











एक टिकाऊ डेटाबेस संरचना डिज़ाइन करने के लिए सटीकता और दृष्टि की आवश्यकता होती है। एंटिटी-रिलेशनशिप डायग्राम (ईआरडी) इस संरचना के लिए आधारभूत नक्शा के रूप में कार्य करता है। स्पष्ट नक्शे के बिना, डेटा अतिरेक और प्रश्न बॉटलनेक जल्दी ही उभर आते हैं, जिससे समय के साथ प्रदर्शन में गिरावट आती है। इस मार्गदर्शिका में इन दृश्य मॉडलों से सीधे अनुकूलन तकनीकों को निकालने के तरीकों का अध्ययन किया गया है। हम विशिष्ट प्लेटफॉर्म विशेषताओं या स्वामित्व वाले उपकरणों पर निर्भरता के बिना संरचनात्मक अखंडता और प्रदर्शन समायोजन पर ध्यान केंद्रित करते हैं। नीचे लगी संबंधों को समझकर आप ऐसे प्रणालियाँ बना सकते हैं जो कुशलता से पैमाने पर बढ़ सकती हैं।
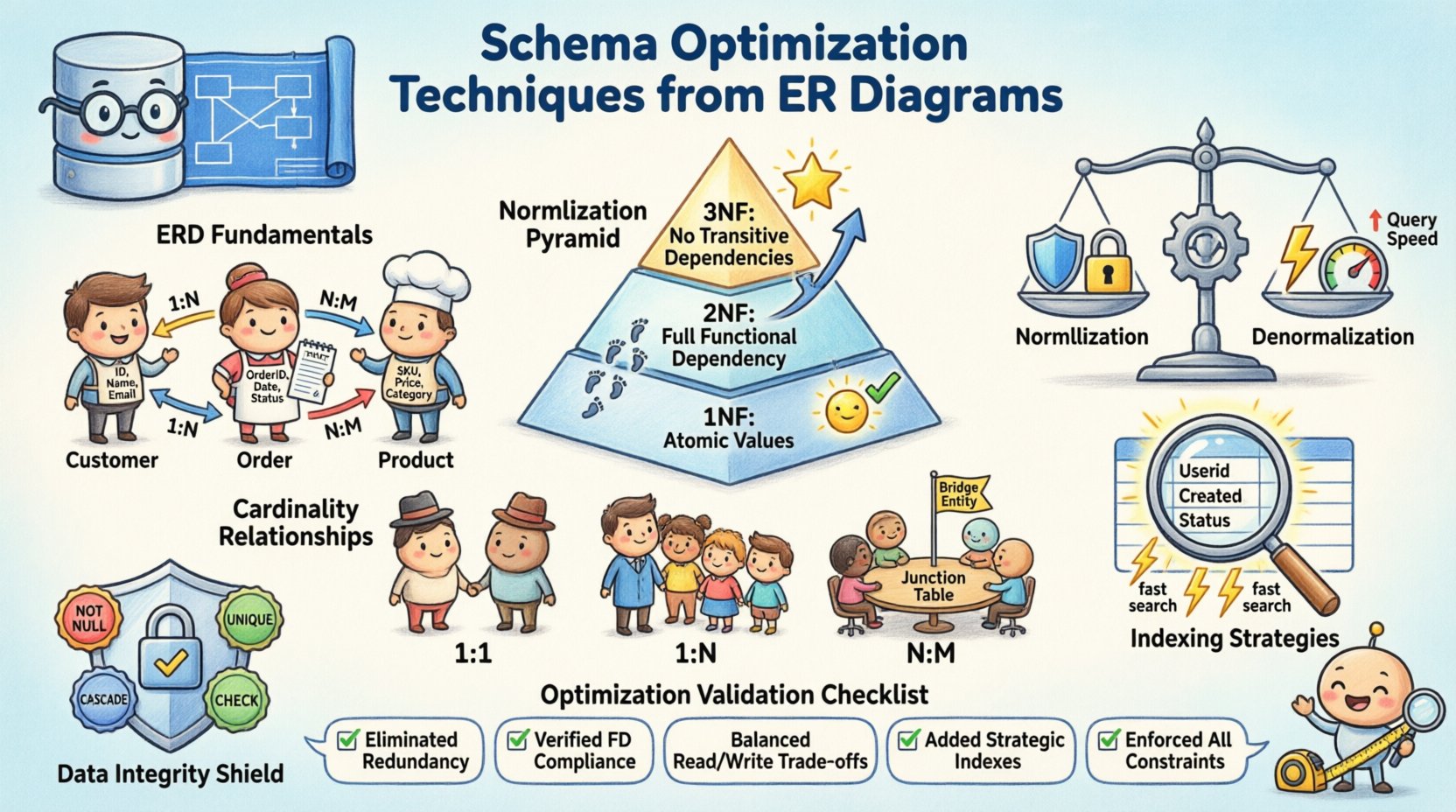
📐 ईआरडी मूल सिद्धांतों को समझना
अनुकूलन शुरू होने से पहले, मुख्य घटकों को स्पष्ट होना चाहिए। ईआर आरेख व्यापार आवश्यकताओं को एक तार्किक डेटा मॉडल में बदलता है। यह जानकारी के भंडारण और पहुंच के तरीके को परिभाषित करता है। एक मजबूत आधार विकास चक्र के बाद के चरणों में संरचनात्मक देनदारी को रोकता है। निम्नलिखित तत्वों पर विचार करें:
- एंटिटीज: वस्तुओं या अवधारणाओं का प्रतिनिधित्व करते हैं, जैसे ग्राहक, आदेश या उत्पाद। प्रत्येक एंटिटी भौतिक स्कीमा में एक तालिका बन जाती है।
- गुण: एंटिटीज के गुणों को परिभाषित करते हैं, जैसे नाम, आईडी या समयचिह्न। इन्हें तालिकाओं के भीतर कॉलम के रूप में बनाया जाता है।
- संबंध: ये एंटिटीज के बीच बातचीत को दिखाते हैं। इनके द्वारा विदेशी कुंजियों और सीमाओं के उपयोग का निर्धारण होता है।
इन घटकों को दृश्याकृत करने से आप एक भी कोड लाइन लिखे बिना संभावित समस्याओं की पहचान कर सकते हैं। यह सुनिश्चित करता है कि तार्किक प्रवाह भौतिक भंडारण की आवश्यकताओं के अनुरूप है। जटिल एप्लिकेशनों में डेटा सुसंगतता बनाए रखने के लिए इस संरेखण की आवश्यकता होती है।
🔨 डेटा अखंडता के लिए नॉर्मलाइजेशन रणनीतियाँ
नॉर्मलाइजेशन डेटा को व्यवस्थित करने की प्रक्रिया है जिससे अतिरेक को कम किया जाता है और अखंडता में सुधार होता है। इसमें बड़ी तालिकाओं को छोटे, तार्किक इकाइयों में विभाजित करना शामिल है। जबकि अत्यधिक नॉर्मलाइजेशन पढ़ने को धीमा कर सकता है, इसे पूरी तरह छोड़ने से अपडेट विचलन उत्पन्न होते हैं। लक्ष्य आपके विशिष्ट लोड के लिए संतुलन ढूंढना है।
पहला सामान्य रूप (1NF)
पहला नियम यह मांगता है कि प्रत्येक कॉलम में परमाणु मान हों। एक ही सेल में दोहराए जाने वाले समूह या ऐरे की अनुमति नहीं है। इससे यह सुनिश्चित होता है कि प्रत्येक डेटा का भाग अलग और प्रश्न करने योग्य हो। उदाहरण के लिए, फोन नंबरों की सूची को अलग-अलग पंक्तियों या संबंधित तालिका में विभाजित किया जाना चाहिए, एक कमा-अलग किए गए तार के रूप में संग्रहीत नहीं किया जाना चाहिए।
दूसरा सामान्य रूप (2NF)
जब 1NF पूरा हो जाता है, तो 2NF आंशिक निर्भरता को संबोधित करता है। सभी गैर-कुंजी विशेषताओं को पूर्ण मुख्य कुंजी पर निर्भर होना चाहिए। संयुक्त कुंजियों में, यह डेटा की दोहराव को रोकता है जहां केवल कुंजी का हिस्सा एक विशेषता को निर्धारित करता है। इस चरण से संरचना को बेहतर बनाया जाता है ताकि प्रत्येक जानकारी को उसके माता-पिता से सही तरीके से जोड़ा जा सके।
तीसरा सामान्य रूप (3NF)
तीसरा रूप अंतरित निर्भरता को दूर करता है। गैर-कुंजी विशेषताओं को अन्य गैर-कुंजी विशेषताओं पर निर्भर नहीं होना चाहिए। इसका मतलब है कि यदि विशेषता A विशेषता B पर निर्भर है, और B मुख्य कुंजी पर निर्भर है, तो A उसी तालिका में नहीं होना चाहिए। ऐसी जानकारी को अलग तालिका में ले जाने से रखरखाव में सुधार होता है और भंडारण का बर्बादी कम होती है।
नीचे दी गई तालिका नॉर्मलाइजेशन के विकास का सारांश प्रस्तुत करती है:
| सामान्य रूप | प्राथमिक लक्ष्य | मुख्य सीमा |
|---|---|---|
| 1NF | परमाणु मान | दोहराए जाने वाले समूह नहीं |
| 2NF | पूर्ण निर्भरता | आंशिक निर्भरता हटाएं |
| 3NF | स्वतंत्रता | स्थानांतरित निर्भरताओं को हटाएं |
⚡ प्रदर्शन के लिए अननॉर्मलाइजेशन
जबकि सामान्यीकरण अखंडता सुनिश्चित करता है, यह अक्सर प्रश्नों के दौरान जटिल जॉइन की आवश्यकता बनाता है। पठन-भारी प्रणालियों में, बहुत सारी तालिकाओं को जोड़ने के अतिरिक्त बोझ एक बाधा बन सकता है। अननॉर्मलाइजेशन जानबूझकर अतिरिक्तता लाता है ताकि प्राप्ति गति में सुधार हो। यह संग्रहण दक्षता और प्रश्न प्रदर्शन के बीच एक व्यापार बनता है।
निम्नलिखित परिस्थितियों को ध्यान में रखें जहां अननॉर्मलाइजेशन उपयुक्त है:
- रिपोर्टिंग डैशबोर्ड:संयुक्त डेटा को पूर्व-गणना और संग्रहीत किया जा सकता है ताकि वास्तविक समय की गणना से बचा जा सके।
- कैश परतें:अक्सर प्राप्त की जाने वाली डेटा को पठन-अनुकूलित भंडार में दोहराया जा सकता है।
- उच्च-प्रवाह लेनदेन:जॉइन गहिराई को कम करने से लॉक प्रतिस्पर्धा और सीपीयू उपयोग कम होता है।
इसके कार्यान्वयन के दौरान, अतिरिक्त डेटा के अपडेट के लिए स्पष्ट प्रक्रिया स्थापित करें। यदि सत्य का स्रोत बदलता है लेकिन प्रतिलिपियों को अपडेट नहीं किया जाता है, तो असंगतियां उत्पन्न होती हैं। सटीकता बनाए रखने के लिए स्वचालित ट्रिगर या एप्लिकेशन तर्क को समन्वयन को संभालना चाहिए।
🔗 कार्डिनैलिटी और संबंधों का प्रबंधन
कार्डिनैलिटी एकता के बीच संख्यात्मक संबंध को परिभाषित करती है। यह विदेशी कुंजियों के कार्यान्वयन और डेटा के जोड़े जाने के तरीके को निर्धारित करती है। अनाथ रिकॉर्डों को रोकने और संदर्भात्मक अखंडता सुनिश्चित करने के लिए इन पैटर्नों को समझना आवश्यक है।
- एक से एक: सामान्य प्रणालियों में दुर्लभ, अक्सर सुरक्षा या विस्तार तालिकाओं के लिए उपयोग किया जाता है। तालिका A में एकमात्र पंक्ति तालिका B में ठीक एक पंक्ति से जुड़ी होती है।
- एक से बहुत अधिक: सबसे आम संबंध। एक माता-पिता रिकॉर्ड बहुत सारे बच्चे रिकॉर्ड से संबंधित होता है। विदेशी कुंजी बच्चे की तालिका में स्थित होती है।
- बहुत से बहुत से: संबंध को हल करने के लिए एक संयोजन तालिका की आवश्यकता होती है। यह मध्यवर्ती तालिका दोनों एकताओं की प्राथमिक कुंजियों को जोड़ती है।
गलत कार्डिनैलिटी मान्यताएं अक्षम संग्रहण या अमान्य डेटा अवस्थाओं को ले जाती हैं। उदाहरण के लिए, बहुत से बहुत से संबंध को एक सरल कॉलम के रूप में लेना बहुगुणा संबंधों को रोक देगा। इन लिंक्स को सही तरीके से मॉडल करने से यह सुनिश्चित होता है कि डेटाबेस आरेख में परिभाषित व्यावसायिक नियमों को लागू कर सके।
📉 संरचनात्मक विश्लेषण के आधार पर इंडेक्सिंग रणनीतियां
इंडेक्स वह तंत्र है जो डेटाबेस इंजन को डेटा तेजी से खोजने की अनुमति देता है। ईआरडी की संरचना सीधे बताती है कि किन कॉलम को इंडेक्स किया जाना चाहिए। अंधाधुंध इंडेक्स जोड़ने से डिस्क स्थान का उपयोग होता है और लेखन ऑपरेशन धीमे हो जाते हैं।
मुख्य इंडेक्सिंग विचारों में शामिल हैं:
- प्राथमिक कुंजियां: डिफ़ॉल्ट रूप से हमेशा इंडेक्स किए जाते हैं। वे प्रत्येक पंक्ति की अद्वितीय पहचान को परिभाषित करते हैं।
- विदेशी कुंजियां: अक्सर जॉइन ऑपरेशन और सीमा जांच को तेज करने के लिए इंडेक्सिंग की आवश्यकता होती है।
- मिश्रित कुंजियां: जब प्रश्न बहुत सारे कॉलमों द्वारा फ़िल्टर करते हैं तो उपयोग किया जाता है। इंडेक्स में कॉलम के क्रम का प्रदर्शन के लिए महत्व होता है।
- चयनात्मक कॉलम: उच्च कार्डिनैलिटी वाले कॉलम पर इंडेक्स बनाएं। कम चयनता वाले (जैसे लिंग) कॉलम को इंडेक्स बनाने से बहुत कम लाभ मिलता है।
अपने प्रश्न पैटर्न का डेटाबेस डिजाइन के साथ विश्लेषण करें। यदि कोई विशिष्ट जॉइन बार-बार निष्पादित होता है, तो सुनिश्चित करें कि विदेशी कुंजी कॉलम पर इंडेक्स है। इससे डेटाबेस को पूरी टेबल को स्कैन करने में लगने वाला समय कम हो जाता है।
🛡️ डेटा अखंडता और संदर्भात्मक प्रतिबंध
अखंडता प्रतिबंध डेटा की सटीकता और सुसंगतता की रक्षा करते हैं। वे अमान्य इनपुट या अनजाने डेटा हटाने से बचाव के लिए एक सुरक्षा बाड़ के रूप में काम करते हैं। जबकि कुछ प्रतिबंध एप्लिकेशन द्वारा लागू किए जाते हैं, डेटाबेस स्तर के प्रतिबंध अधिक विश्वसनीय होते हैं।
आम प्रतिबंध प्रकारों में शामिल हैं:
- NOT NULL: सुनिश्चित करता है कि कॉलम में हमेशा कोई मान हो। महत्वपूर्ण डेटा क्षेत्रों में खाली जगह रोकता है।
- UNIQUE: सुनिश्चित करता है कि किसी विशिष्ट कॉलम में कोई दो पंक्तियाँ समान मान साझा नहीं करती हैं। ईमेल या उपयोगकर्ता नाम के लिए उपयोगी।
- CASCADE: जब किसी माता को हटाया जाता है तो बच्चे के रिकॉर्ड के साथ क्या होता है, इसे परिभाषित करता है। विकल्पों में रोकथाम, कैसकेड या नल सेट शामिल हैं।
- CHECK: डेटा मानों पर विशिष्ट शर्तों को लागू करता है, जैसे तारीख की सीमा या संख्यात्मक सीमा।
डेटाबेस स्तर पर इन नियमों को लागू करने से एप्लिकेशन को हर डेटा बिंदु के लिए वैधता की जांच करने की आवश्यकता नहीं होती है। यह डेटा वैधता के लिए तर्क को केंद्रीकृत करता है, कोड की बहुलकता और संभावित त्रुटियों को कम करता है।
🔄 आवर्ती सुधार और स्कीमा विकास
स्कीमा डिजाइन एक बार का कार्य नहीं है। व्यवसाय की आवश्यकताएं बदलती हैं, और डेटा मॉडल को विकसित होना चाहिए। ईआरडी और भौतिक स्कीमा की नियमित समीक्षा सुधार के क्षेत्रों को पहचानने में मदद करती है। प्रश्न प्रदर्शन की निगरानी संरचना के कहाँ कठिनाई हो रही है, इसके बारे में जानकारी देती है।
सुधार के दौरान निम्नलिखित चरणों पर विचार करें:
- इंडेक्स उपयोग की समीक्षा करें: लेखन ओवरहेड को कम करने के लिए अनावश्यक इंडेक्स हटाएं।
- पार्टीशनिंग की जांच करें: बड़ी टेबल को रेंज या कुंजी के आधार पर डेटा के विभाजन से लाभ मिल सकता है।
- कार्डिनैलिटी को अद्यतन करें: व्यवसाय तर्क बदलने पर संबंध एक-से-बहुत से बहुत-से-बहुत में बदल सकते हैं।
- संस्करण नियंत्रण: स्कीमा परिवर्तनों को कोड के रूप में लें। परिवर्तनों को ट्रैक करें ताकि आवश्यकता पड़ने पर वापस ले लिया जा सके।
इस आवर्ती दृष्टिकोण से यह सुनिश्चित होता है कि डेटाबेस लंबे समय तक एप्लिकेशन की आवश्यकताओं के अनुरूप रहता है। यह भविष्य के विकास को धीमा करने वाले तकनीकी ऋण के एकत्रीकरण को रोकता है।
✅ अनुकूलन चेकलिस्ट
डेप्लॉयमेंट से पहले अपने स्कीमा डिजाइन की पुष्टि करने के लिए इस सूची का उपयोग करें:
- सुनिश्चित करें कि सभी टेबल कम से कम तृतीय सामान्य रूप (3NF) को पूरा करते हैं।
- सुनिश्चित करें कि जॉइन के लिए आवश्यक बार विदेशी कुंजियों को सूचीबद्ध किया गया हो।
- संबंधों में चक्रीय निर्भरता के लिए जांच करें।
- सुनिश्चित करें कि प्रत्येक तालिका के लिए मुख्य कुंजी परिभाषित है।
- डेटा सुसंगतता नियमों को लागू करने की गारंटी देने के लिए प्रतिबंधों की समीक्षा करें।
- संभावित अनियमितता के अवसरों की पहचान करने के लिए प्रश्न पैटर्न का विश्लेषण करें।
- डेटा कार्डिनैलिटी और आयतन के संबंध में सभी मान्यताओं को दस्तावेज़ीकृत करें।
इन चरणों का पालन करने से डेटा संग्रहण के लिए एक लचीला आधार बनता है। यह प्रणाली को बिना पूरी तरह से पुनर्निर्माण किए वृद्धि को संभालने की अनुमति देता है। अच्छी तरह से अनुकूलित स्कीमा एक धीमी एप्लिकेशन और एक प्रतिक्रियाशील एप्लिकेशन के बीच अंतर है।