











Database relasional dibangun di atas fondasi tabel dan baris, struktur yang dirancang untuk data datar. Namun dunia nyata jarang mengikuti kesederhanaan seperti itu. Organisasi, sistem file, percakapan komentar, dan pohon kategori semuanya ada dalam struktur hierarkis. Mewakili hubungan induk-anak ini dalam Diagram Hubungan Entitas (ERD) standar membutuhkan pola desain khusus yang menjaga integritas data sekaligus memungkinkan pengambilan data yang efisien.
Ketika Anda mencoba memetakan struktur pohon ke dalam skema datar, Anda akan menghadapi ketegangan klasik antara normalisasi dan kinerja. Panduan ini mengeksplorasi teknik inti untuk memodelkan data hierarkis, mengevaluasi pertukaran masing-masing pendekatan agar membantu Anda merancang sistem yang tangguh.
🧩 Tantangan Skema Datar
Diagram Hubungan Entitas biasanya memvisualisasikan entitas sebagai kotak dan hubungan sebagai garis. Dalam hubungan standar, satu tabel terhubung ke tabel lain melalui Foreign Key. Ini berjalan sempurna untuk skenario banyak-ke-banyak atau satu-ke-banyak di mana arahnya tetap. Tapi apa yang terjadi ketika kategori dapat memiliki sub-kategori, yang dapat memiliki sub-sub-kategori, bahkan secara potensial tak terbatas?
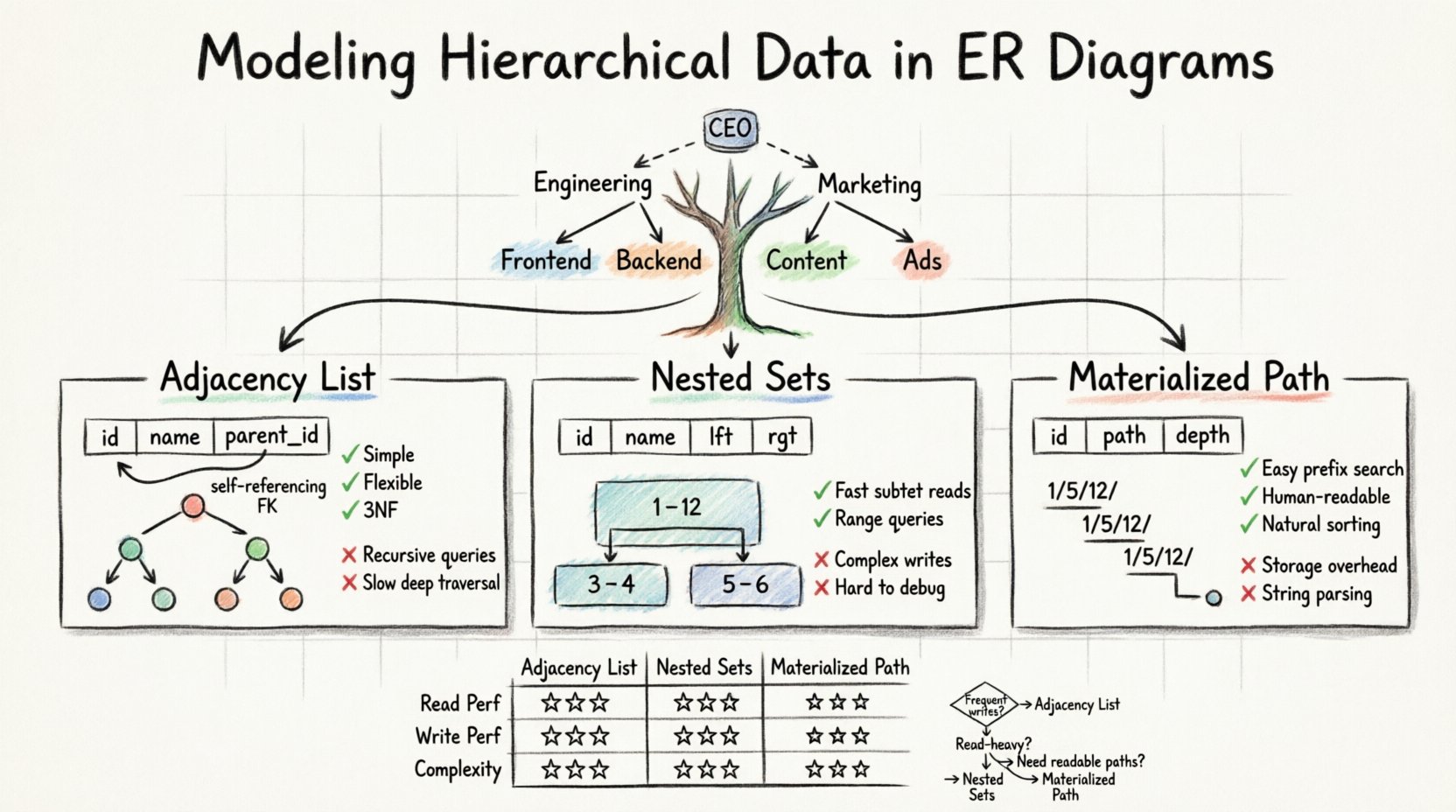
Model relasional standar kesulitan menghadapi kedalaman yang bervariasi. Tabel datar tidak dapat dengan mudah menyimpan jalur dengan panjang sembarang. Untuk menyelesaikannya, kita harus menyesuaikan skema agar menyimpan hierarki secara eksplisit. Ada tiga pola utama yang digunakan arsitek data untuk mencapai hal ini:
- Daftar Ketetanggaan: Menyimpan ID induk dalam catatan anak.
- Set Bersarang: Menetapkan nilai kiri dan kanan untuk menentukan rentang.
- Enumerasi Jalur: Menyimpan jalur lengkap dari akar hingga simpul saat ini.
🔗 Model Daftar Ketetanggaan
Daftar Ketetanggaan adalah metode paling umum dan langsung untuk merepresentasikan hierarki dalam ERD standar. Ini bergantung pada hubungan yang merujuk pada dirinya sendiri. Artinya, satu tabel berisi kolom yang merujuk pada kunci utama sendiri.
📐 Struktur Skema
Dalam model ini, Anda membuat satu tabel untuk menyimpan data. Setiap baris mewakili simpul dalam pohon. Penambahan krusial adalah kolom, sering dinamai parent_id atau ancestor_id, yang menyimpan pengenal unik dari simpul induk. Jika suatu simpul berada di puncak hierarki, kolom ini berisi nilai null.
Pertimbangkan sebuah tabel untuk Departemen:
- id: Kunci utama unik untuk departemen.
- nama: Nama tampilan departemen.
- parent_id: ID departemen yang lebih tinggi (boleh kosong untuk tingkat atas).
✅ Kelebihan
- Kesederhanaan: Skema ini intuitif dan mudah dipahami oleh pengembang dan administrator basis data.
- Kelenturan:Memindahkan subpohon menjadi sederhana; Anda hanya perlu memperbarui
parent_iddari simpul akar subpohon tersebut. - Normalisasi: Ini sesuai dengan Bentuk Normal Ketiga (3NF) karena data tidak diulang.
❌ Kekurangan
- Kompleksitas Query: Mengambil semua keturunan membutuhkan query rekursif atau pemrosesan di sisi aplikasi.
- Kinerja: Penelusuran mendalam bisa lambat tanpa strategi penindeksan khusus atau ekspresi tabel umum rekursif (CTEs).
- Integritas Referensial: Meskipun kunci asing membantu, referensi melingkar masih bisa terjadi jika batasan tidak diterapkan secara ketat.
🌲 Model Set Bersarang
Model Set Bersarang mengubah struktur pohon menjadi kumpulan interval. Alih-alih melacak penunjuk induk, setiap simpul diberi dua angka: kiri dan kanan. Nilai-nilai ini mewakili posisi simpul dalam penelusuran pre-order pohon.
📐 Struktur Skema
Bayangkan sebuah pohon di mana simpul akar adalah keseluruhan himpunan. Saat Anda menelusuri pohon, Anda menambahkan penghitung. Ketika Anda memasuki sebuah simpul, Anda mencatat jumlah saat ini sebagai kiri. Ketika Anda menyelesaikan pemrosesan simpul tersebut dan semua anaknya, Anda mencatat jumlah sebagai kanan. The kanan nilai selalu lebih besar dari kiri nilai.
Sebuah Kategoritabel akan terlihat seperti ini:
- id: Penanda unik.
- nama: Nama Kategori.
- kiri: Nilai batas kiri.
- kanan: Nilai batas kanan.
✅ Kelebihan
- Pengambilan Cepat:Mengambil subpohon adalah query rentang sederhana menggunakan
BETWEENlogika. - Efisiensi:Kinerja baca lebih unggul untuk pohon besar dan dalam dibandingkan dengan daftar tetangga.
❌ Kekurangan
- Biaya Tulis:Menyisipkan atau memindahkan simpul sangat mahal. Anda harus memperbarui
kiridankanannilai dari banyak simpul lain untuk menjaga integritas interval. - Kompleksitas: Logikanya sulit diimplementasikan dan didebug tanpa dukungan perpustakaan khusus.
🛣️ Enumerasi Jalur dan Jalur yang Dibuat
Metode enumerasi jalur menyimpan garis keturunan suatu simpul sebagai string atau daftar terpisah. Pendekatan ini sering disebut pola Jalur yang Dibuat. Ini menggabungkan kesederhanaan daftar ketetanggaan dengan kemudahan bacaan jalur.
📐 Struktur Skema
Dalam model ini, setiap catatan menyimpan jalur lengkap dari akar. Sebagai contoh, dalam model sistem file, sebuah file mungkin memiliki string jalur seperti/home/user/documents/report.txt. Dalam basis data, ini sering disimpan sebagai string terpisah dalam kolom, seperti1/5/12/.
Tabel mencakup:
- id: Kunci utama.
- jalur: String yang mewakili garis keturunan.
- kedalaman: Bilangan bulat yang menunjukkan seberapa dalam simpul tersebut dalam hierarki.
✅ Kelebihan
- Penelusuran Mudah: Anda dapat menemukan semua keturunan dengan mencocokkan awalan jalur.
- Kemudahan Bacaan: Data ini mudah dibaca manusia dan mudah didebug.
- Pengurutan: Pengurutan berdasarkan string jalur sering menghasilkan urutan pohon yang benar secara alami.
❌ Kekurangan
- Beban Penyimpanan: Jalur panjang dapat menghabiskan ruang penyimpanan yang signifikan.
- Pemrosesan String: Query sering membutuhkan fungsi manipulasi string, yang bisa lebih lambat dibandingkan perbandingan bilangan bulat.
📊 Analisis Perbandingan
Memilih model yang tepat sangat tergantung pada rasio baca-terhadap-tulis Anda dan kedalaman hierarki Anda. Tabel berikut menjelaskan karakteristik masing-masing metode.
| Fitur | Daftar Ketetanggaan | Himpunan Bersarang | Jalur yang Dibuat Nyata |
|---|---|---|---|
| Kinerja Baca | Rendah hingga Sedang | Tinggi | Sedang hingga Tinggi |
| Kinerja Tulis | Tinggi | Rendah | Sedang |
| Kompleksitas Implementasi | Rendah | Tinggi | Sedang |
| Mendukung Pohon Dalam | Ya | Ya | Ya (dengan batasan) |
| Logika Kueri | Rekursif | Pemindaian Rentang | Cocokan Awalan |
⚙️ Pertimbangan Kinerja
Saat memodelkan hierarki, Anda harus mempertimbangkan bagaimana mesin basis data menangani data. Strategi indeksing memainkan peran penting terlepas dari model yang dipilih.
- Daftar Ketetanggaan: Indeks kolom
parent_idkolom secara berat. Ini memungkinkan basis data untuk dengan cepat menemukan semua anak dari suatu simpul tertentu tanpa harus memindai seluruh tabel. - Himpunan Bersarang: Indeks keduanya
kiridankanan. Indeks komposit dapat secara signifikan mengoptimalkan kueri rentang. - Jalur yang Dibuat Nyata: Indeks kolom
jalurkolom. Tergantung pada basis data, indeks awalan mungkin bermanfaat untuk menyaring sub-pohon.
🛠️ Pemeliharaan dan Pembaruan
Model data tidak bersifat statis. Seiring pertumbuhan organisasi Anda, hierarki Anda akan berubah. Memindahkan suatu simpul dari satu cabang ke cabang lain merupakan operasi umum yang berdampak berbeda pada setiap model.
🔄 Memindahkan Simpul
Dalam model Daftar Tetangga, memindahkan simpul adalah satu pernyataan pembaruan. Anda mengubah parent_id dari akar subpohon. Namun, Anda harus memastikan tidak terjadi referensi melingkar.
Dalam model Set Bersarang model, memindahkan simpul bersifat kompleks. Ini melibatkan perhitungan ulang nilai kiri dan kanan untuk semua simpul di subpohon tujuan agar ada ruang bagi simpul yang dipindahkan. Ini sering merupakan operasi transaksional yang melibatkan pembaruan beberapa tabel.
Dalam model Jalur yang Dibuat Nyata model, Anda memperbarui string jalur dari simpul yang dipindahkan dan semua keturunannya. Ini memerlukan pembaruan jalur untuk setiap anak, yang dapat menjadi operasi tulis berat untuk pohon besar.
🎯 Praktik Terbaik untuk Pemodelan Data
Untuk memastikan ERD Anda tetap dapat dipelihara dan berkinerja baik, ikuti panduan ini saat menerapkan struktur hierarkis.
- Gunakan Konvensi Penamaan yang Jelas: Hindari nama umum seperti
kolom1. Gunakanparent_id,ancestor_id,lft, ataurgtsecara eksplisit. - Terapkan Keterbatasan: Gunakan keterbatasan basis data untuk mencegah referensi melingkar. Sebuah simpul tidak dapat menjadi nenek moyangnya sendiri.
- Batasi Kedalaman: Meskipun secara teknis mungkin, hierarki yang sangat dalam (misalnya, lebih dari 10 tingkat) sering menunjukkan kelemahan desain. Pertimbangkan untuk meratakan struktur jika memungkinkan.
- Dokumentasikan Pilihan: Karena pola-pola ini bukan fitur SQL standar, dokumentasikan pola mana yang digunakan dalam dokumentasi skema.
- Pertimbangkan Pendekatan Hibrida: Beberapa sistem menggabungkan Daftar Tetangga dengan Jalur yang Dibuat untuk menyeimbangkan kinerja baca dan tulis.
🧠 Memilih Strategi yang Tepat
Tidak ada jawaban ‘benar’ tunggal untuk setiap skenario. Keputusan tergantung pada kebutuhan khusus aplikasi Anda.
- Pilih Daftar Tetangga jika: Data Anda sering berubah, dan kedalaman hierarki moderat. Ini adalah default yang paling aman untuk sebagian besar aplikasi umum.
- Pilih Set Bersarang jika: Anda memiliki aplikasi yang berat membaca di mana data jarang dipindahkan, dan Anda perlu mengambil subpohon besar dengan cepat.
- Pilih Jalur yang Dibuat jika: Anda membutuhkan jalur yang dapat dibaca manusia (seperti URL) dan kedalaman hierarki relatif dangkal.
Memahami nuansa struktural ini memungkinkan Anda merancang basis data yang dapat diskalakan. Dengan memilih pola yang tepat untuk Diagram Hubungan Entitas Anda, Anda memastikan bahwa data Anda tetap konsisten, dapat diakses, dan efisien sepanjang siklus hidup sistem.