











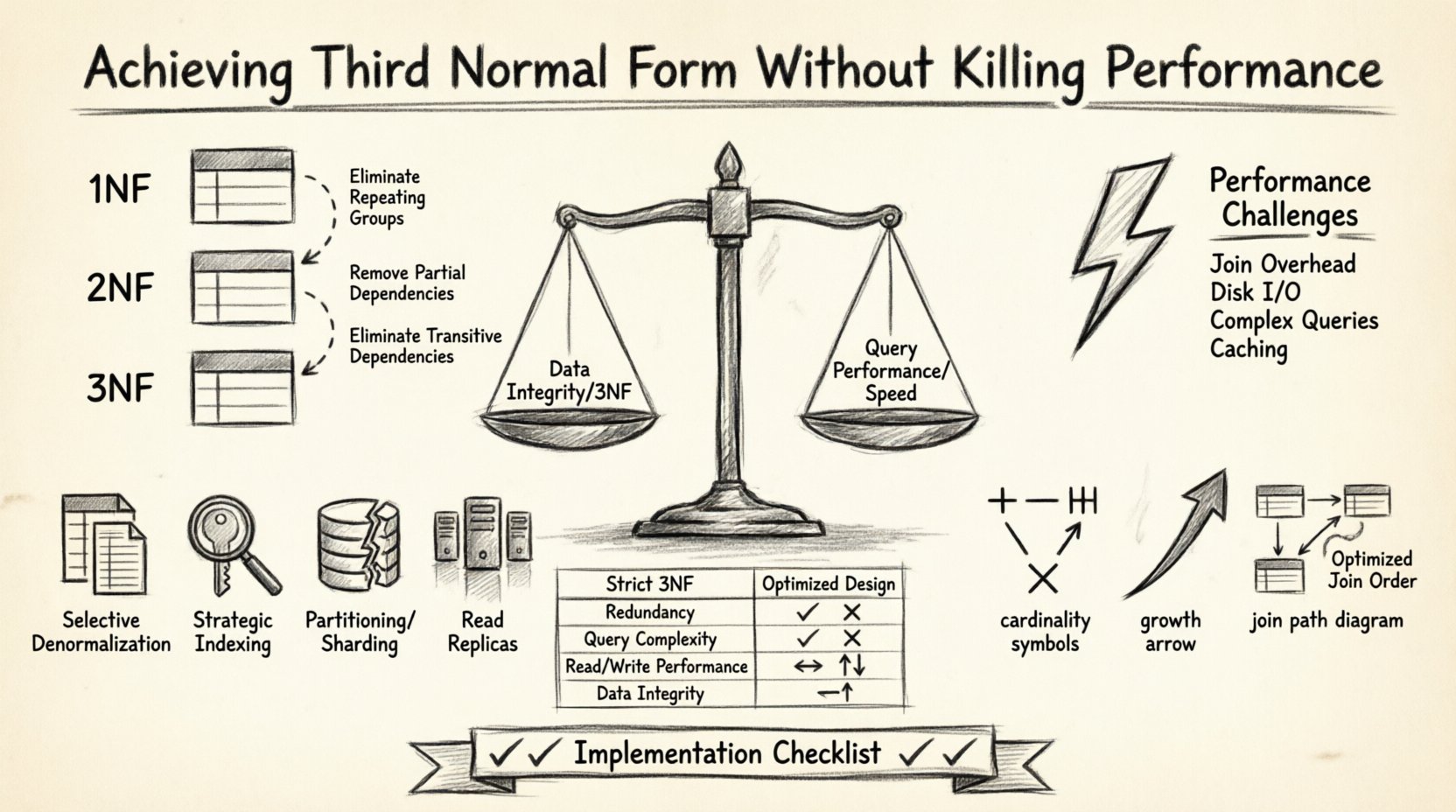
एक टिकाऊ डेटाबेस संरचना डिज़ाइन करना एक संतुलन का खेल है। एक तरफ आपके पास डेटा अखंडता और नॉर्मलाइजेशन के माध्यम से अतिरिक्तता को दूर करना है। दूसरी तरफ आपके पास प्रश्न गति और प्रणाली की प्रतिक्रिया समय है। बहुत से डेटाबेस वार्ड एक कठिन चुनाव के सामने हैं: सख्त नॉर्मलाइजेशन नियमों का पालन करें और धीमे प्रश्नों के जोखिम में रहें, या अत्यधिक अनॉर्मलाइज़ करें और डेटा असंगतियों के जोखिम में रहें। लक्ष्य तीसरे सामान्य रूप (3NF) का पालन करते हुए उच्च प्रदर्शन बनाए रखने वाले मध्यम बिंदु को खोजना है। यह लेख इस संतुलन को प्राप्त करने के लिए एंटिटी रिलेशनशिप डायग्राम (ERD) को कैसे संरचित करना है, इसका अध्ययन करता है, बिना अखंडता या गति के नुकसान के।
तृतीय सामान्य रूप को समझना 🧩
तृतीय सामान्य रूप डेटाबेस नॉर्मलाइजेशन का एक विशिष्ट स्तर है। 3NF तक पहुंचने से पहले, एक तालिका को पहले प्रथम सामान्य रूप (1NF) और द्वितीय सामान्य रूप (2NF) को संतुष्ट करना होगा। 3NF का मूल सिद्धांत यह है कि सभी गुणधर्म केवल मुख्य कुंजी पर निर्भर हों। ट्रांजिटिव निर्भरता नहीं होनी चाहिए।
- प्रथम सामान्य रूप: दोहराए जाने वाले समूहों को दूर करता है और परमाणु मानों की गारंटी देता है।
- द्वितीय सामान्य रूप: आंशिक निर्भरताओं को हटाता है, जहां गुणधर्म जो कुंजी नहीं हैं, केवल मिश्रित कुंजी के केवल एक हिस्से पर निर्भर होते हैं।
- तृतीय सामान्य रूप: ट्रांजिटिव निर्भरताओं को हटाता है। यदि A, B को निर्धारित करता है, और B, C को निर्धारित करता है, तो C को उसी तालिका में A पर सीधे निर्भर नहीं होना चाहिए।
जब आप 3NF तक पहुंचते हैं, तो आप अपडेट विचलनों को न्यूनतम करते हैं। ये त्रुटियां होती हैं जब डेटा एक स्थान पर बदला जाता है लेकिन दूसरे स्थानों पर नहीं, जिससे असंगतता उत्पन्न होती है। उदाहरण के लिए, यदि एक ग्राहक का पता दोनों तालिकाओं में संग्रहीत है आदेश तालिका और ग्राहक तालिका में, एक तालिका में पता बदलने पर लेकिन दूसरी में नहीं, अंतर उत्पन्न होता है। 3NF आपको उस पते को केवल एक ही स्थान पर संग्रहीत करने के लिए मजबूर करता है।
प्रदर्शन के बदलाव ⚡
जबकि 3NF डेटा अखंडता के लिए उत्तम है, यह अक्सर प्रदर्शन के लिए लागत के साथ आता है। नॉर्मलाइज्ड डेटाबेस में आमतौर पर अधिक तालिकाओं की आवश्यकता होती है। एक पूर्ण डेटासेट प्राप्त करने के लिए, डेटाबेस इंजन को बहुत सारे जॉइन करने की आवश्यकता होती है। प्रत्येक जॉइन संचालन के लिए प्रणाली को डिस्क या मेमोरी से डेटा पढ़ना, कुंजियों को मिलाना और परिणामों को जोड़ना आवश्यक होता है।
एक रिपोर्टिंग प्रश्न के बारे में सोचें जिसमें ग्राहक के नाम, आदेश विवरण, उत्पाद विवरण और शिपिंग पते की आवश्यकता होती है। एक पूरी तरह से नॉर्मलाइज्ड 3NF डिज़ाइन में, इसमें पांच या अधिक तालिकाओं को जोड़ने की आवश्यकता हो सकती है। यदि डेटा का आयतन बड़ा है, तो इन जॉइन को एक बैरियर बन सकते हैं।
यहां 3NF से जुड़ी विशिष्ट प्रदर्शन चुनौतियां हैं:
- जॉइन ओवरहेड में वृद्धि: प्रत्येक संबंध को पढ़ने के प्रश्नों के दौरान एक जॉइन संचालन की आवश्यकता होती है।
- डिस्क I/O: बहुत सारी तालिकाओं में डेटा फैलाने से डेटाबेस इंजन द्वारा पहुंचे जाने वाले पृष्ठों की संख्या बढ़ जाती है।
- जटिल प्रश्न तर्क: एप्लिकेशन को संबंधित डेटा प्राप्त करने के लिए अधिक जटिल SQL बयान बनाने की आवश्यकता होती है।
- कैशिंग की जटिलता: एक अनॉर्मलाइज्ड पंक्ति को कैश करना बहुत संबंधित पंक्तियों को कैश करने से आसान होता है।
अखंडता और गति के बीच संतुलन बनाने के रणनीतियां 🚀
प्रदर्शन में सुधार के लिए आपको नॉर्मलाइजेशन छोड़ने की आवश्यकता नहीं है। 3NF डेटाबेस को बनाए रखते हुए अनुकूलित करने के विशिष्ट तरीके हैं। निम्नलिखित रणनीतियां गति के नुकसान के बिना डेटा गुणवत्ता को बनाए रखने में मदद करती हैं।
1. चयनात्मक अनॉर्मलाइजेशन
हर टेबल को सख्ती से 3NF में नहीं होना चाहिए। पढ़ने वाली टेबल्स और महत्वपूर्ण डेटा पथ की पहचान करें। इन विशिष्ट क्षेत्रों में नियंत्रित अतिरिक्तता लागू कर सकते हैं। उदाहरण के लिए, एक ग्राहक के नाम को सीधे टेबल में स्टोर करें।आदेश टेबल। जबकि यह डेटा की दोहराव करता है, आदेश खोजों के लिए प्रदर्शन में महत्वपूर्ण लाभ होता है। फिर आपको ग्राहक रिकॉर्ड में बदलाव होने पर इस कॉपी को अपडेट रखने के लिए ट्रिगर या एप्लीकेशन लॉजिक को लागू करना होगा।
2. रणनीतिक सूचीकरण
सूचियाँ जॉइन को तेज करने के मुख्य उपकरण हैं। सूचियों के बिना, एक डेटाबेस हर जॉइन शर्त के लिए पूरी टेबल स्कैन करता है। सही सूचीकरण के साथ, खोज लगभग तुरंत हो जाती है।
- विदेशी की सूचियाँ: विदेशी की संबंधों में उपयोग किए जाने वाले कॉलम को हमेशा सूचीबद्ध करें। इससे यह सुनिश्चित होता है कि टेबल्स को जोड़ना तेज हो।
- मिश्रित सूचियाँ: अगर आपके प्रश्न अक्सर उस संयोजन द्वारा फ़िल्टर करते हैं, तो एक से अधिक कॉलम पर सूचियाँ बनाएँ।
- कवरिंग सूचियाँ: एक विशिष्ट प्रश्न के लिए आवश्यक सभी कॉलम वाली सूचियाँ डिज़ाइन करें। इससे डेटाबेस को केवल सूची का उपयोग करके प्रश्न को संतुष्ट करने की अनुमति मिलती है, मुख्य टेबल डेटा तक लुकअप से बचा जा सकता है।
3. पार्टीशनिंग और शार्डिंग
अगर डेटासेट बहुत बड़ा हो जाता है, तो टेबल्स को बाँटने से प्रदर्शन में सुधार हो सकता है। पार्टीशनिंग एक बड़ी टेबल को छोटे, अधिक प्रबंधनीय भौतिक टुकड़ों में एक कुंजी, जैसे तारीख या क्षेत्र के आधार पर विभाजित करती है। शार्डिंग डेटा को कई डेटाबेस इंस्टेंसेज के बीच वितरित करती है। दोनों विधियाँ एक विशिष्ट प्रश्न का उत्तर देने के लिए इंजन को स्कैन करने की आवश्यकता वाली डेटा मात्रा को कम करती हैं।
4. पढ़ने वाले प्रतिरूप
अपने लेखन संचालन को पढ़ने वाले संचालन से अलग करें। लेनदेन और अपडेट के लिए प्राथमिक डेटाबेस इंस्टेंस का उपयोग करें। उस डेटा को एक या अधिक पठन-केवल प्रतिरूप में प्रतिलिपि बनाएँ। जटिल रिपोर्टिंग प्रश्न जो सिस्टम पर दबाव डालते हैं, प्रतिरूप पर चल सकते हैं, जिससे मुख्य सिस्टम उपयोगकर्ता बातचीत के लिए तेज रहता है।
ERD डिज़ाइन के विचार 📐
एक एंटिटी रिलेशनशिप डायग्राम बनाते समय, दृश्य प्रतिनिधित्व विकासकर्ताओं द्वारा प्रश्न लिखने के तरीके को प्रभावित करता है। एक स्पष्ट ERD संबंधों की जल्दी पहचान में मदद करता है। हालांकि, एक ऐसा डायग्राम जो कागज पर आदर्श लगता है, उत्पादन में खराब प्रदर्शन कर सकता है। यहाँ प्रदर्शन के लिए ERD डिज़ाइन के तरीके के बारे में है।
- कार्डिनैलिटी को स्पष्ट रूप से पहचानें: सुनिश्चित करें कि प्रत्येक संबंध में परिभाषित कार्डिनैलिटी (एक-एक, एक-बहुत, बहुत-बहुत) हो। अस्पष्ट संबंध अक्षम जॉइन की ओर जाते हैं।
- वृद्धि के लिए योजना बनाएँ: भविष्य के डेटा आयतन की भविष्यवाणी करें। 10,000 पंक्तियों के लिए काम करने वाला डिज़ाइन 10 मिलियन पंक्तियों के साथ विफल हो सकता है।
- जॉइन पथ की समीक्षा करें: एक सामान्य प्रश्न डायग्राम के माध्यम से कौन-से पथ लेगा, उसका अनुसरण करें। यदि पथ बहुत लंबा है, तो एक अनियमित कॉलम जोड़ने के बारे में सोचें।
- प्रतिबंधों को दस्तावेज़ीकरण करें: स्पष्ट रूप से दस्तावेज़ीकरण करें कि कौन-से प्रतिबंध डेटाबेस द्वारा लागू किए जाते हैं और कौन-से एप्लीकेशन लेयर द्वारा संभाले जाते हैं।
तुलना: सामान्यीकृत बनाम अनुकूलित डिज़ाइन 📊
नीचे दी गई तालिका एक विशिष्ट परिदृश्य के लिए सख्त 3NF दृष्टिकोण और अनुकूलित दृष्टिकोण के बीच अंतर को दर्शाती है।
| विशेषता | सख्त 3NF डिज़ाइन | अनुकूलित डिज़ाइन |
|---|---|---|
| आवर्धन | न्यूनतम | नियंत्रित और सीमित |
| प्रश्न कठिनाई | उच्च (बहुत सारे जॉइन) | मध्यम (कम जॉइन) |
| लेखन प्रदर्शन | तेज (कम डेटा) | चर (अपडेट ट्रिगर्स) |
| पढ़ने का प्रदर्शन | धीमा (डिस्क आई/ओ) | तेज (कैश किया गया डेटा) |
| डेटा अखंडता | उच्च | उच्च (सत्यापन के साथ) |
नियमों को तोड़ने का समय 🛑
ऐसे वैध परिदृश्य हैं जहां सख्त 3NF को छोड़ देना चाहिए। डेटाबेस वार्डों के लिए यह समझना महत्वपूर्ण है कि कब विचलन करना चाहिए।
- रिपोर्टिंग और विश्लेषण:डेटा विशालाय अक्सर 3NF के बजाय स्टार स्कीमा का उपयोग करते हैं। यहां लक्ष्य विश्लेषण के लिए पढ़ने की गति है, लेनदेन अखंडता नहीं।
- उच्च-प्रवाह लेनदेन प्रणालियां: यदि प्रणाली प्रति सेकंड मिलियन लेखनों को संभालती है, तो जटिल जॉइन लॉक प्रतिस्पर्धा का कारण बन सकते हैं। स्कीमा को सरल बनाने से लॉकिंग ओवरहेड कम हो सकता है।
- पुरानी प्रणालियां: यदि पुरानी प्रणाली से स्थानांतरण कर रहे हैं, तो एप्लिकेशन लेयर के पुनर्निर्माण के दौरान अस्थायी रूप से अनियमित बनाना तेज हो सकता है।
- पढ़ने पर निर्भर एप्लिकेशन: यदि आपके एप्लिकेशन को प्रत्येक लेखन के लिए डेटा को 100 बार पढ़ना है, तो 3NF संगतता बनाए रखने की लागत लाभ से अधिक हो जाती है।
कार्यान्वयन चेकलिस्ट ✅
अपने डेटाबेस स्कीमा को डेप्लॉय करने से पहले, इस चेकलिस्ट को चेक करें ताकि आपको संतुलित प्रदर्शन और नॉर्मलाइजेशन मिले।
- प्रश्न पैटर्न का विश्लेषण करें: सबसे अधिक बार पढ़े जाने वाले प्रश्नों को पहचानें। क्या उन्हें बहुत अधिक जॉइन की आवश्यकता है?
- वर्तमान प्रदर्शन को मापें: अपने सिस्टम का आधार निर्धारित करें। महत्वपूर्ण प्रश्नों की वर्तमान लेटेंसी को जानें।
- इंडेक्स उपयोग की समीक्षा करें: जांचें कि क्या इंडेक्स का उपयोग किया जा रहा है या लेखन के दौरान ओवरहेड का कारण बन रहे हैं।
- लेखन लोड का परीक्षण करें: सुनिश्चित करें कि कोई भी डेनॉर्मलाइजेशन रणनीति लेखन संचालन को बहुत धीमा न करे।
- डेटा सिंक के लिए योजना बनाएं: यदि आप डेटा की प्रतिलिपि बनाते हैं, तो आप इसे सिंक कैसे रखेंगे? तंत्र को परिभाषित करें।
- विचित्रताओं का निरीक्षण करें: यदि आप आंशिक डेनॉर्मलाइजेशन का उपयोग कर रहे हैं, तो डेटा असंगतियों के लिए चेतावनी सेट करें।
डेटाबेस आर्किटेक्चर पर अंतिम विचार 🏗️
प्रदर्शन को नष्ट किए बिना तृतीय सामान्य रूप प्राप्त करने के लिए सूक्ष्म दृष्टिकोण की आवश्यकता होती है। गति और अखंडता के बीच द्विआधारी चयन नहीं है। जॉइन्स की लागत को समझने, इंडेक्स का प्रभावी रूप से उपयोग करने और उचित स्थानों पर चयनात्मक डेनॉर्मलाइजेशन लागू करने के द्वारा, आप विश्वसनीय और तेज़ दोनों वाले प्रणालियां बना सकते हैं। सर्वोत्तम डेटाबेस डिज़ाइन वह है जो एप्लिकेशन के विशिष्ट लोड से मेल खाता है। जैसे-जैसे प्रणाली बढ़ती है, अपने ईआरडी और प्रश्न प्रदर्शन की नियमित समीक्षा करें। डेटा प्रबंधन में दीर्घकालिक सफलता के लिए अनुकूलन महत्वपूर्ण है।