











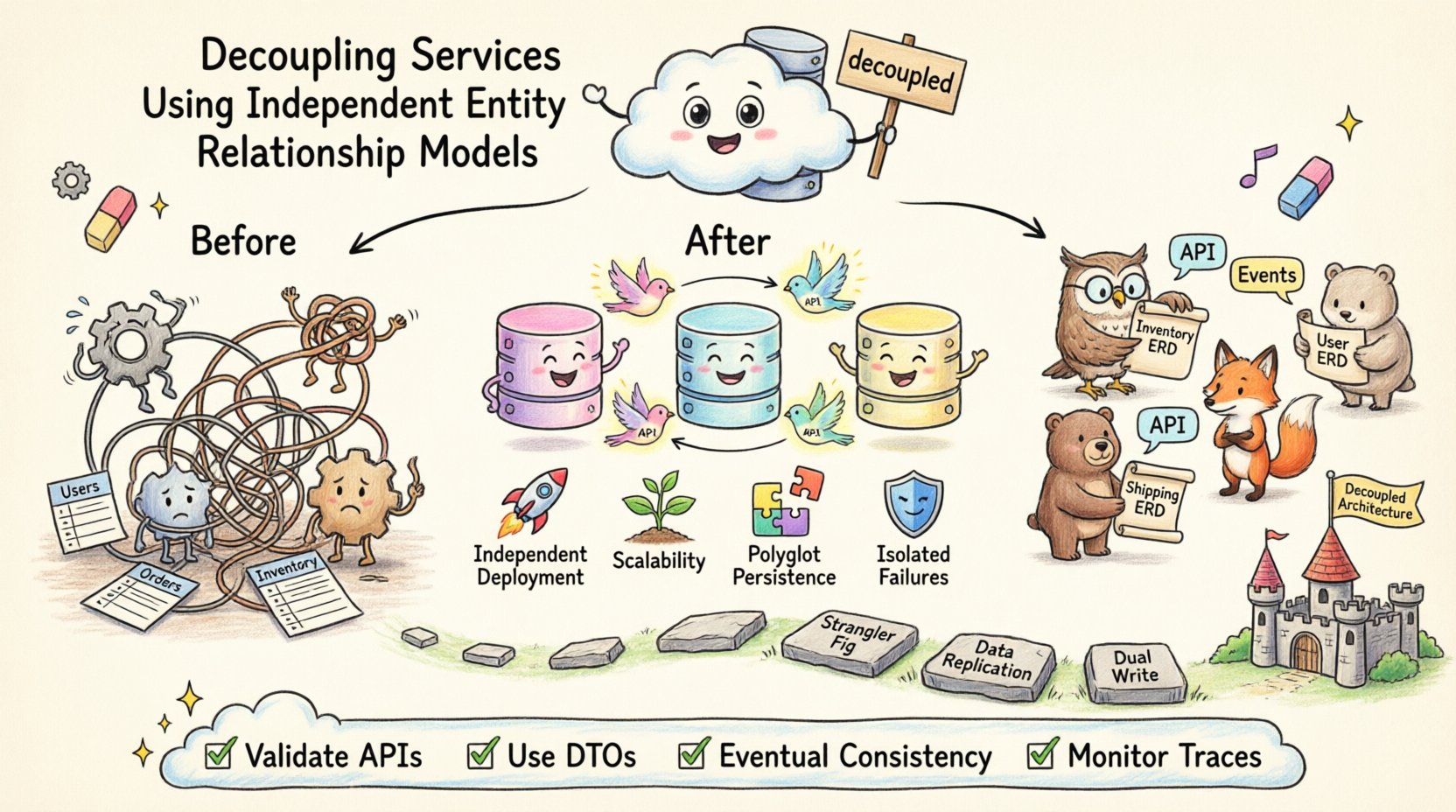
W nowoczesnej architekturze oprogramowania rozdzielenie odpowiedzialności rozciąga się poza logikę kodu na własność danych. Gdy usługi współdzielą pojedynczy schemat bazy danych, nieuchronnie stają się zależne od wewnętrznych implementacji jedna drugiej. Ta silna zależność powoduje niewytrzymałość, ogranicza szybkość wdrażania i komplikuje próby skalowania. Aby osiągnąć prawdziwą moduowość, zespoły muszą przyjąć niezależne modele relacji encji dla każdego granicy usługi. Ten podejście zapewnia, że struktury danych pozostają prywatne dla usługi, która je posiada, wspierając odporność i samodzielność.
🤔 Wyzwanie współdzielonych danych
Stare systemy często opierają się na monolitycznej bazie danych, gdzie wiele modułów aplikacji zapytuje te same tabele. Choć to upraszcza początkowe rozwoju, wprowadza istotne ryzyko wraz z rozwojem systemu. Zmiana wymagań danych w jednym module może uszkodzić funkcjonalność innego modułu, który opiera się na tej samej strukturze tabeli. Ten zjawisko nazywa się antypatologią współdzielonej bazy danych.
Wyobraź sobie sytuację, w której Usługa Użytkownika musi dodać nowe pole do tabeli profilu. Jeśli Usługa Zamówień bezpośrednio zapytuje tę tabelę o imiona użytkowników, aktualizacja może wymagać skoordynowanego wdrożenia lub migracji bazy danych, która jednocześnie wpływa na oba zespoły. Ta nadmierna koordynacja spowalnia innowacje i zwiększa ryzyko incydentów produkcyjnych.
-
Zależności wdrażania:Usługi nie mogą być wdrażane niezależnie, jeśli współdzielą definicje schematów.
-
Ograniczenia skalowalności:Pojedyncza baza danych często staje się węzłem zatkania, gdy konkretne usługi wymagają więcej zasobów niż inne.
-
Ryzyka bezpieczeństwa:Bezpośrednie dostęp do tabel pomija warstwę usługi, co potencjalnie ujawnia wrażliwą logikę danych.
🗺️ Definiowanie niezależnych modeli relacji encji
Niezależny model relacji encji (ERD) przypisuje określony schemat danych do jednej usługi. Oznacza to, że usługa kontroluje własną bazę danych, własne tabele i własne relacje. Inne usługi nie mają bezpośredniego dostępu do tych tabel. Zamiast tego komunikują się poprzez zdefiniowane interfejsy, takie jak API lub kolejki komunikatów.
Ten styl architektoniczny często nazywa sięBaza danych na usługę. Zgodnie z nim własność danych jest zgodna z możliwościami biznesowymi. Na przykład Usługa Inwentarza zarządza poziomami zapasów, podczas gdy Usługa Dostawy zarządza adresami dostawy. Żadna z tych usług nie powinna mieć odniesienia klucza obcego do wewnętrznych tabel drugiej usługi.
Proces obejmuje:
-
Określanie granic:Określ, do której możliwości biznesowej należy dane.
-
Projektowanie lokalnych schematów:Twórz ERD, które wspierają tylko specyficzne potrzeby danej usługi.
-
Definiowanie interfejsów:Ustal, jak dane są wymieniane między usługami bez ujawniania struktur wewnętrznych.
📈 Kluczowe korzyści z izolacji schematu
Przyjęcie niezależnych ERD przekształca sposób, w jaki zespoły zarządzają złożonością. Przesuwa uwagę z centralnego zarządzania na rozproszoną samodzielność. Każdy zespół może optymalizować strategię przechowywania danych, nie martwiąc się o globalne skutki.
|
Aspekt |
Model współdzielonej bazy danych |
Model niezależnych ERD |
|---|---|---|
|
Wdrożenie |
Skoordynowane, ryzykowne |
Niezależne, częste |
|
Skalowalność |
Tylko poziome (klaster) |
Pionowe na usługę |
|
Technologia |
Jeden typ bazy danych |
Polyglotowe przechowywanie danych |
|
Strefa awarii |
Jedno miejsce awarii |
Zizolowane awarie |
🔗 Projektowanie z rozłącznym sprzężeniem
Gdy usługi nie mogą bezpośrednio komunikować się z bazami danych innych usług, muszą komunikować się poprzez interfejsy API. Wymaga to starannego zaprojektowania umowy między usługami. Interfejs API staje się jedyną współdzieloną umową. Jeśli umowa interfejsu API pozostaje stabilna, model danych w tle może ulec zmianie bez wpływu na odbiorców.
Wersjonowanie interfejsu API: Ponieważ modele danych ewoluują, interfejsy API muszą wspierać wersjonowanie. Pozwala to starszym klientom działać, podczas gdy nowe klienty przyjmują zaktualizowane struktury.
Obiekty transferu danych (DTOs): Nie eksponuj bezpośrednio obiektów encji. Twórz specjalne DTOs, które przenoszą tylko dane niezbędne dla odbiorcy. Zapobiega to wyciekom zmian wewnętrznych na zewnątrz.
-
Weryfikacja: Weryfikuj dane wejściowe na granicy interfejsu API, a nie tylko na poziomie bazy danych.
-
Idempotentność: Upewnij się, że operacje mogą być powtarzane bezpiecznie, bez powodowania duplikatów rekordów.
-
Dokumentacja: Utrzymuj jasną dokumentację dla wszystkich formatów wymiany danych.
⚖️ Obsługa transakcji i spójności
Jednym z najważniejszych wyzwań w rozłączaniu jest utrzymanie integralności danych. W wspólnej bazie danych transakcja może łatwo obejmować wiele tabel. W systemie rozproszonym pojedyncza transakcja logiczna może obejmować wiele usług. Nazywa się toProblem transakcji rozproszonych.
Aby to rozwiązać, zespoły często stosująSpójność ostateczna wzorzec. Zamiast zapewniać, że dane są identyczne wszędzie od razu, system zapewnia, że stają się spójne z czasem. Jest to osiągane za pomocą komunikacji asynchronicznej.
Wzorzec Saga: Saga to ciąg lokalnych transakcji. Każda transakcja aktualizuje bazę danych i publikuje zdarzenie, które uruchamia następną transakcję. Jeśli krok nie powiedzie się, wykonywane są transakcje kompensacyjne w celu cofnięcia poprzednich zmian.
-
Wzorzec Outbox: Zapisz zdarzenia do lokalnej tabeli wraz z główną zmianą danych. Proces działający w tle publikuje te zdarzenia, zapewniając, że żadne dane nie zostaną utracone.
-
Konsumenty idempotentne: Obsługiwiarki komunikatów muszą bezpiecznie obsługiwać powtarzające się komunikaty.
-
Działania kompensacyjne: Zdefiniuj jasną logikę cofnięcia dla każdej akcji w przód.
🚚 Strategie migracji
Przejście od wspólnej bazy danych do niezależnych ERD to znaczące przedsięwzięcie. Wymaga ono krokowego podejścia w celu zmniejszenia ryzyka. Przyspieszanie migracji może prowadzić do utraty danych lub awarii usług.
Wzorzec Strangler Fig: Stopniowo przenieś funkcjonalność do nowych usług. Zacznij od określonej funkcji, takiej jak powiadomienia użytkowników. Stwórz nową usługę z własnym ERD dla tej funkcji. Przekieruj ruch do nowej usługi, jednocześnie utrzymując działanie systemu dziedzicznego.
Replikacja danych: Podczas przejścia możesz potrzebować utrzymać synchronizację danych między starymi a nowymi bazami danych. Pozwala to nowej usłudze tymczasowo odczytywać dane z systemu starego, podczas gdy wypełnia swoją własną bazę.
Podwójny zapis: Zapisz jednocześnie do starej i nowej bazy danych w trakcie okna migracji. Upewnij się, że nowa usługa działa poprawnie, zanim wyłączysz zapisy do starej bazy.
🔍 Monitorowanie i utrzymanie
Przy niezależnych magazynach danych monitorowanie staje się bardziej złożone. Nie patrzysz już na jedno panele zdrowia bazy danych. Musisz agregować dzienniki i metryki z wielu źródeł.
Śledzenie rozproszone: Wprowadź śledzenie, aby śledzić żądanie w miarę jego przepływu przez różne usługi. Pomaga to zidentyfikować, która usługa powoduje opóźnienia lub błędy.
Rejestr schematów: Utrzymuj rejestr kontraktów interfejsów API. Zapewnia to, że każda zmiana modelu danych zostanie przejrzana i zaakceptowana przed wdrożeniem.
-
Powiadomienia: Ustaw ostrzeżenia dla opóźnień replikacji i zatorów kolejek komunikatów.
-
Planowanie pojemności: Monitoruj wzrost pojemności magazynowania dla każdej usługi, aby zapobiec nieoczekiwanym kosztom.
-
Strategie kopii zapasowych: Upewnij się, że każda usługa ma własny plan kopii zapasowej i odzyskiwania.
🛠️ Najczęstsze pułapki do uniknięcia
Nawet przy solidnym planie zespoły często napotykają trudności podczas wdrażania. Zrozumienie tych typowych błędów może zaoszczędzić znaczny czas i wysiłek.
-
Ukryte sprzężenie:Unikaj używania widoków baz danych lub współdzielonych tabel, nawet jeśli znajdują się w osobnych schematach. Bezpośredni dostęp do bazy danych powinien być zabroniony.
-
Zbyt duża fragmentacja:Nie twórz nowej bazy danych dla każdej małej funkcji. Grupuj powiązane encje w logiczne usługi.
-
Ignorowanie opóźnień:Wywołania sieciowe są wolniejsze niż lokalne zapytania. Projektuj interfejsy API w taki sposób, aby minimalizować liczbę przejść.
-
Złożone zapytania:Unikaj łączeń między usługami. Jeśli potrzebujesz danych z wielu usług, pobieraj je oddzielnie i łączy wyniki na poziomie warstwy aplikacji.
🧱 Ostateczne rozważania
Odrzucenie usług przy użyciu niezależnych modeli relacji encji to decyzja strategiczna, która się opłaca w długiej perspektywie. Wymaga ona dyscypliny w projektowaniu oraz gotowości do zarządzania rozproszoną złożonością. Jednak efektem jest system łatwiejszy do skalowania, bardziej odporny na awarie oraz szybszy w ewolucji. Dzięki posiadaniu własnych danych usługi zdobywają niezależność potrzebną do innowacji bez ciągłej koordynacji.
Zacznij od identyfikacji najważniejszych granic w swoim systemie. Najpierw izoluj dane dla tych usług. Doskonal swoje kontrakty interfejsów API i wzorce komunikacji w miarę postępu. Ta stopniowa metoda zapewnia stabilność podczas dążenia do architektury całkowicie odrzuconej.