Database design is an exercise in balance. It requires structuring data to reflect real-world relationships while maintaining performance and integrity. A common pitfall in this process is the introduction of circular dependencies within Entity Relationship Diagrams (ERDs). These loops occur when a chain of foreign key relationships eventually points back to the originating entity. While seemingly logical in isolation, such structures create significant challenges for data management, query optimization, and system stability.
Resolving these issues requires a deep understanding of relational theory and careful architectural planning. This guide explores the mechanics of circular dependencies, their impact on database health, and proven strategies to refactor schemas for optimal performance.
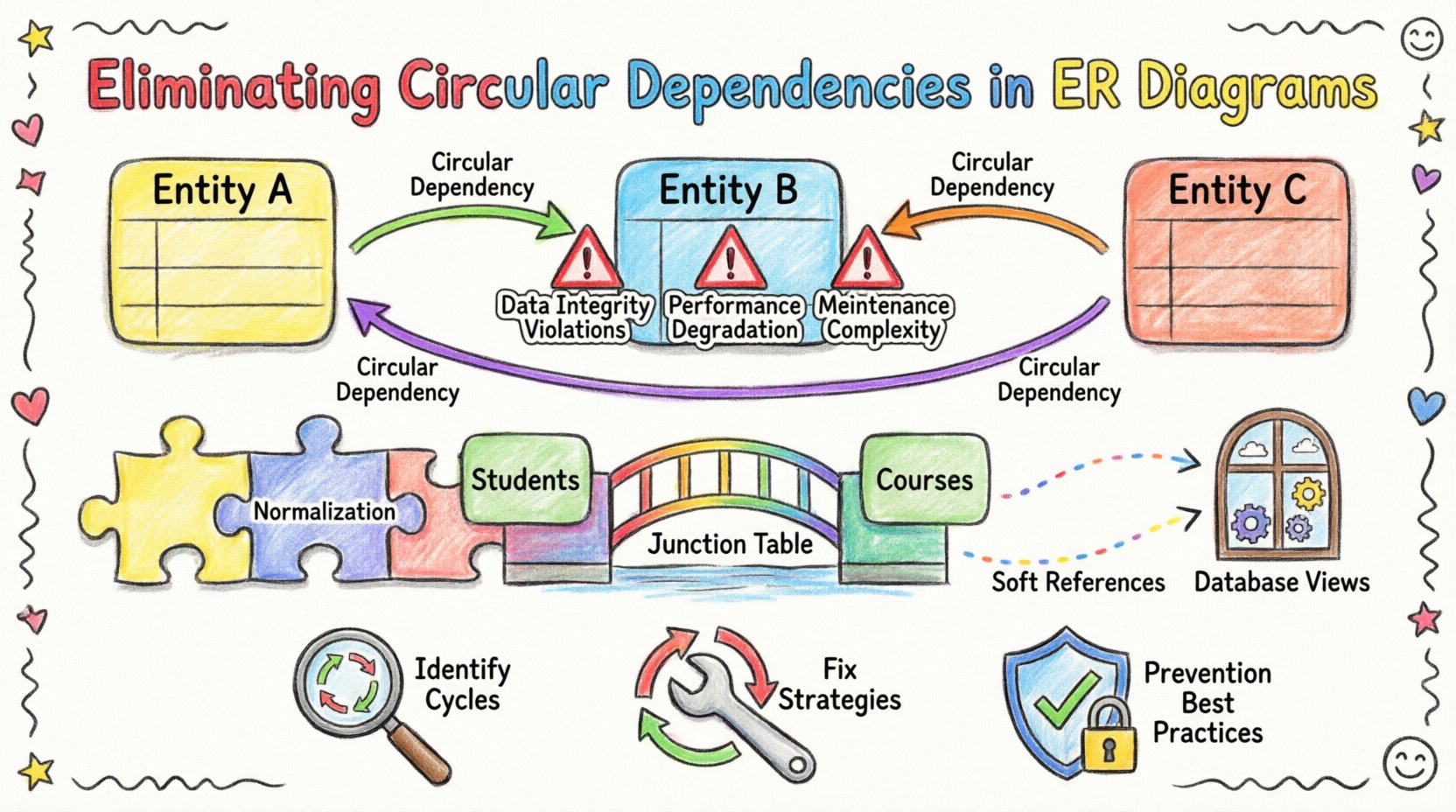
🧩 Understanding Circular Dependencies in ERDs
In a standard relational model, a foreign key constraint establishes a link from a child table to a parent table. This link enforces referential integrity, ensuring that data in the child table corresponds to valid entries in the parent table. A circular dependency arises when this chain does not terminate cleanly. Instead, Entity A references Entity B, which references Entity C, which eventually references Entity A.
Consider a scenario involving a hierarchical structure. If every node in a tree needs to know its parent and its children, bidirectional relationships can easily form loops. Without careful handling, the database engine cannot resolve the order of operations during data insertion or deletion.
Types of Circular References
- Direct Cycles: Entity A has a foreign key to Entity B, and Entity B has a foreign key back to Entity A. This is often seen in bidirectional relationships where both sides track the other.
- Indirect Cycles: A chain of three or more entities loops back. For example, A → B → C → A. These are harder to spot visually in complex schemas.
- Self-Referential Loops: An entity references itself. While common in hierarchical data (like an employee table where a manager is also an employee), improper implementation can lead to infinite recursion.
⚠️ The Impact of Unresolved Loops
Leaving circular dependencies unresolved is not merely a theoretical concern. It introduces tangible risks to the application layer and the database engine itself.
1. Data Integrity Violations
When the database engine attempts to insert data into a cycle, it must determine the order of operations. If A requires B to exist, and B requires A to exist, neither can be created first. This leads to constraint violations. While some database systems allow deferred constraint checking, relying on this feature often obscures logic errors.
2. Performance Degradation
Queries that traverse circular paths can become inefficient. Join operations in a cycle may cause the optimizer to select suboptimal execution plans. In worst-case scenarios, recursive queries intended to traverse a hierarchy can enter infinite loops, consuming CPU and memory resources until the connection is terminated.
3. Maintenance Complexity
Modifying a schema with circular dependencies is risky. Dropping a table in a cycle can fail if foreign keys are active. Cascading delete operations can trigger unexpected chain reactions. Developers often find themselves writing application-level logic to bypass database constraints, which shifts the burden of integrity away from the source of truth.
🔍 Identifying Circular Dependencies
Before fixing the problem, you must locate it. In small diagrams, visual inspection suffices. In enterprise-grade systems with hundreds of tables, manual tracing is prone to error. Use the following techniques to audit your schema.
- Graph Analysis: Treat the ERD as a directed graph. Nodes represent tables, and edges represent foreign keys. A cycle exists if a path leads back to the starting node.
- Dependency Trees: Generate a dependency tree for each table. If a table appears as its own ancestor in the tree, a cycle exists.
- Querying System Tables: Most database management systems store foreign key metadata in system catalogs. Write queries to traverse these relationships programmatically.
🛠️ Strategies for Resolution
Once identified, circular dependencies must be broken. The goal is to preserve the logical relationship without creating a physical loop. Below are the primary methods for achieving this.
1. Normalize the Schema
Normalization is the process of organizing data to reduce redundancy and improve integrity. Often, circular dependencies stem from an attempt to model relationships that do not belong in a single level of abstraction.
- Third Normal Form (3NF): Ensure that non-key attributes depend only on the primary key. If a table contains a foreign key to itself to represent a hierarchy, consider separating the hierarchy logic into a distinct relationship table.
- Remove Redundancy: If Entity A and Entity B both reference each other, ask if one of those references is redundant. Can the relationship be represented in only one direction?
2. Introduce a Junction Table
Many-to-many relationships are a frequent source of circular loops. Instead of placing foreign keys directly in the primary entities, use an intermediate table.
For example, if Students and Courses have a many-to-many relationship, do not add a course_id to the Students table and a student_id to the Courses table. Instead, create a Enrollments table that holds both IDs. This breaks the direct link between the two main entities.
3. Use Views for Logical Relationships
Sometimes, the physical storage does not need to mirror the logical requirement. If the application needs to see a relationship between A and B, but storing it directly creates a cycle, use a database view.
- Physical Model: Store A and B without a direct foreign key link.
- Logical Model: Create a view that joins A and B based on a common attribute or a separate relationship table.
This decouples the storage constraints from the application logic, allowing the database to enforce integrity where it matters without creating physical loops.
4. Implement Soft References
In some cases, strict referential integrity is not required for the relationship. You can store the ID of the related entity as a plain integer column rather than a foreign key constraint.
- Pros: Removes the constraint check during insert/delete, allowing the loop to exist physically without blocking operations.
- Cons: The database no longer enforces the relationship. Application logic must validate that the referenced ID exists.
📊 Comparison of Refactoring Approaches
| Approach | Complexity | Integrity Enforcement | Best Use Case |
|---|---|---|---|
| Normalization | High | Full | When data redundancy is the root cause. |
| Junction Table | Medium | Full | Many-to-Many relationships. |
| Views | Low | Partial (Query level) | Reporting or read-heavy workloads. |
| Soft References | Low | None (Application level) | Legacy systems or optional relationships. |
🛡️ Prevention and Best Practices
Once a schema is refactored, the focus shifts to preventing future cycles. Design patterns and governance processes can mitigate the risk of re-introducing these issues.
1. Define Relationship Direction
Establish a rule that foreign keys should always flow in a specific direction. For instance, child tables always reference parents, never the reverse. If a parent needs to access child data, use a query or a view rather than a foreign key.
2. Model Hierarchies Carefully
Self-referencing tables are common for organizational charts or comment threads. To prevent loops:
- Parent Only: Store only the
parent_id. Do not storechildren_idsin the same row. - Path Enumeration: For deep hierarchies, store the full path string (e.g.,
/1/5/9/) to allow fast querying without recursive joins.
3. Automated Schema Audits
Integrate cycle detection into the CI/CD pipeline. Scripts can parse the schema definition files (such as SQL migration scripts) and flag any new foreign key definitions that create a loop before deployment.
4. Documentation
Maintain an up-to-date ERD. When a developer adds a table, they should update the diagram. This visual aid helps identify potential cycles before code is written. Tools that auto-generate documentation from the database schema are highly recommended for large teams.
🔄 Handling Legacy Systems
Refactoring a production database is not always feasible due to downtime costs or data volume. In these cases, a phased approach is necessary.
- Identify Critical Paths: Prioritize breaking cycles that impact the most frequently accessed queries.
- Use Application Logic: Move the relationship handling to the application layer temporarily. Store IDs as plain columns and validate them in the code.
- Plan Migration: Schedule a maintenance window to convert the application-level references to physical constraints once the new structure is stable.
📝 Final Considerations for Schema Health
A clean ERD is the foundation of a robust application. Circular dependencies are a symptom of a design that prioritized convenience over structure. By adhering to normalization principles and utilizing junction tables where appropriate, you can ensure your data remains consistent and queryable.
Remember that database design is iterative. As business requirements evolve, relationships change. Regularly review your schema to ensure it still aligns with your goals. Continuous validation and a disciplined approach to foreign keys will keep your architecture resilient against the complexity of growing data needs.