Designing robust database schemas requires a deep understanding of how data entities interact. Among the most complex structures to manage are many-to-many relationships. These scenarios occur when a single instance of one entity is associated with multiple instances of another, and vice versa. Without proper planning, these connections can lead to data redundancy, integrity issues, and significant performance bottlenecks. This guide explores the mechanics of optimizing these relationships within Entity Relationship Models (ERMs) to ensure scalable and maintainable systems.
Understanding the Core Challenge 🔍
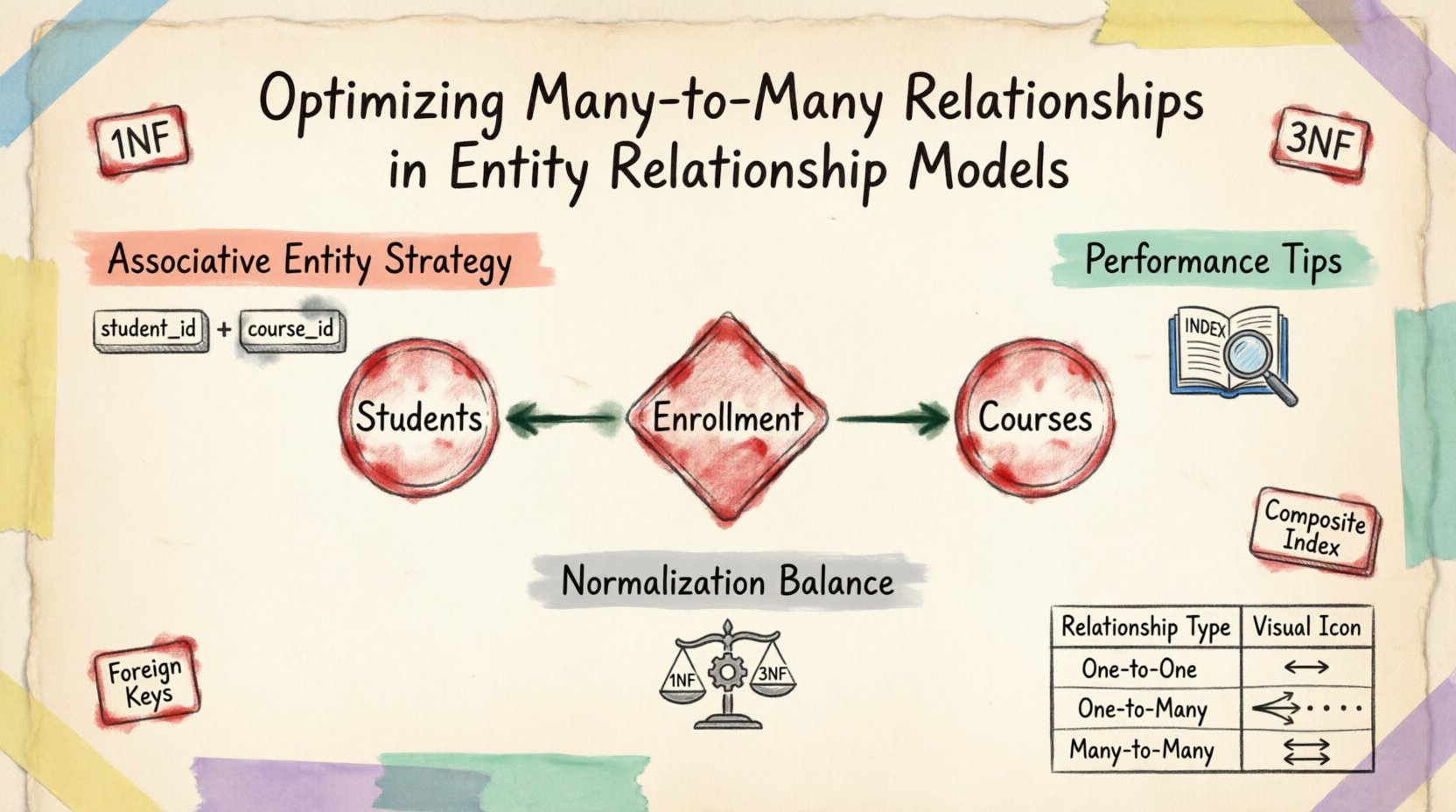
In a conceptual model, a many-to-many relationship is intuitive. Think of students and courses. A student enrolls in multiple courses, and each course has multiple students. Representing this directly in a physical database structure is problematic. Standard relational tables support one-to-many and one-to-one relationships natively through foreign keys. A many-to-many relationship requires an intermediary structure to function correctly.
Attempting to store multiple IDs in a single column (e.g., a comma-separated list) violates First Normal Form (1NF). This approach makes querying, indexing, and maintaining data integrity nearly impossible. The solution lies in breaking the relationship into two one-to-many relationships via an associative entity, often called a junction table or bridge table.
The Associative Entity Strategy 🧩
The fundamental technique for resolving many-to-many relationships is the introduction of an associative entity. This entity acts as a bridge between the two parent tables. It contains primary keys from both parent entities as foreign keys, creating a composite primary key that ensures uniqueness for each relationship instance.
- Structure: The table includes foreign keys referencing the primary keys of the related entities.
- Uniqueness: A composite key prevents duplicate relationships between the same two records.
- Attributes: This table can store specific data about the relationship itself, not just the entities.
Consider a scenario linking Employees and Projects. An employee works on many projects, and a project has many employees. The relationship table might store the assignment date, the role of the employee on that project, or the hours allocated. These attributes belong to the relationship, not the employee or the project individually.
Implementation Steps
- Identify Entities: Define the two distinct entities involved in the relationship.
- Create Junction Table: Generate a new table with a descriptive name, such as
Employee_Project_Assignments. - Add Foreign Keys: Insert columns for the primary keys of both parent entities.
- Define Constraints: Set up foreign key constraints to enforce referential integrity.
- Indexing: Apply indexes to foreign key columns to speed up join operations.
Normalization and Data Integrity 🛡️
Optimization often involves a trade-off between normalization and performance. While normalization reduces redundancy, overly normalized structures can require complex joins that slow down queries. When optimizing many-to-many relationships, it is crucial to balance these factors.
Third Normal Form (3NF) is generally the target for operational databases. In this state, the junction table should not contain transitive dependencies. Every non-key attribute must depend on the primary key. If a junction table contains data that depends only on one of the foreign keys, it should be moved to the respective parent table.
Common Normalization Pitfalls
- Redundant Foreign Keys: Including the same foreign key in multiple junction tables without a clear hierarchy.
- Missing Constraints: Failing to enforce unique constraints on the combination of foreign keys.
- Soft Deletes: Not accounting for deleted records in the relationship table, leading to orphaned data.
Performance Optimization Strategies ⚡
As data volume grows, the number of rows in a junction table can increase exponentially. This directly impacts query execution times. Several strategies can mitigate performance degradation.
1. Strategic Indexing
Indexes are critical for join performance. A composite index on the foreign key columns is often more effective than individual indexes. This allows the database engine to locate related rows faster without scanning the entire table.
- Clustered Indexes: In some systems, clustering the table by the composite key can improve range queries.
- Covering Indexes: Including frequently queried columns in the index can eliminate the need to access the table heap.
2. Partitioning
When a junction table becomes too large to manage efficiently, partitioning by date or region can distribute the load. This is particularly useful for historical data where recent relationships are accessed more frequently than older ones.
3. Query Optimization
Complex queries involving multiple joins can strain resources. Using query hints or restructuring the SQL to minimize subqueries can help. It is also important to analyze the execution plan to identify bottlenecks.
| Strategy | Benefit | Trade-off |
|---|---|---|
| Composite Indexing | Faster join retrieval | Increased storage and write overhead |
| Table Partitioning | Improved maintenance and scan speed | Complexity in query logic |
| Caching | Reduced database load | Data consistency risks |
Handling Relationship Attributes 📝
One of the greatest advantages of the associative entity is the ability to store attributes specific to the relationship. For example, in a contract management system, a Vendor and a Product have a many-to-many relationship. The attributes might include the unit price, the start date of the contract, and the quantity agreed upon.
If you attempt to store these attributes in the Vendor or Product table, you create redundancy. If the price changes, you would have to update multiple rows in the product table. By placing them in the junction table, you maintain a single source of truth for that specific relationship instance.
Advanced Scenarios and Edge Cases 🌐
Real-world data modeling often presents unique challenges that standard patterns do not cover immediately.
- Self-Referencing Relationships: An entity related to itself (e.g., an Employee managing other Employees). This requires a foreign key pointing to the same table’s primary key.
- Cascading Deletes: Deciding whether deleting a parent entity should automatically remove its relationship records. This prevents orphaned foreign keys but may lose historical association data.
- Recursive Relationships: Complex hierarchies where the junction table points back to itself.
Querying the Optimized Schema 🔎
Once the schema is optimized, querying it requires precision. Developers must understand how the database engine traverses the join paths.
When retrieving data, such as all projects for a specific employee, the query must join the Employee table to the Junction table, and then to the Project table. Efficient SQL writing ensures that the database uses the available indexes correctly. Avoiding functions on indexed columns in the WHERE clause is a standard practice to maintain index utilization.
Best Practices for Join Logic
- Use Explicit Joins: Prefer
INNER JOINorLEFT JOINover implicit comma-separated tables. - Limit Columns: Select only the necessary columns to reduce network transfer and processing time.
- Filter Early: Apply filters in the
WHEREclause before the join occurs if possible.
Comparing Relationship Types 📊
Understanding where many-to-many fits in the broader context of data modeling helps in making better design decisions.
| Relationship Type | Structure | Use Case Example |
|---|---|---|
| One-to-One | Single Foreign Key | User Profile and User Settings |
| One-to-Many | Single Foreign Key | Order and Order Items |
| Many-to-Many | Junction Table | Students and Courses |
Maintaining Data Consistency 🔄
Ensuring that the data remains consistent across related tables is paramount. This often involves transaction management. A transaction should wrap the insertion of data into the parent table and the junction table. If either step fails, the entire operation should roll back to prevent partial data states.
Triggers can also be employed to enforce business logic, though they should be used sparingly to avoid hidden performance costs. For instance, a trigger could prevent an employee from being assigned to a project if their department does not match the project’s department.
Monitoring and Maintenance 📈
Once deployed, the system requires ongoing monitoring. Growth in the junction table is often the first sign of scaling issues. Regular audits of table sizes, index fragmentation, and query performance metrics are necessary.
- Archiving: Move historical relationship data to cold storage if it is no longer actively queried.
- Reindexing: Periodically rebuild or reorganize indexes to maintain optimal performance.
- Reviewing Joins: Ensure that application changes do not introduce inefficient query patterns.
Final Thoughts on Schema Design 🎯
Optimizing many-to-many relationships is not a one-time task but a continuous process of refinement. It requires a balance between theoretical correctness and practical performance. By adhering to normalization principles, utilizing associative entities, and applying strategic indexing, database architects can build systems that are both robust and efficient. The goal is to create a structure that supports the business logic without imposing unnecessary constraints on data retrieval or modification.