Designing a robust data architecture requires more than just drawing boxes and lines. It demands a deep understanding of how data flows, grows, and interacts over time. When a system scales, the Entity Relationship Model (ERD) serves as the blueprint for logical consistency, while partitioning strategies address physical performance. Aligning these two aspects is critical for maintaining query speed, data integrity, and operational efficiency. This guide explores how to harmonize partitioning techniques with your existing data models without introducing unnecessary complexity or risk.
🧩 The Foundation: ERD as a Blueprint
Before considering how to split data, one must understand the relationships that bind it. An ERD defines entities, attributes, and the cardinality between them. These relationships dictate how data is retrieved and joined. When you introduce partitioning, you are essentially distributing these logical relationships across physical storage boundaries.
Consider the following implications of partitioning on your schema:
- Primary Keys: Must be carefully chosen to ensure even distribution across partitions.
- Foreign Keys: Joining tables in different partitions can incur significant overhead.
- Indexes: Global indexes may become bottlenecks if not designed with the partition key in mind.
- Data Locality: Related data should ideally reside on the same node to minimize network latency.
Ignoring these factors can lead to a scenario where the logical model works perfectly in design, but the physical implementation struggles under load. The goal is to keep related data close together while allowing independent growth.
🔄 Partitioning Types & Schema Fit
Different partitioning methods suit different data access patterns. Selecting the right method depends heavily on how your ERD defines the relationships and the query patterns expected. Below is a breakdown of common strategies and how they interact with relational structures.
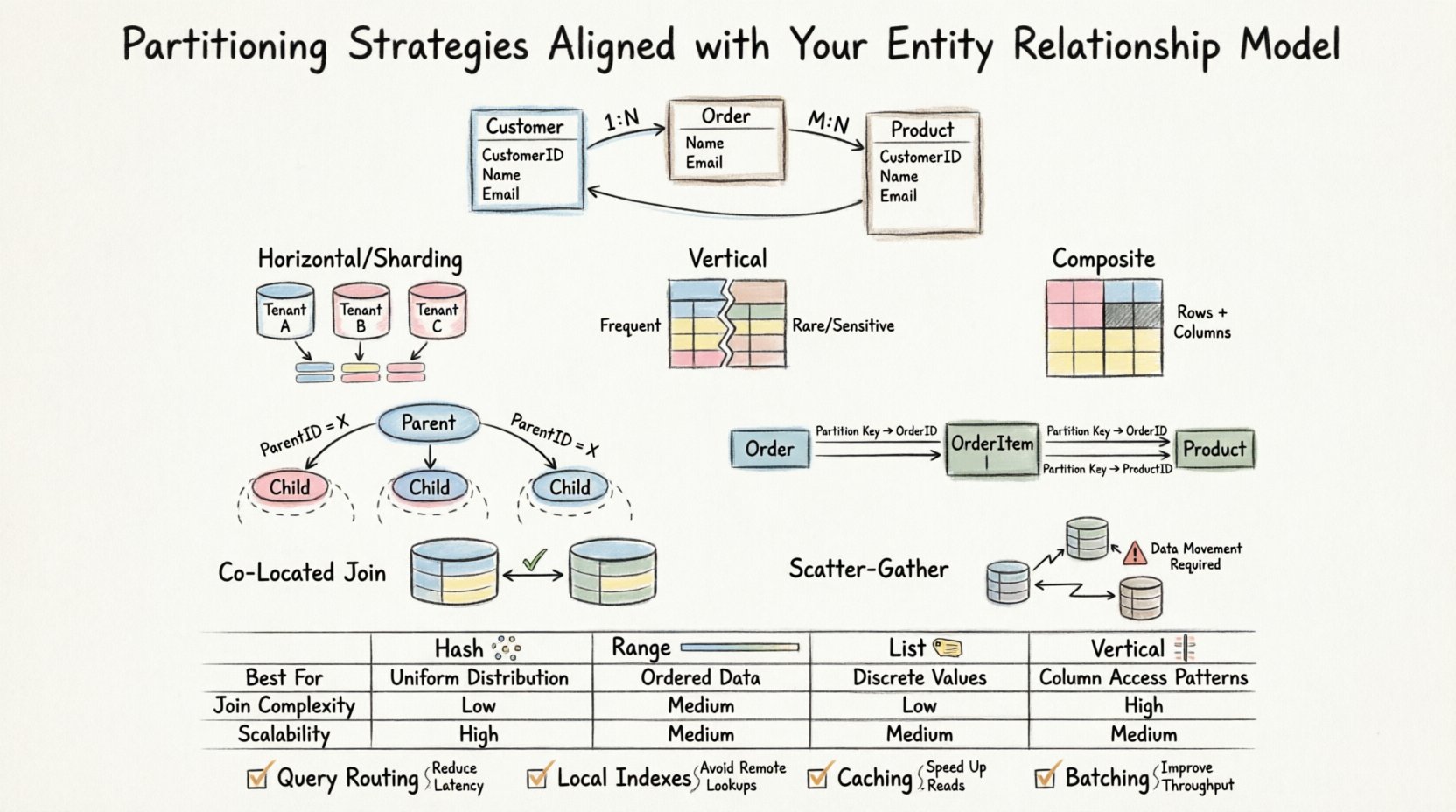
Horizontal Partitioning (Sharding)
Horizontal partitioning splits rows of a table into different groups. This is often used when tables become too large to manage in a single instance. In the context of an ERD, this strategy works best when the partition key correlates with the natural access pattern.
- Use Case: Large transactional tables with distinct user or tenant groups.
- ERD Impact: Foreign keys pointing to a parent table must be managed carefully. If the parent is also partitioned, the keys must align.
- Benefit: Allows for massive scale-out by adding more nodes.
- Challenge: Complex queries spanning multiple partitions require aggregation logic.
Vertical Partitioning
Vertical partitioning splits columns of a table into different groups. This is useful when specific columns are rarely accessed together or when sensitive data needs isolation.
- Use Case: Tables with wide rows where only a subset of columns is queried frequently.
- ERD Impact: The primary key must exist on all vertical partitions to allow reconstruction of the full row.
- Benefit: Reduces I/O by loading only necessary columns into memory.
- Challenge: Joins are required to reconstruct the full entity, adding query complexity.
Composite Partitioning
This approach combines horizontal and vertical strategies. It is often necessary for high-performance systems where both row volume and column width are significant constraints.
- Use Case: Data warehousing or high-frequency trading logs.
- ERD Impact: Requires a rigid schema definition before implementation.
🔑 Aligning Keys with Relationships
The most critical step in this process is selecting the partition key. This key determines which row goes to which physical storage unit. In a relational context, the partition key should ideally match the Foreign Key relationships.
Parent-Child Relationships
When dealing with one-to-many relationships, the child table often grows much faster than the parent. If you partition the child table by the parent ID, all related child records reside on the same node.
- Advantage: Queries retrieving the parent and all children require no cross-node communication.
- Advantage: Deletes cascade efficiently within a single partition.
- Warning: If one parent has significantly more children than others, data skew can occur.
Many-to-Many Relationships
Many-to-many relationships typically involve a junction table. This table can become a performance bottleneck if not partitioned correctly.
- Strategy: Partition by one of the foreign keys involved.
- Strategy: Ensure queries always filter by the partition key to avoid full table scans.
- Strategy: Avoid joining junction tables across multiple partitions unless absolutely necessary.
⚖️ Handling Join Operations
Joins are the lifeblood of relational databases, but they become expensive when data is split. Understanding how joins behave across partitions is essential for maintaining performance.
Co-Located Partitions
If Table A and Table B are partitioned by the same key (e.g., Tenant_ID), a join between them happens locally. The database engine does not need to move data between nodes.
- Requirement: Both tables must use the same partitioning algorithm and key.
- Requirement: The ERD must support this alignment logically.
Scatter-Gather Joins
When tables are partitioned differently, the system must fetch data from multiple nodes, aggregate the results, and then return the final set. This is known as a scatter-gather operation.
- Performance Cost: High network overhead.
- Performance Cost: Increased latency.
- Recommendation: Minimize these joins in the ERD design phase.
🛡️ Maintaining Integrity Across Partitions
Data integrity constraints are harder to enforce when data is distributed. The ERD defines these rules logically, but the implementation must handle the physical distribution.
- Referential Integrity: Ensuring a child record exists before inserting a parent record is complex if they reside on different nodes.
- Unique Constraints: Global uniqueness requires coordination across all partitions.
- Triggers: Application-level triggers often replace database-level triggers in distributed environments to avoid locking issues.
- Transactions: Distributed transactions can impact throughput. Keep transactions local to a single partition whenever possible.
📊 Partitioning Strategy Comparison
The following table summarizes how different strategies interact with common ERD scenarios.
| Strategy | Best For ERD Scenario | Join Complexity | Write Scalability |
|---|---|---|---|
| Hash Partitioning | Uniform distribution needed, no specific range | High (Random distribution) | High |
| Range Partitioning | Date-based or sequential IDs | Low (if aligned) | Medium |
| List Partitioning | Fixed categories (e.g., Region, Status) | Low (if aligned) | High |
| Vertical Partitioning | Wide rows, infrequent columns | Medium (Requires reconstruction) | High |
🔄 Evolution and Migration
Schema evolution is inevitable. Business requirements change, and new attributes are added. When modifying an ERD, the partitioning strategy must be reviewed.
- Adding Columns: Vertical partitioning makes adding columns easier, as they can be placed on a new partition.
- Changing Keys: Re-partitioning existing data is a heavy operation. Plan for this during the initial design.
- Archiving: Partitioning allows for easy archiving of old data ranges without impacting active partitions.
- Monitoring: Regularly check partition sizes to ensure no single partition becomes a hotspot.
🚀 Performance Optimization Tips
To ensure the system remains responsive, specific optimizations should be applied alongside the partitioning strategy.
- Query Routing: Ensure applications send queries to the correct partition node based on the partition key.
- Indexing: Local indexes are faster than global indexes. Design indexes to match the partition key.
- Caching: Frequently accessed lookup tables should not be partitioned if they are small enough to fit in memory on all nodes.
- Batching: Batch inserts and updates to reduce transaction overhead across partitions.
🔍 Final Considerations
Building a system that scales requires balancing logical clarity with physical constraints. The Entity Relationship Model provides the rules for data consistency, while partitioning provides the mechanism for growth. When these two are aligned, the system remains performant even as data volume increases exponentially.
Focus on the relationships defined in your model. If the data is naturally grouped by a specific attribute, use that attribute as your partition key. If joins are frequent, ensure the related tables share the same partitioning logic. Avoid over-complicating the schema with partitions that do not serve a clear performance purpose.
By adhering to these principles, you create a foundation that supports long-term stability. The goal is not just to store data, but to structure it in a way that allows the system to adapt to future demands without requiring a complete overhaul. Careful planning during the design phase saves significant engineering effort during operations.