











डेटाबेस आर्किटेक्चर अक्सर स्थिर नहीं होता है। जैसे-जैसे एप्लिकेशन बढ़ते हैं और आवश्यकताएं बदलती हैं, नीचे की डेटा संरचनाओं को अनुकूलित करना आवश्यक होता है। इस प्रक्रिया को स्कीमा एवोल्यूशन कहा जाता है। हालांकि, उत्पादन डेटाबेस में बदलाव लाने से बड़े जोखिम उत्पन्न होते हैं। एक गलत सीमा या गिराए गए कॉलम से एप्लिकेशन की कार्यक्षमता रुक सकती है या महत्वपूर्ण डेटा को नुकसान पहुंच सकता है। इन जोखिमों को कम करने के लिए इंजीनियर एंटिटी रिलेशनशिप मॉडल्स (ERMs) पर आधारित एक मजबूत पुष्टि रणनीति पर भरोसा करते हैं। 🛡️
डेप्लॉयमेंट से पहले स्कीमा एवोल्यूशन की पुष्टि करने से यह सुनिश्चित होता है कि तार्किक बदलाव भौतिक सीमाओं के अनुरूप हैं। यह डिज़ाइन के उद्देश्य और रनटाइम वास्तविकता के बीच के अंतर को पूरा करता है। ER मॉडल्स को सच्चाई के स्रोत के रूप में उपयोग करके टीमें बदलावों का सिमुलेशन कर सकती हैं, निर्भरता की जांच कर सकती हैं और लाइव डेटा को छूए बिना संगतता की पुष्टि कर सकती हैं। इस दृष्टिकोण से डाउनटाइम कम होता है और हाथ से बनाए गए माइग्रेशन स्क्रिप्ट्स से जुड़े अक्सर उत्पन्न होने वाले अव्यवस्था को रोका जा सकता है।
स्कीमा एवोल्यूशन क्यों महत्वपूर्ण है 📉
आधुनिक विकास चक्रों में, डेटा हर फीचर की रीढ़ है। जब व्यापार आवश्यकता बदलती है, तो डेटाबेस को आमतौर पर उस बदलाव को दर्शाने की आवश्यकता होती है। इसका मतलब हो सकता है एक नए फील्ड को जोड़ना, एक टेबल को बांटना या डेटा प्रकार को बदलना। एक संरचित पुष्टि प्रक्रिया के बिना, इन बदलावों को एक जुए के रूप में बना दिया जाता है।
एवोल्यूशन के दौरान आम चुनौतियां शामिल हैं:
- ब्रेकिंग बदलाव:एप्लिकेशन के निर्भरता वाले कॉलम को हटाने से तुरंत त्रुटियां होती हैं।
- प्रदर्शन में गिरावट:इंडेक्स जोड़ना या स्टोरेज इंजन बदलने से अप्रत्याशित रूप से प्रश्नों को धीमा कर दिया जा सकता है।
- डेटा अखंडता का नुकसान:खराब तरीके से परिभाषित सीमाएं अमान्य डेटा को सिस्टम में प्रवेश करने दे सकती हैं।
- डाउनटाइम:माइग्रेशन के दौरान टेबल को लॉक करने से उपयोगकर्ताओं के लिए एप्लिकेशन अनुपलब्ध हो सकता है।
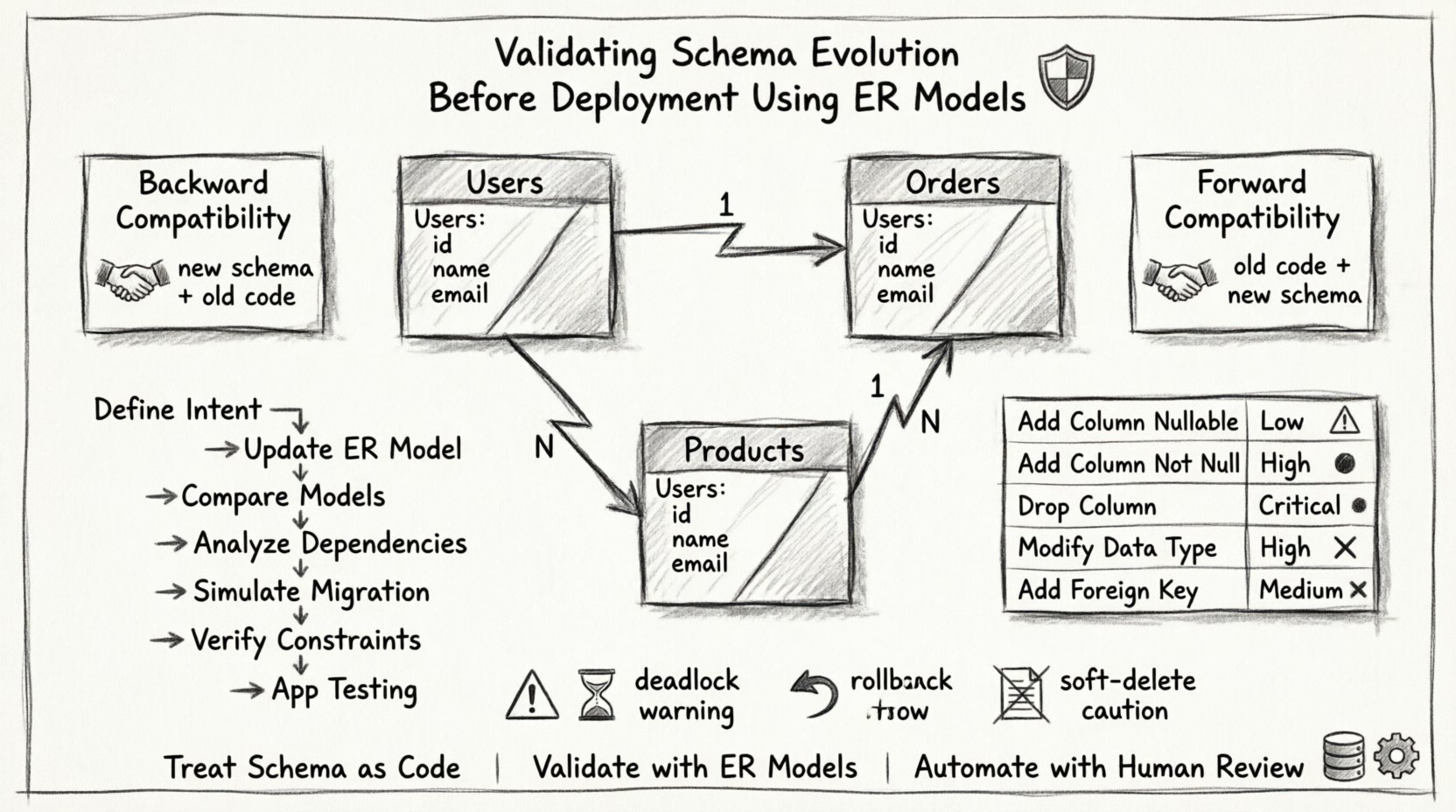
ER मॉडल का उपयोग करने से वास्तुकारों को इन जोखिमों को उनके होने से पहले देखने में मदद मिलती है। मॉडल एक ब्लूप्रिंट के रूप में काम करता है, जो संबंधों, कार्डिनैलिटी और सीमाओं को स्पष्ट रूप से दिखाता है। 📐
पुष्टि में ER मॉडल्स की भूमिका 🧩
एक एंटिटी रिलेशनशिप मॉडल डेटाबेस की तार्किक संरचना का प्रतिनिधित्व करता है। यह एंटिटीज (टेबल), एट्रिब्यूट्स (कॉलम) और संबंध (फॉरेन कीज) को परिभाषित करता है। एवोल्यूशन की पुष्टि करते समय, ER मॉडल तुलना के लिए आधार बिंदु के रूप में काम करता है।
यहां मॉडल की पुष्टि में मदद करने का तरीका है:
- निर्भरता मैपिंग:यह दिखाता है कि कौन सी टेबल दूसरों पर निर्भर हैं। यदि एक मुख्य टेबल में बदलाव होता है, तो बच्चे की टेबल की जांच करनी चाहिए।
- सीमा पुष्टि:प्राइमरी कीज और यूनिक सीमाएं तुरंत दिखाई देती हैं, जिससे यह सुनिश्चित होता है कि अपडेट के दौरान उनका उल्लंघन नहीं होता है।
- नॉर्मलाइजेशन जांच:यह यह सत्यापित करने में मदद करता है कि नई संरचनाएं अभी भी नॉर्मलाइजेशन नियमों का पालन करती हैं, जिससे अतिरिक्तता को रोका जा सकता है।
- ऐतिहासिक संदर्भ:वर्तमान ER डायग्राम की प्रस्तावित एक के साथ तुलना करने से यह स्पष्ट हो जाता है कि क्या बदलाव हुआ है।
ER डायग्राम को वर्जन-नियंत्रित सामग्री के रूप में लेने से टीमें समय के साथ एवोल्यूशन को ट्रैक कर सकती हैं। इससे विशिष्ट स्कीमा निर्णयों के कारणों के लिए एक ऑडिट ट्रेल बनता है।
बदलाव प्रकार की पहचान करना 🔍
सभी स्कीमा बदलाव समान नहीं होते हैं। कुछ सुरक्षित होते हैं, जबकि अन्य के लिए जटिल माइग्रेशन रणनीतियों की आवश्यकता होती है। बदलावों को वर्गीकृत करने से आवश्यक पुष्टि की गहराई का निर्धारण करने में मदद मिलती है।
| बदलाव प्रकार | जोखिम का स्तर | सत्यापन फोकस |
|---|---|---|
| कॉलम जोड़ें (नहीं खाली) | कम | डिफ़ॉल्ट मानों और स्टोरेज आकार की जांच करें। |
| कॉलम जोड़ें (खाली नहीं) | उच्च | यह सुनिश्चित करें कि मौजूदा डेटा प्रतिबंध को पूरा करता है या एक डिफ़ॉल्ट मान प्रदान करें। |
| कॉलम हटाएं | महत्वपूर्ण | यह सुनिश्चित करें कि कोई एप्लिकेशन कोड कॉलम को संदर्भित नहीं करता है। |
| डेटा प्रकार संशोधित करें | उच्च | डेटा के काटे जाने या अनिश्चितता की हानि की जांच करें। |
| विदेशी कुंजी जोड़ें | मध्यम | यह सुनिश्चित करें कि मौजूदा पंक्तियों के बीच संदर्भात्मक अखंडता बनी रहे। |
इन श्रेणियों को समझने से � ingineers को अपने परीक्षण प्रयासों को प्राथमिकता देने में मदद मिलती है। महत्वपूर्ण बदलावों के लिए हस्ताक्षरित समीक्षा की आवश्यकता होती है, जबकि कम जोखिम वाले बदलावों को स्वचालित किया जा सकता है।
संगतता रणनीतियाँ 🔄
जब स्कीमा बदलावों को डेप्लॉय करते हैं, तो एप्लिकेशन के साथ संगतता बनाए रखना महत्वपूर्ण है। दो मुख्य रणनीतियों पर विचार करना चाहिए: पीछे की ओर संगतता और आगे की ओर संगतता।
पीछे की ओर संगतता
यह सुनिश्चित करता है कि नया स्कीमा पुराने एप्लिकेशन कोड के साथ काम करता है। जब एप्लिकेशन अपडेट से पहले डेटाबेस बदलाव डेप्लॉय करते हैं, तो यह आवश्यक है। उदाहरण के लिए, यदि आप एक कॉलम जोड़ते हैं, तो पुराना कोड नए कॉलम को नजरअंदाज करने पर गिरना नहीं चाहिए। यदि आप किसी कॉलम को हटाते हैं, तो पुराना कोड अभी भी काम करना चाहिए या एक साथ अपडेट किया जाना चाहिए।
आगे की ओर संगतता
यह सुनिश्चित करता है कि पुराना एप्लिकेशन अभी भी नए स्कीमा को पढ़ सकता है। यह तब उपयोगी होता है जब डेटाबेस को एप्लिकेशन से पहले अपडेट किया जाता है। उदाहरण के लिए, कॉलम जोड़ने से पुराने प्रश्नों को त्रुटियों के बिना चलाया जा सकता है, भले ही वे नए डेटा का उपयोग न करें।
एक मजबूत सत्यापन प्रक्रिया दोनों दिशाओं की जांच करती है। ईआर मॉडल यह देखने में मदद करता है कि कोई बदलाव एप्लिकेशन और डेटाबेस के बीच संविदा को तोड़ता है या नहीं। 🤝
सत्यापन प्रक्रिया चरण दर चरण 🚀
स्कीमा बदलाव को लागू करने के लिए एक अनुशासित कार्य प्रवाह की आवश्यकता होती है। याददाश्त या त्वरित स्क्रिप्ट पर भरोसा करना खतरनाक है। विकास को सुरक्षित रूप से सत्यापित करने के लिए इस संरचित दृष्टिकोण का पालन करें।
- इरादा निर्धारित करें:स्पष्ट रूप से दर्ज करें कि क्या बदलना चाहिए और क्यों। इससे स्कोप क्रीप को रोका जा सकता है।
- ईआर मॉडल को अपडेट करें: आरेख की प्रस्तावित स्थिति बनाएं। भौतिक डेटाबेस पर अभी बदलाव लागू न करें।
- मॉडल की तुलना करें: वर्तमान और प्रस्तावित एर आरेखों के बीच अंतर बनाएं। जोड़े गए, हटाए गए या बदले गए तत्वों को पहचानें।
- निर्भरता का विश्लेषण करें: विदेशी कुंजियों और सूचकांकों का पता लगाएं। सुनिश्चित करें कि बदलाव के कारण कोई अनाथ संबंध न बने।
- माइग्रेशन का अनुकरण करें: उत्पादन डेटा के आकार की नकल करने वाले स्टेजिंग परिवेश में माइग्रेशन स्क्रिप्ट चलाएं।
- सीमाओं की पुष्टि करें: सुनिश्चित करें कि ट्रिगर, जांच और सीमाएं सही तरीके से लागू हों।
- एप्लिकेशन परीक्षण: नए स्कीमा के खिलाफ एप्लिकेशन चलाएं ताकि यह सुनिश्चित हो कि प्रश्नों के परिणाम अपेक्षित परिणाम दें।
ऑटोमेशन टूल स्टेप 3, 5 और 6 में सहायता कर सकते हैं, लेकिन जटिल तर्क के लिए मानव समीक्षा अभी भी आवश्यक है।
डेटा अखंडता और सीमाएं 🛑
स्कीमा विकास का सबसे महत्वपूर्ण पहलू डेटा अखंडता है। एक बदलाव जो कागज पर सही लगे, लाखों पंक्तियों पर लागू करने पर विफल हो सकता है। ईआर मॉडल सीमाओं को दृश्यमान बनाने में मदद करते हैं, लेकिन मान्यता के लिए उनका वास्तविक डेटा के साथ परीक्षण करना आवश्यक है।
सावधानी से जांच करने वाले मुख्य क्षेत्र इस प्रकार हैं:
- प्राथमिक कुंजियाँ: सुनिश्चित करें कि अद्वितीयता को नुकसान न पहुंचे।
- विदेशी कुंजियाँ: ऐसे चक्रीय निर्भरताओं की जांच करें जो डेडलॉक का कारण बन सकती हैं।
- जांच सीमाएं: सुनिश्चित करें कि व्यापार नियम (उदाहरण के लिए, उम्र धनात्मक होनी चाहिए) मौजूदा डेटा के लिए सही हों।
- सूचकांक: सुनिश्चित करें कि नए सूचकांक मौजूदा सूचकांकों से टकराते नहीं हैं या अत्यधिक लेखन लेटेंसी नहीं उत्पन्न करते हैं।
उदाहरण के लिए, किसी कॉलम को INT से VARCHAR यह सुरक्षित लग सकता है, लेकिन यदि एप्लिकेशन संख्यात्मक संचालन की अपेक्षा करती है, तो त्रुटियां होंगी। ईआर मॉडल में तार्किक प्रकार को दर्शाना चाहिए, लेकिन भौतिक कार्यान्वयन को मेल खाना चाहिए।
बचने वाले सामान्य त्रुटियां ⚠️
यहां तक कि अनुभवी टीमें भी गलतियां करती हैं। सामान्य त्रुटियों के बारे में जागरूक होना एक अधिक लचीले मान्यता प्रक्रिया के निर्माण में मदद करता है।
- डेडलॉक्स को नजरअंदाज करना:लंबे समय तक चलने वाले माइग्रेशन टेबल को लॉक कर सकते हैं, जिससे एप्लिकेशन के टाइमआउट हो सकते हैं। लॉक अवधि की पुष्टि करें।
- शून्य डाउनटाइम की धारणा:कुछ बदलाव आंतरिक रूप से डाउनटाइम की आवश्यकता रखते हैं। बेहतर नतीजे की आशा करने के बजाय इसके लिए स्पष्ट योजना बनाएं।
- रॉलबैक योजनाओं को छोड़ना:यदि प्रामाणिकता सफल हो जाती है लेकिन उत्पादन में विफलता होती है, तो रॉलबैक स्क्रिप्ट अनिवार्य है। माइग्रेशन के बराबर ही रॉलबैक का परीक्षण करें।
- सॉफ्ट डिलीट को नजरअंदाज करना:सॉफ्ट डिलीट किए गए रिकॉर्ड्स के लिए तर्क में बदलाव करने से डेटा के नुकसान का खतरा हो सकता है, यदि इसे सावधानी से नहीं संभाला गया।
वर्कफ्लो को स्वचालित करना ⚙️
जबकि मैन्युअल प्रामाणिकता व्यापक है, लेकिन यह स्केल नहीं होती है। स्वचालन उपकरण ईआर मॉडल्स को पार्स कर सकते हैं और माइग्रेशन स्क्रिप्ट्स बना सकते हैं। वे डेप्लॉयमेंट से पहले सामान्य त्रुटियों को पकड़ने के लिए लिंटिंग चेक भी चला सकते हैं।
स्वचालन के लाभ शामिल हैं:
- सुसंगतता:हर बदलाव एक ही नियमों का पालन करता है।
- गति:स्क्रिप्ट्स मैन्युअल समीक्षा की तुलना में तेजी से चलती हैं।
- दस्तावेज़ीकरण:उत्पन्न रिपोर्ट्स संगति ऑडिट के लिए प्रामाणिकता के प्रमाण के रूप में काम करती हैं।
- एकीकरण:स्वचालित जांच सीआई/सीडी पाइपलाइन का हिस्सा हो सकती है, जो प्रामाणिकता विफल होने पर डेप्लॉयमेंट को रोक सकती है।
हालांकि, स्वचालन मानव निर्णय को नहीं बदलना चाहिए। जटिल व्यावसायिक तर्क के लिए अक्सर एक सीनियर इंजीनियर की समीक्षा की आवश्यकता होती है जो डेटा के संदर्भ को समझता है।
स्कीमा प्रबंधन पर अंतिम विचार 🌱
स्कीमा विकास एक निरंतर प्रक्रिया है जिसके लिए जागरूकता की आवश्यकता होती है। डेटाबेस स्कीमा को कोड के रूप में लेना विश्वसनीयता की ओर पहला कदम है। ईआर मॉडल्स का उपयोग बदलावों के प्रामाणिकता के लिए करने से टीमें उच्च उपलब्धता और डेटा सटीकता बनाए रख सकती हैं।
लक्ष्य केवल बदलाव करना नहीं है, बल्कि उन्हें सुरक्षित तरीके से करना है। अच्छी तरह से प्रामाणित स्कीमा सुनिश्चित करता है कि आवश्यकताओं के विकास के साथ भी एप्लिकेशन स्थिर रहता है। इस अनुशासन ने विकास टीम और इंफ्रास्ट्रक्चर के बीच विश्वास बनाता है। 🏗️
डिज़ाइन चरण में समय निवेश करें। स्पष्ट आरेख बनाएं। हर प्रतिबंध का दस्तावेज़ीकरण करें। हर माइग्रेशन का परीक्षण करें। इन अभ्यासों के कारण एक स्वस्थ डेटा प्रणाली का आधार बनता है। जब डेटाबेस स्थिर होता है, तो एप्लिकेशन फलन-फूलन कर सकता है।
याद रखें कि स्कीमा प्रामाणिकता एक बार की घटना नहीं है। यह एक संस्कृति है। जैसे ही सिस्टम बढ़ता है, प्रामाणिकता प्रक्रिया को उसके साथ बढ़ना चाहिए। ईआर मॉडल की नियमित समीक्षा सुनिश्चित करती है कि आर्किटेक्चर व्यावसायिक लक्ष्यों के साथ संरेखित रहे। इस सक्रिय दृष्टिकोण से समय के साथ तकनीकी देनदारी जमा होने से रोका जा सकता है।