
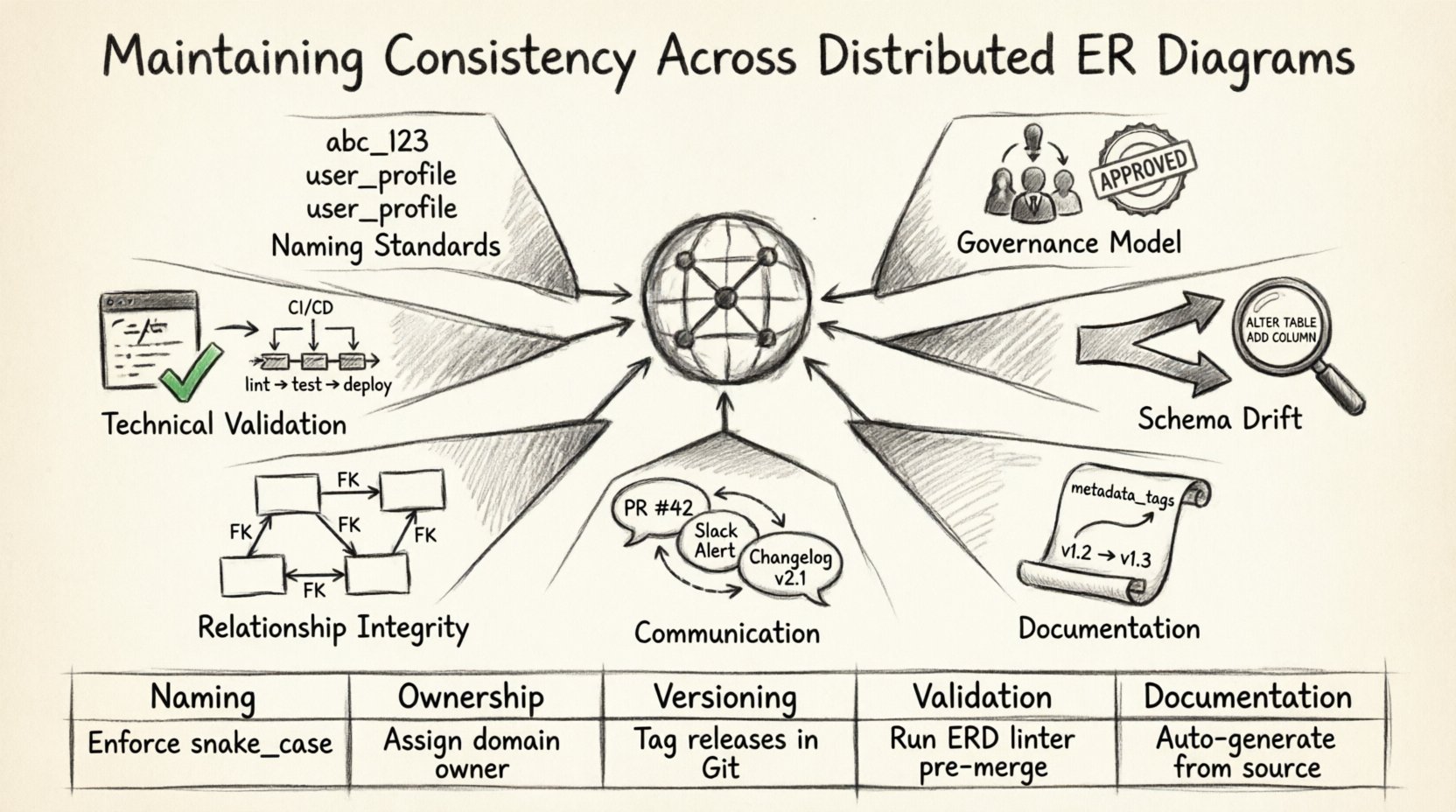
In modern enterprise architecture, data rarely lives in a single silo. Teams span continents, systems evolve independently, and database schemas must align without friction. This reality creates a specific challenge: maintaining consistency across distributed Entity-Relationship Diagrams (ERD). When multiple groups design data models for the same logical domain, divergence is inevitable without strict governance.
Inconsistent schemas lead to integration errors, ambiguous data definitions, and significant technical debt. This article explores the structural and procedural methods required to keep distributed data models synchronized. We will focus on standards, workflows, and validation techniques that ensure your data architecture remains robust regardless of where the modeling occurs.
🔍 Why Consistency Matters in Distributed Environments
Data consistency is not merely about visual alignment in a diagram. It is about semantic integrity. When two teams define a “Customer” entity differently, downstream applications suffer. One might treat it as a single table, while another splits it into “Profile” and “Billing.” This fragmentation complicates joins, reporting, and API development.
The benefits of a unified approach include:
- Data Integrity: Foreign key relationships remain valid across services.
- Query Performance: Optimized join paths rely on predictable schema structures.
- Onboarding Efficiency: New engineers understand the system faster when standards are clear.
- Refactoring Safety: Changes propagate logically rather than breaking dependent systems.
📏 Establishing Naming Standards
The first line of defense against inconsistency is a strict naming convention. Without this, a team in one region might name a table users, while another uses user_accounts. Over time, these variations create confusion and duplication.
Entity Naming Rules
- Pluralization: Decide early if tables should be plural (e.g.,
orders) or singular (e.g.,order). Stick to one style across all diagrams. - Underscores vs. CamelCase: SQL standards often favor snake_case for table names, while object-oriented layers may prefer camelCase. Ensure the ERD reflects the storage layer.
- Prefixed Domains: Use prefixes to denote business domains (e.g.,
fin_orders,hr_employees) to prevent collisions in shared schema spaces.
Attribute Naming Rules
- Timestamps: Use standard suffixes like
_created_atand_updated_atfor audit trails. - Foreign Keys: Name columns based on the referenced table (e.g.,
customer_id), not the relationship name. - Boolean Flags: Prefix boolean columns with
is_orhas_for clarity (e.g.,is_active).
🛡️ Governance Models for Distributed Teams
Who owns the schema? In a distributed setup, centralization is often impossible, but total decentralization leads to chaos. A hybrid governance model usually works best.
Centralized Standards Committee
A small group defines the rules. They do not write every diagram, but they approve the standards. This group maintains the documentation and handles disputes about naming or structure.
Federated Ownership
Teams own their domains but adhere to the shared contract. For example, the Finance team owns the payments schema, but they must use the user_id standard defined by the Core team.
Review Cycles
Regular reviews prevent drift. Schedule monthly sessions where schema changes are presented. This ensures that a new entity doesn’t violate existing relationship constraints.
🔄 Managing Schema Drift
Schema drift occurs when the physical database diverges from the documented ERD. This is common in distributed systems where deployments happen asynchronously.
Detection Mechanisms
- Automated Diffing: Compare the live database structure against the canonical ERD model.
- Migration Scripts: Treat schema changes as code. Every change must be versioned and traceable.
- Metadata Tags: Embed version information within the database metadata or table comments.
Remediation Strategies
When drift is detected, do not ignore it. Create a ticket to reconcile the difference. Ideally, the ERD should be updated to match the production state if the change was intentional, or the database should be reverted if the change was unauthorized.
| Drift Type | Risk Level | Recommended Action |
|---|---|---|
| Missing Index | Medium | Document in changelog; schedule optimization. |
| Changed Data Type | High | Immediate investigation; potential data loss risk. |
| Removed Column | Critical | Rollback deployment; restore data if possible. |
| Added Column | Low | Update ERD documentation to reflect change. |
📄 Documentation and Metadata
Diagrams are visual representations, but metadata provides the context. A well-maintained ERD includes more than just lines and boxes.
- Business Definitions: Define what a specific field means in business terms. Is
status“active” or “completed”? - Constraint Rules: Document unique constraints, check constraints, and default values directly in the diagram or accompanying wiki.
- Ownership: Clearly state which team is responsible for maintaining specific tables.
- Version History: Track when entities were created, modified, or deprecated.
Without this metadata, the diagram is just a picture. With it, the diagram becomes a contract.
🔗 Relationship Integrity
In distributed systems, relationships are often the most fragile part of the model. Foreign keys are the glue, but they can become bottlenecks or points of failure.
Referential Integrity
- Enforce at Database Level: Use foreign key constraints where possible to prevent orphaned records.
- Application Level Checks: In microservices, enforce logic in the application layer if database-level constraints are not feasible.
Cardinality Consistency
Ensure that the cardinality (one-to-one, one-to-many) defined in the ERD matches the actual data usage. A one-to-many relationship drawn in the diagram must not be implemented as a one-to-one in the code.
🚧 Common Pitfalls and How to Avoid Them
Even with standards, teams make mistakes. Recognizing these patterns helps prevent future errors.
1. The “Golden Table” Syndrome
Avoid a single table that contains data for every domain. This creates a bottleneck for writes and makes the schema monolithic. Instead, normalize data into related entities.
2. Implicit Relationships
Do not rely on column naming alone to define relationships. If a table has a user_id, it must be explicitly linked to the users table in the ERD.
3. Hardcoded Values
Do not embed business logic into the schema. A column named is_manager is better than a column named role_id if the role is fixed. However, flexible roles should use a separate lookup table.
🛠️ Technical Implementation and Validation
Standards must be enforced technically, not just verbally. Automation reduces human error.
- Linters: Use database schema linters that check against naming conventions.
- CI/CD Gates: Block deployments if the schema diff does not match the approved migration plan.
- Schema Registry: Maintain a central registry of all approved entities and their versions.
🤝 Communication Protocols
Technology is only half the battle. People must communicate changes effectively.
- Change Logs: Every schema update must have a linked change log entry.
- Impact Analysis: Before changing a table, document which services depend on it.
- Notification Channels: Use dedicated channels for schema alerts so teams know when to update their local models.
By combining strict standards with open communication, distributed teams can achieve a unified view of the data landscape. The goal is not to control every decision, but to ensure every decision aligns with the broader architectural vision.
📊 Summary of Best Practices
| Area | Key Action |
|---|---|
| Naming | Enforce snake_case and pluralization rules. |
| Ownership | Assign clear domain ownership to teams. |
| Versioning | Track all schema changes as code. |
| Validation | Automate drift detection and reporting. |
| Documentation | Keep metadata updated alongside the code. |
Consistency across distributed ER diagrams is an ongoing process. It requires discipline, regular audits, and a commitment to shared standards. When executed correctly, it transforms a fragmented data environment into a cohesive, reliable asset.

