











Merancang skema basis data jarang merupakan pilihan biner antara kecepatan dan struktur. Ini adalah latihan dalam kompromi. Ketika arsitek membuat Diagram Entitas-Kelompok (ERD), mereka sering menghadapi ketegangan antara integritas data yang ketat dan kecepatan mentah yang dibutuhkan untuk aplikasi bervolume tinggi. Normalisasi meminimalkan redundansi, memastikan bahwa data tetap konsisten. Namun, biaya untuk mempertahankan konsistensi tersebut sering dibayar dengan kinerja baca.
Artikel ini mengeksplorasi nuansa teknis dari keseimbangan ini. Kami akan memeriksa bagaimana normalisasi memengaruhi operasi join, bagaimana beban kerja yang berat pada baca menentukan perubahan skema, dan di mana batas ditarik antara basis data yang terstruktur dengan baik dan yang berkinerja tinggi.
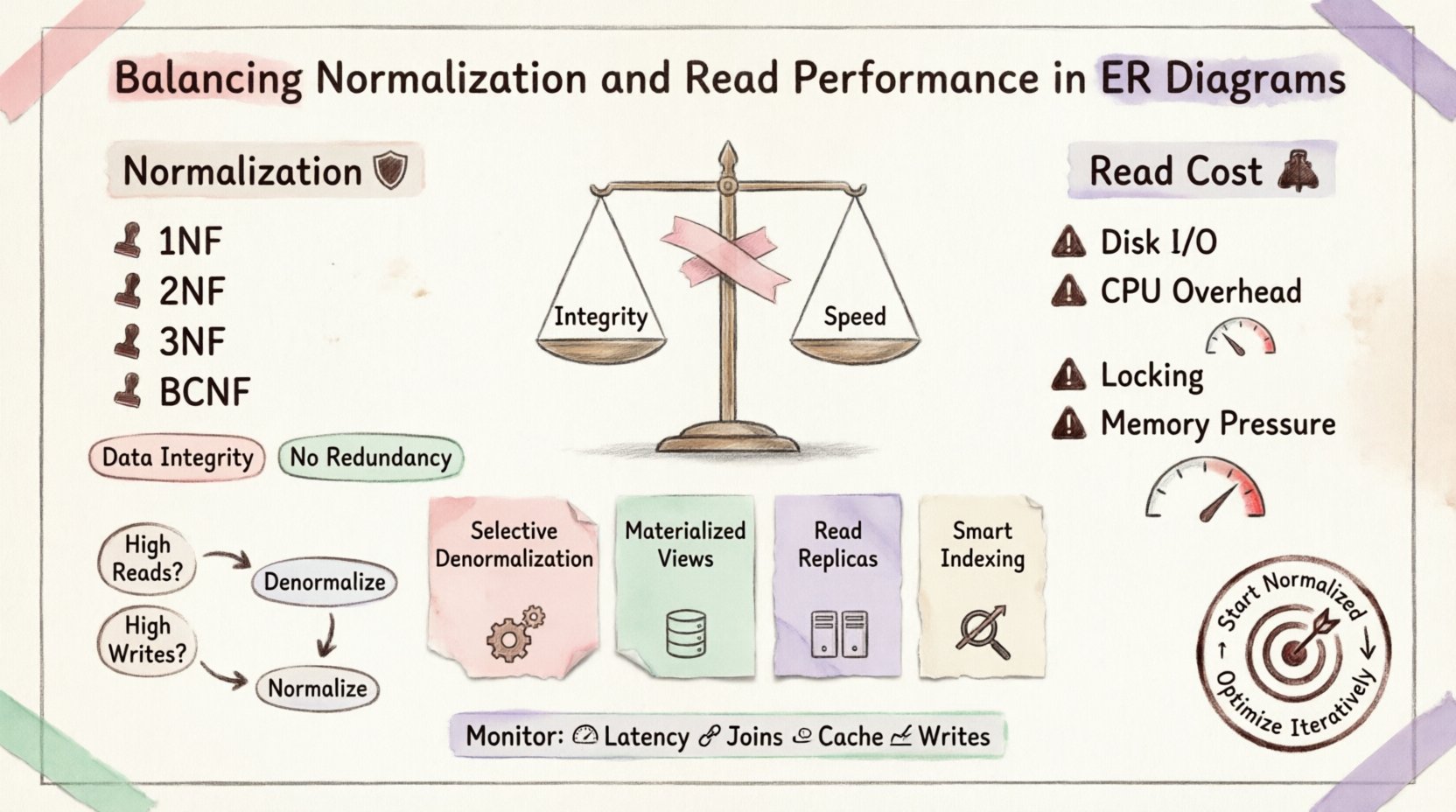
Memahami Normalisasi: Pondasi 🛡️
Normalisasi adalah proses mengorganisasi data untuk mengurangi redundansi dan meningkatkan integritas data. Ini melibatkan pembagian tabel besar menjadi tabel-tabel kecil yang logis dan menentukan hubungan di antaranya. Tujuannya adalah menghilangkan anomali selama penyisipan, pembaruan, dan penghapusan.
Bentuk Normal Utama
-
Bentuk Normal Pertama (1NF):Memastikan atomisitas. Setiap kolom berisi hanya satu nilai. Tidak ada kelompok berulang.
-
Bentuk Normal Kedua (2NF):Membangun dari 1NF. Semua atribut non-kunci harus sepenuhnya tergantung pada kunci utama. Menghilangkan ketergantungan parsial.
-
Bentuk Normal Ketiga (3NF):Membangun dari 2NF. Menghilangkan ketergantungan transitif. Atribut non-kunci hanya tergantung pada kunci, seluruh kunci, dan tidak ada yang selain kunci.
-
Bentuk Normal Boyce-Codd (BCNF):Versi yang lebih ketat dari 3NF untuk menangani anomali ketergantungan tertentu.
Meskipun mematuhi bentuk-bentuk ini menjamin basis data yang bersih, hal ini menimbulkan kompleksitas dalam pengambilan data. Setiap hubungan yang didefinisikan dalam diagram ER menjadi operasi join yang mungkin.
Biaya Bacaan 💸
Ketika Anda normalisasi data, Anda sering membagi informasi di seluruh beberapa tabel. Untuk mengambil catatan lengkap, mesin basis data harus melakukan operasi join. Operasi join sangat mahal secara komputasi.
Mengapa Join Memperlambat Kueri
-
I/O Disk: Jika tabel tidak diindeks atau disimpan dalam cache secara sempurna, mesin harus mencari data di lokasi fisik yang berbeda pada disk.
-
Overhead CPU: Basis data harus mencocokkan kunci dari satu tabel ke tabel lainnya. Ini membutuhkan kekuatan pemrosesan yang signifikan.
-
Persaingan Penahanan Kunci: Join yang kompleks dapat memegang kunci lebih lama, menghalangi transaksi lain untuk mengakses data yang terkait.
-
Tekanan Memori: Operasi join yang besar membutuhkan buffer memori yang besar untuk mengurutkan dan meng-hash data.
Dalam lingkungan yang berat pada bacaan, seperti dashboard pelaporan atau API yang terbuka untuk publik, latensi ini tidak dapat diterima. Pengguna mengharapkan umpan balik instan. Kueri yang membutuhkan 100 milidetik untuk mengembalikan data yang dinormalisasi mungkin hanya membutuhkan 10 milidetik jika tidak dinormalisasi.
Strategi untuk Optimalisasi 🚀
Untuk menyeimbangkan integritas dan kecepatan, arsitek menggunakan pola-pola tertentu. Strategi-strategi ini memungkinkan Anda mempertahankan basis data yang dinormalisasi di tempat yang paling penting, sambil mengoptimalkan untuk bacaan di tempat yang benar-benar penting.
1. Denormalisasi Selektif
Tidak semua tabel perlu dinormalisasi sepenuhnya. Identifikasi data yang paling sering diakses dan simpan secara berulang. Sebagai contoh, jika Anda sering mengambil nama pengguna bersamaan dengan riwayat pesanan mereka, menyimpan nama pengguna secara langsung di tabel pesanan menghemat waktu join.
2. Tampilan yang Dibuat
Tampilan yang dibuat menyimpan hasil dari suatu query secara fisik di disk. Secara esensi, ini adalah tabel yang telah dihitung sebelumnya. Ketika data berubah, tampilan harus diperbarui kembali. Ini sangat ideal untuk agregasi kompleks yang tidak memerlukan akurasi real-time.
3. Replika Baca
Pisahkan beban baca dari beban tulis. Arahkan semua operasi tulis ke database utama, yang tetap dinormalisasi. Arahkan semua operasi baca ke replika. Ini memungkinkan replika dioptimalkan secara berbeda, mungkin dengan indeks lebih banyak atau struktur yang tidak dinormalisasi, tanpa memengaruhi integritas transaksional.
4. Strategi Indeks
Bahkan basis data yang telah dinormalisasi dapat berkinerja baik dengan indeks yang tepat. Indeks yang mencakup memungkinkan basis data memenuhi query hanya menggunakan indeks, menghindari pencarian tabel. Indeks komposit dapat mempercepat join pada kunci asing yang umum.
Kapan saatnya melakukan denormalisasi 📉
Denormalisasi adalah keputusan yang disengaja, bukan keadaan bawaan. Keputusan ini harus didasarkan pada bukti dari pemantauan kinerja, bukan asumsi.
|
Skenario |
Pendekatan |
Alasan |
|---|---|---|
|
Frekuensi Tulis Tinggi |
Pertahankan Normalisasi |
Pembaruan lebih cepat. Lebih sedikit redundansi yang perlu dipertahankan. |
|
Frekuensi Baca Tinggi |
Pertimbangkan Denormalisasi |
Mengurangi join. Waktu pengambilan data lebih cepat. |
|
Konsistensi Data Sangat Penting |
Pertahankan Normalisasi |
Sumber kebenaran tunggal mencegah pergeseran data. |
|
Pelaporan & Analitik |
Denormalisasi |
Agregasi kompleks; perhitungan awal membantu. |
|
Kebutuhan Skalabilitas |
Pendekatan Hibrida |
Pisahkan layanan atau gunakan lapisan penyimpanan sementara. |
Kompromi: Integritas Data vs Kecepatan ⚙️
Setiap kali Anda memperkenalkan redundansi, Anda berisiko terhadap ketidakkonsistenan data. Jika pengguna mengubah alamat email mereka, tetapi email disimpan di kedua tempat, Pengguna meja dan Pemberitahuan tabel, satu pembaruan bisa gagal atau terlewatkan. Ini dikenal sebagai anomali pembaruan.
Untuk mengurangi hal ini, logika aplikasi harus kuat. Triger dapat memastikan konsistensi, tetapi menambah kompleksitas. Sebagai alternatif, rancang skema sedemikian rupa sehingga data yang tidak dinormalisasi berasal dari sumber yang tidak dapat diubah, mengurangi risiko perbedaan.
Menangani Konsistensi
-
Logika Tingkat Aplikasi: Tulis kode yang memperbarui semua salinan yang berulang secara atomik.
-
Triger Basis Data: Biarkan basis data menerapkan aturan secara otomatis. Ini menjaga logika dekat dengan data.
-
Konsistensi Akhir: Terima bahwa data mungkin menjadi usang dalam periode singkat. Gunakan pekerjaan latar belakang untuk menyinkronkan data yang berulang.
Pemantauan dan Pemeliharaan 🔧
Desain statis tidak mempertimbangkan pola penggunaan yang berubah. Apa yang berfungsi hari ini bisa menjadi hambatan tahun depan. Pemantauan berkelanjutan sangat penting.
Metrik Kunci yang Harus Dipantau
-
Latensi Kueri: Pantau waktu yang dibutuhkan untuk kueri baca kritis.
-
Jumlah Gabungan: Lacak jumlah gabungan per kueri kompleks.
-
Rasio Kenaikan Cache: Jika Anda menggunakan caching, periksa apakah itu secara efektif mengurangi beban basis data.
-
Latensi Tulis: Pastikan bahwa denormalisasi tidak terlalu memperlambat penulisan.
Kesimpulan: Keputusan yang Kontekstual 🎯
Tidak ada standar universal untuk desain basis data. Diagram ER terbaik adalah yang sesuai dengan beban kerja spesifik Anda. Normalisasi memberikan keamanan; denormalisasi memberikan kecepatan. Tujuannya adalah menemukan titik keseimbangan.
Mulailah dengan desain yang dinormalisasi untuk memastikan integritas data. Saat bottleneck kinerja muncul, identifikasi kueri spesifik yang menyebabkan penundaan. Terapkan denormalisasi atau caching hanya pada area-area tersebut. Pendekatan iteratif ini mencegah optimasi terlalu dini dan memastikan sistem tetap dapat dipelihara seiring waktu.
Ingatlah bahwa teknologi terus berkembang. Mesin penyimpanan baru dan optimisasi kueri terus mengurangi biaya gabungan. Tinjau ulang skema Anda secara rutin terhadap kemampuan saat ini. Keseimbangan berubah, dan desain Anda harus berubah bersamanya.
Dengan memahami mekanisme normalisasi dan kenyataan kinerja baca, Anda dapat membangun sistem yang tangguh dan responsif. Fokus pada data, bukan hanya pada kode.