe dla wydajności połączeń. Indeks złożony na kolumnach kluczy obcych jest często skuteczniejszy niż osobne indeksy. Pozwala to silnikowi bazy danych szybciej znajdować powiązane wiersze bez przeszukiwania całej tabeli.
- Indeksy kluczowe: W niektórych systemach grupowanie tabeli według klucza złożonego może poprawić wykonywanie zapytań zakresowych.
- Indeksy pokrywające: Włączenie często zapytywanych kolumn do indeksu może usunąć potrzebę dostępu do kopca tabeli.
2. Partycjonowanie
Gdy tabela pośrednia staje się zbyt duża, by ją skutecznie zarządzać, partycjonowanie według daty lub regionu może rozłożyć obciążenie. Jest to szczególnie przydatne dla danych historycznych, gdzie nowsze relacje są częściej dostępne niż starsze.
3. Optymalizacja zapytań
Złożone zapytania zawierające wiele połączeń mogą obciążać zasoby. Używanie wskazówek zapytań lub przekształcanie kodu SQL w celu zmniejszenia liczby podzapytań może pomóc. Ważne jest również analizowanie planu wykonania, aby zidentyfikować węzły zatkania.
| Strategia | Zysk | Zalety i wady |
|---|---|---|
| Indeksowanie złożone | Szybsze pobieranie połączeń | Zwiększone zużycie pamięci i obciążenie zapisu |
| Partycjonowanie tabeli | Ulepszona obsługa i szybsze przeszukiwanie | Złożoność logiki zapytań |
| Buforowanie | Zmniejszone obciążenie bazy danych | Ryzyko spójności danych |
Obsługa atrybutów relacji 📝
Jednym z największych zalet encji asocjacyjnej jest możliwość przechowywania atrybutów specyficznych dla relacji. Na przykład w systemie zarządzania umowami, dostawca i produkt mają relację wiele do wielu. Atrybuty mogą obejmować cenę jednostkową, datę rozpoczęcia umowy oraz ilość ustaloną w umowie.
Jeśli spróbujesz przechowywać te atrybuty w tabeli Dostawcy lub Produktu, powstanie nadmiarowość. Jeśli cena się zmieni, będziesz musiał aktualizować wiele wierszy w tabeli produktu. Umieszczając je w tabeli pośredniej, utrzymujesz jednoznaczne źródło prawdy dla konkretnego wystąpienia relacji.
Zaawansowane scenariusze i przypadki graniczne 🌐
Modelowanie danych w rzeczywistych warunkach często stwarza unikalne wyzwania, które standardowe wzorce nie rozwiązuje od razu.
- Relacje samodzielne: Encja powiązana sama z sobą (np. pracownik zarządzający innymi pracownikami). Wymaga to klucza obcego wskazującego na klucz główny tej samej tabeli.
- Usuwanie kaskadowe: Decyzja, czy usunięcie encji nadrzędnej powinno automatycznie usunąć jej rekordy relacji. Zapobiega to pozostawianiu nieprzypisanych kluczy obcych, ale może spowodować utratę danych historycznych dotyczących powiązań.
- Relacje rekurencyjne: Złożone hierarchie, w których tabela pośrednia wskazuje na siebie samą.
Wykonywanie zapytań do optymalizowanego schematu 🔎
Po optymalizacji schematu jego zapytanie wymaga precyzji. Programiści muszą zrozumieć, jak silnik bazy danych przemieszcza się po ścieżkach połączeń.
Podczas pobierania danych, takich jak wszystkie projekty dla konkretnego pracownika, zapytanie musi połączyć tabelę Pracownik z tabelą pośrednią, a następnie z tabelą Projekt. Skuteczne pisanie SQL zapewnia, że baza danych poprawnie wykorzystuje dostępne indeksy. Unikanie funkcji na indeksowanych kolumnach w klauzuliWHEREjest standardową praktyką, aby zachować wykorzystanie indeksów.
Najlepsze praktyki dotyczące logiki połączeń
- Używaj jawnych połączeń: Preferuj
INNER JOINlubLEFT JOINprzed niejawnymi tabelami rozdzielonymi przecinkami. - Ogranicz kolumny: Wybieraj tylko te kolumny, które są niezbędne, aby zmniejszyć transfer danych i czas przetwarzania.
- Filtruj wcześnie: Stosuj filtry w klauzuli
WHEREprzed wykonaniem połączenia, jeśli to możliwe.
Porównywanie typów relacji 📊
Zrozumienie, gdzie pasuje relacja wiele do wielu w szerszym kontekście modelowania danych, pomaga podjąć lepsze decyzje projektowe.
| Typ relacji | Struktura | Przykład użycia |
|---|---|---|
| Jeden do jednego | Jeden klucz obcy | Profil użytkownika i ustawienia użytkownika |
| Jeden do wielu | Jeden klucz obcy | Zamówienie i pozycje zamówienia |
| Wiele do wielu | Tabela pośrednicząca | Studenci i kursy |
Zachowanie spójności danych 🔄
Zapewnienie, że dane pozostają spójne między powiązanymi tabelami, ma najwyższy priorytet. Często wymaga to zarządzania transakcjami. Transakcja powinna obejmować wstawienie danych do tabeli nadrzędnej i do tabeli pośredniczącej. Jeśli którykolwiek krok nie powiedzie się, cała operacja powinna zostać cofnięta, aby zapobiec stanom częściowych danych.
Wyzwalacze mogą również być wykorzystywane do zapewnienia logiki biznesowej, choć powinny być stosowane oszczędnie, aby uniknąć ukrytych kosztów wydajności. Na przykład wyzwalacz może zapobiegać przypisaniu pracownika do projektu, jeśli jego departament nie zgadza się z departamentem projektu.
Monitorowanie i utrzymanie 📈
Po wdrożeniu system wymaga ciągłego monitorowania. Rosnąca liczba rekordów w tabeli pośredniczącej często jest pierwszym oznaką problemów z skalowaniem. Konieczne są regularne audyty rozmiarów tabel, fragmentacji indeksów oraz metryk wydajności zapytań.
- Archiwizacja: Przenieś dane historyczne dotyczące relacji do zimowego magazynu, jeśli nie są już aktywnie wykonywane zapytania.
- Przebudowa indeksów: Okresowo przebuduj lub przeorganizuj indeksy w celu utrzymania optymalnej wydajności.
- Przeglądanie połączeń: Upewnij się, że zmiany w aplikacji nie wprowadzają nieefektywnych wzorców zapytań.
Ostateczne rozważania dotyczące projektowania schematu 🎯
Optymalizacja relacji wiele do wielu nie jest jednorazowym zadaniem, ale ciągłym procesem doskonalenia. Wymaga ona równowagi między poprawnością teoretyczną a wydajnością praktyczną. Przestrzegając zasad normalizacji, wykorzystując encje pośredniczące i stosując strategiczne indeksowanie, architekci baz danych mogą tworzyć systemy zarówno wytrzymałe, jak i wydajne. Celem jest stworzenie struktury, która wspiera logikę biznesową bez nakładania nieuzasadnionych ograniczeń na pobieranie lub modyfikację danych.