Database performance often hinges on factors invisible to the casual observer. One such critical factor is lock contention. When multiple users or processes attempt to access the same data simultaneously, the system must enforce rules to maintain data integrity. These rules result in locks. Excessive locking leads to bottlenecks, slowing down response times and frustrating end users. The root cause often lies not in the hardware, but in the Entity-Relationship Diagram (ERD) that defines the data structure.
A well-designed schema acts as the foundation for high concurrency. By anticipating how data will be accessed and modified, architects can structure tables to minimize conflicts. This approach requires a deep understanding of transaction isolation, indexing strategies, and the physical mechanics of locking. The following guide details how to optimize your data model for better performance without relying on external tools.
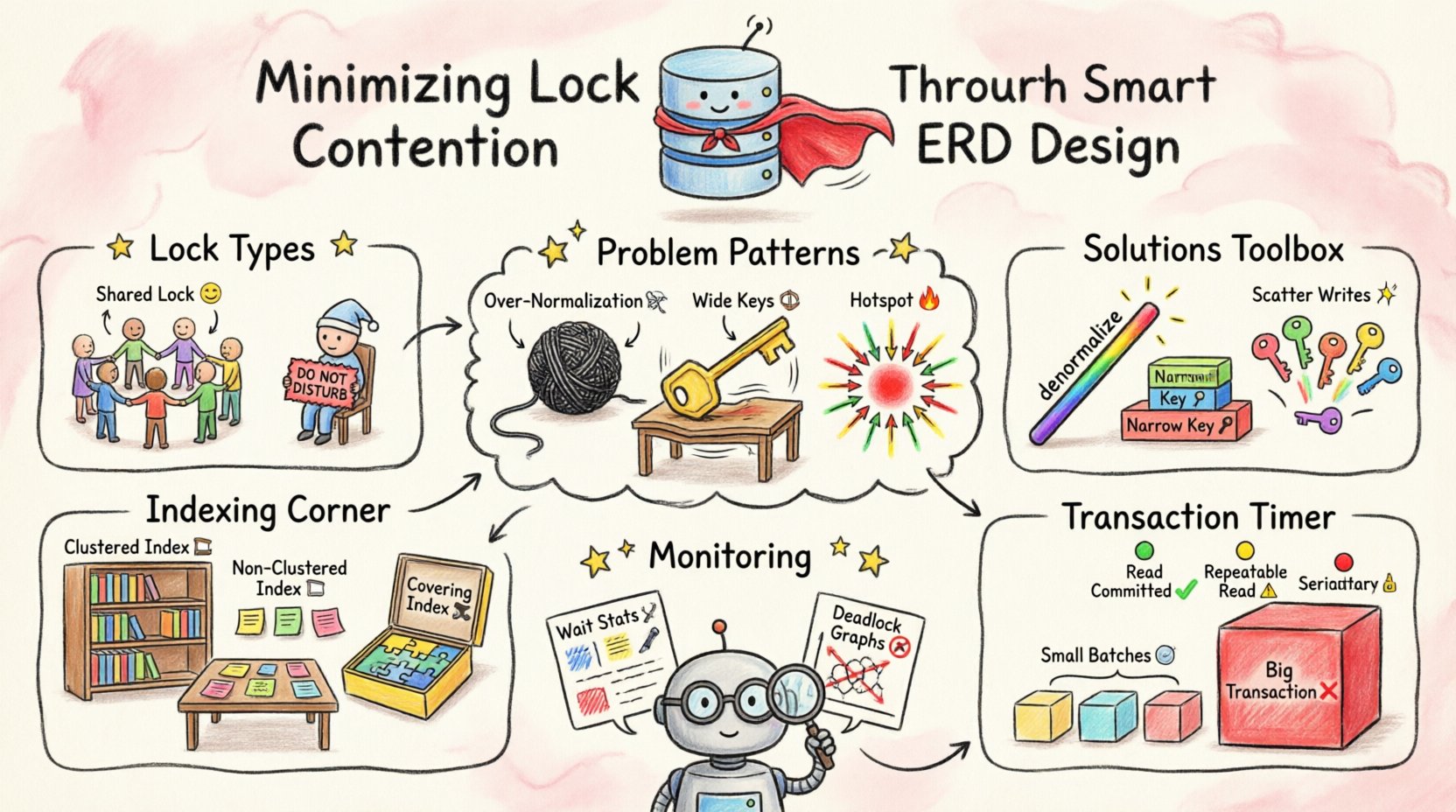
Understanding Locking Mechanisms 🛡️
Before optimizing the design, it is essential to understand what locks actually do. Databases use locks to prevent inconsistencies. If two transactions try to update the same row at the exact same moment, a conflict occurs. The system must decide who goes first.
- Shared Locks (S): Used for reading data. Multiple transactions can hold shared locks on the same resource simultaneously.
- Exclusive Locks (X): Used for writing or modifying data. Only one transaction can hold an exclusive lock on a resource at any time.
- Intent Locks: Indicate that a transaction intends to place a lock on a lower level of the hierarchy, such as a table or page.
Lock contention arises when the demand for exclusive locks exceeds the capacity for shared access. If your ERD forces the database to scan large portions of a table to find data, it increases the scope of locks held. This amplifies the likelihood of collisions between concurrent processes.
Schema Patterns That Trigger Contention 📉
Certain design choices inherently increase the surface area for locking. Recognizing these patterns allows you to refactor early in the development lifecycle.
1. Over-Normalization
While normalization reduces redundancy, excessive normalization can hurt performance. Joining many tables to retrieve a single record requires locking multiple rows across multiple tables. If a transaction needs to read data from five normalized tables, it acquires locks on all of them.
- The Risk: If another transaction modifies one of those tables, the first transaction may wait.
- The Fix: Consider denormalizing frequently joined columns. Reducing the number of joins reduces the number of locks required per query.
2. Wide Primary Keys
Primary keys are used to identify rows uniquely. If a primary key is a composite key spanning multiple columns, it affects how indexes are built. Wide keys increase the size of the index.
- The Risk: Larger indexes mean more pages to read and lock during searches. Updates to the primary key can trigger cascading changes in related tables.
- The Fix: Use simple, narrow surrogate keys (like integers) where possible. Keep composite keys minimal and only when logically necessary.
3. Hotspots in Sequential Keys
Using auto-incrementing integers for primary keys is common. However, if the application inserts data sequentially, all new writes target the end of the index. This creates a “hotspot” where many transactions compete for the same leaf page.
- The Risk: The database engine must lock the last page of the index for every new insertion.
- The Fix: Use randomizing keys or hash-based distributions for high-write scenarios to spread the load across different pages.
Strategies for Schema Optimization 🛠️
Optimizing the ERD involves making specific choices about columns, relationships, and constraints. The table below outlines common design decisions and their impact on locking behavior.
| Design Decision | Impact on Locking | Recommended Approach |
|---|---|---|
| Foreign Key Constraints | Can cause cascading locks on parent tables. | Use deferred constraints or application-level validation for high-write systems. |
| Large BLOB/Text Columns | Increases row size, requiring more pages per row. | Store large data separately to keep the main table narrow. |
| High Cardinality Columns | Can lead to inefficient index usage. | Ensure selective columns are indexed to avoid table scans. |
| Default Values | Updates rows unnecessarily if defaults are applied. | Allow NULLs where appropriate to avoid write triggers. |
Decoupling Write and Read Models
Separating the schema used for writing from the schema used for reading can significantly reduce contention. Write models focus on integrity and normalization. Read models focus on speed and denormalization.
- Store data in a highly normalized structure for transaction processing.
- Replicate data to a read-optimized structure for reporting or display.
- This ensures that heavy read queries do not block write operations.
Indexing and Key Choices 📊
Indexes are vital for performance, but they are not free. Every index must be maintained during an update. If a table has too many indexes, every insert or update requires locking multiple index structures.
Clustered vs. Non-Clustered
- Clustered Index: Determines the physical order of data. There is typically only one per table. Choose this carefully as it impacts how data is stored.
- Non-Clustered Index: A separate structure pointing to data. Useful for covering queries without touching the main table.
Avoid creating indexes on columns that are frequently updated. When a column value changes, the index must be rebuilt. This process generates write locks on the index structure.
Covering Indexes
A covering index includes all the columns needed for a query. This allows the database to satisfy the request without looking up the actual table data. This reduces the scope of locks held, as the engine does not need to lock the base table rows.
- Identify frequent read queries.
- Create indexes that include the
SELECTcolumns. - Monitor query execution plans to ensure these indexes are being utilized.
Transaction Scope and Isolation ⏱️
The ERD influences how transactions behave. Long-running transactions hold locks for longer periods. A well-structured schema helps keep transactions short.
Batch Processing
Instead of processing thousands of rows in a single transaction, break the work into smaller batches. This releases locks sooner, allowing other processes to proceed.
- Limit the number of rows modified per commit.
- Use cursors or loops to process data in chunks.
- Balance the overhead of multiple commits against the benefit of reduced lock duration.
Isolation Levels
Database systems offer different isolation levels. Higher isolation levels (like Serializable) prevent more anomalies but increase locking. Lower isolation levels (like Read Committed) allow more concurrency.
- Avoid Serializable unless strictly necessary for financial accuracy.
- Use Read Committed or Repeatable Read for most operational tasks.
- Align the isolation level with the business requirement for data consistency.
Monitoring and Iteration 🔄
Design is not a one-time activity. As usage patterns change, so do lock contention issues. Continuous monitoring is required to maintain performance.
- Wait Statistics: Track how long transactions wait for locks.
- Deadlock Graphs: Analyze diagrams that show which queries caused deadlocks.
- Query Performance: Identify slow queries that might be holding locks longer than expected.
Regularly review the ERD against current performance metrics. If a specific table consistently shows high wait times, consider partitioning the data or adjusting the schema to reduce the load.
Final Thoughts on Data Architecture 🧩
Minimizing lock contention is a balance between data integrity and system throughput. By designing schemas with concurrency in mind, you reduce the need for the database engine to resolve conflicts. This leads to faster response times and a more stable system.
Start by auditing your current relationships and keys. Look for opportunities to simplify joins and reduce index bloat. Test your changes in a staging environment to verify the impact on locking behavior. With careful planning and attention to detail, you can build a robust data layer that scales effectively.