As data accumulation accelerates, the architecture of your database schema becomes a critical determinant of system stability. When an application shifts from read-heavy operations to write-heavy workloads, the standard Entity Relationship Diagram (ERD) often requires significant adjustment. Designing for high throughput involves more than just adding indexes; it demands a fundamental rethinking of how data is structured, linked, and stored. This guide explores the necessary architectural shifts required to sustain performance under pressure without compromising data integrity.
Understanding Write-Heavy Workloads 📈
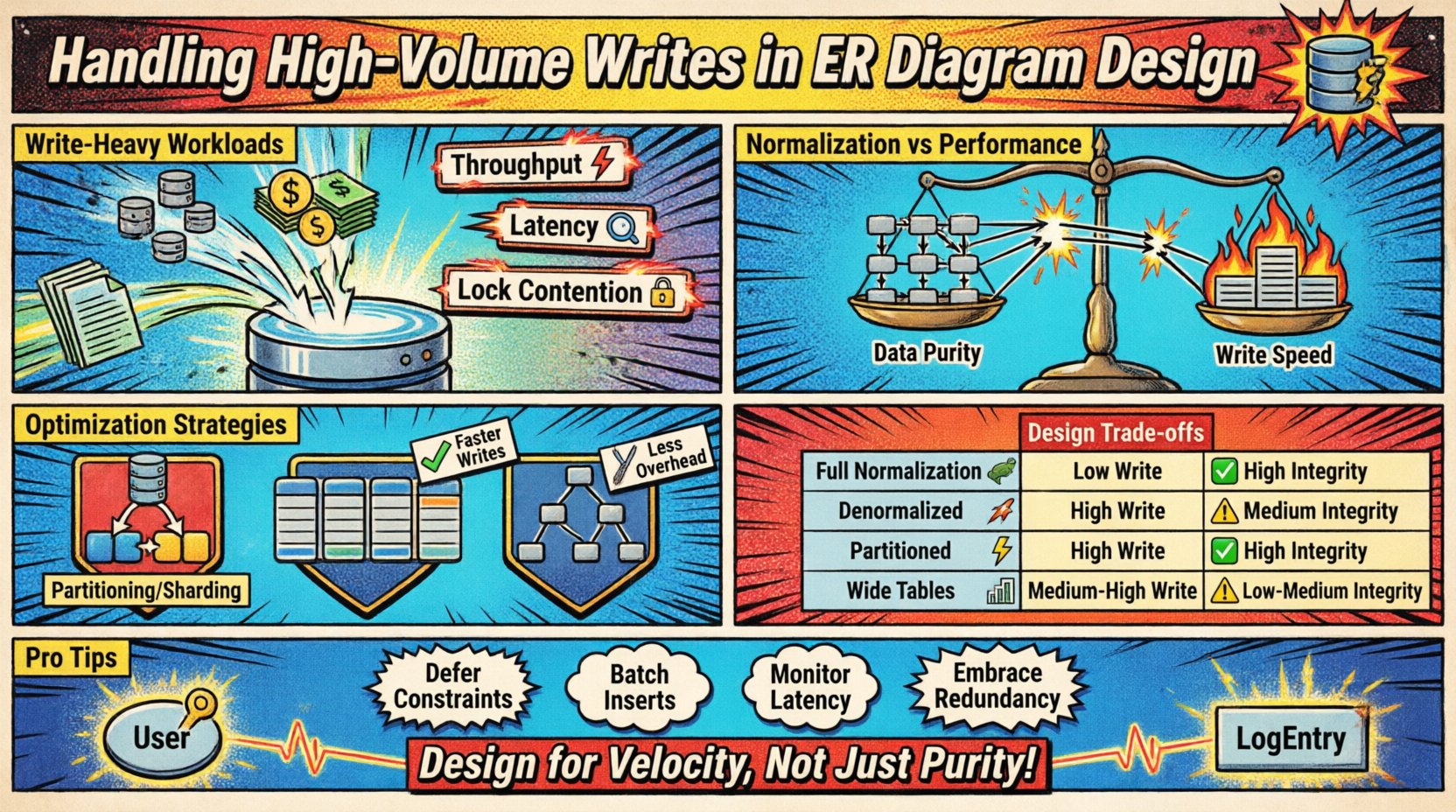
High-volume write scenarios occur when the rate of incoming data exceeds the capacity of standard normalization techniques. This often happens in logging systems, IoT sensor feeds, financial transaction ledgers, or real-time analytics platforms. The primary challenge lies in balancing the speed of insertion against the consistency requirements of the model.
- Throughput: The number of write operations processed per second.
- Latency: The time taken to persist a record successfully.
- Lock Contention: Competition for resources when multiple processes attempt to modify the same data.
When these metrics degrade, the schema itself is often the bottleneck. A rigid design optimized for complex queries may crumble under the weight of constant updates. Therefore, the initial ERD must account for the velocity of data entry.
Normalization vs. Performance Trade-offs ⚖️
Traditional database design encourages normalization (1NF, 2NF, 3NF) to reduce redundancy. While this saves storage space and ensures consistency, it introduces overhead during write operations. Every foreign key relationship requires a lookup and a join check to maintain referential integrity.
In a high-volume environment, these checks become expensive. Consider the implications of a many-to-many relationship during a write event:
- The primary table must update.
- The junction table must insert a new row.
- The second table must verify the relationship.
- Transaction logs must record all changes.
Each step adds disk I/O and CPU cycles. To handle heavy write loads, designers often relax normalization rules. This process involves accepting data redundancy to reduce the number of write operations required to store a single unit of information.
Strategies for Optimizing Write Speed ✍️
Several structural patterns exist to mitigate write pressure. These strategies focus on minimizing the footprint of each transaction and reducing the complexity of the storage engine’s work.
1. Partitioning and Sharding
Splitting a large table into smaller, more manageable chunks allows the database to distribute the write load across multiple physical or logical segments.
- Horizontal Partitioning: Dividing rows based on a key (e.g., date ranges, user IDs).
- Vertical Partitioning: Moving infrequently accessed columns to separate tables.
- Sharding: Distributing data across multiple database instances.
This approach reduces the size of indexes that must be maintained and limits the scope of locks during a write operation. If one shard becomes saturated, others remain unaffected.
2. Denormalization Tactics
Storing redundant data allows the system to avoid joins during writes. For example, instead of calculating a total sum from related rows every time a new transaction arrives, the system can update a pre-calculated summary column directly.
- Computed Columns: Store derived values directly in the row.
- Materialized Views: Pre-calculate results for frequent aggregations.
- Cached Counters: Maintain a separate counter table for statistics.
While this increases storage requirements, it significantly lowers the CPU cost of insertion.
3. Indexing Strategy
Indexes speed up reads but slow down writes. Every time a row is inserted, the database must update every associated index. In high-write environments, index bloat becomes a major issue.
- Minimize Index Count: Only index columns used for filtering or joining.
- Partial Indexes: Index only a subset of rows that are frequently accessed.
- Avoid Over-Indexing: Skip indexes on columns that change frequently.
Comparing Design Approaches 📑
The table below outlines the impact of different structural choices on write performance and data integrity.
| Strategy | Write Performance | Data Integrity | Storage Cost | Best Use Case |
|---|---|---|---|---|
| Full Normalization | Low | High | Low | Complex reporting, low write volume |
| Denormalized | High | Medium | High | Real-time feeds, high write volume |
| Partitioned Schema | High | High | Medium | Time-series data, large datasets |
| Wide Tables | Medium-High | Medium | Medium | NoSQL patterns, sparse data |
Handling Foreign Keys and Constraints 🔗
Referential integrity is a cornerstone of relational design, but enforcing constraints on every insert can choke a high-speed pipeline. The database engine must verify that the referenced parent row exists before accepting the child row.
In scenarios where data integrity is critical but write speed is paramount, consider the following adjustments:
- Deferred Constraints: Validate relationships at the end of a transaction rather than immediately.
- Application-Level Checks: Verify relationships in the application code before sending data to the database.
- Soft Deletes: Mark records as inactive instead of removing them to preserve referential links without deletion overhead.
Removing constraints entirely is risky, but moving validation logic can sometimes improve throughput. The decision depends on how critical immediate consistency is for your specific workflow.
Write Amplification and Storage Engines 💾
Understanding how the storage engine handles data is vital. Many engines use a Write-Ahead Log (WAL) to ensure durability. This means every write is logged before being applied to the actual data files.
Write Amplification occurs when a single logical write operation results in multiple physical writes. This is common in compaction-heavy storage engines. To manage this:
- Batch Inserts: Group multiple rows into a single transaction.
- Sequential Writes: Design schemas to favor sequential key generation over random inserts.
- Buffering: Allow a temporary buffer in the application layer to queue writes before flushing.
By aligning the ERD design with the storage engine’s strengths, you can minimize the physical effort required to persist data.
Monitoring and Iteration 🔄
A schema designed for high writes is not static. As traffic patterns shift, the design may need to evolve. Continuous monitoring of write latency and disk I/O is essential.
- Track Write Latency: Identify spikes that indicate bottlenecks.
- Monitor Lock Waits: Detect contention points where processes are blocked.
- Analyze Index Usage: Remove indexes that are never used to reduce write overhead.
Regular audits of the ERD ensure that the structure remains aligned with current operational demands. If a specific table consistently struggles with write throughput, it may be time to revisit the partitioning strategy or the normalization level.
Summary of Key Considerations 🛠️
Designing an ERD for high-volume writes requires a shift in mindset from pure data purity to system throughput. The following points summarize the essential actions:
- Audit Normalization: Ensure that every relationship adds value rather than just complexity.
- Plan for Partitioning: Structure keys to allow easy horizontal splitting.
- Limit Indexes: Keep the write path as lean as possible.
- Embrace Redundancy: Use denormalization to reduce join dependencies during insertion.
- Validate Gradually: Move constraint checking out of the critical write path where safe.
By applying these principles, you create a data model capable of sustaining growth without sacrificing performance. The goal is not to eliminate complexity, but to manage it in a way that supports the velocity of your application.